Spark SQL là một thành phần quan trọng của Apache Spark, cung cấp một cách tiếp cận linh hoạt và hiệu quả để thực hiện các truy vấn và biến đổi dữ liệu bằng ngôn ngữ SQL trên dữ liệu phân tán trong Spark.
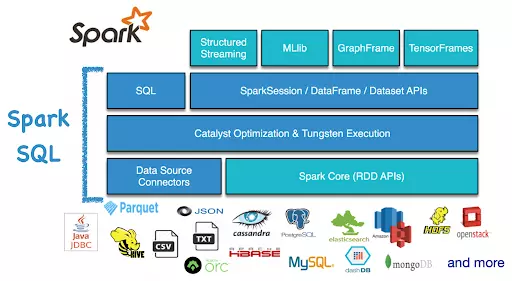
Dưới đây là một số điểm quan trọng cần hiểu rõ về Spark SQL:
1. SQL-like Interface:
Spark SQL cho phép bạn sử dụng ngôn ngữ SQL để truy vấn và biến đổi dữ liệu, giống như bạn làm việc với một cơ sở dữ liệu quan hệ truyền thống. Điều này làm cho việc làm quen và sử dụng Spark SQL trở nên dễ dàng đối với những người đã quen với SQL.
Dưới đây là một ví dụ cụ thể về cách sử dụng Spark SQL để thực hiện các truy vấn và biến đổi dữ liệu bằng ngôn ngữ SQL:
Giả sử chúng ta có một tập dữ liệu về các giao dịch mua sắm trong một cửa hàng bán lẻ, và chúng ta muốn thực hiện một số truy vấn đơn giản để hiểu rõ hơn về dữ liệu này.
- Nạp dữ liệu và tạo bảng tạm thời:
Trước tiên, chúng ta nạp dữ liệu từ tệp CSV vào một DataFrame và sau đó tạo một bảng tạm thời từ DataFrame này.
from pyspark.sql import SparkSession # Khởi tạo SparkSession
spark = SparkSession.builder \ .appName("Retail Analysis") \ .getOrCreate() # Nạp dữ liệu từ tệp CSV vào DataFrame
df = spark.read.csv("path/to/retail_data.csv", header=True, inferSchema=True) # Tạo view tạm thời từ DataFrame
df.createOrReplaceTempView("retail_data")
- Thực hiện truy vấn SQL:
Bây giờ chúng ta có thể sử dụng ngôn ngữ SQL để truy vấn dữ liệu trong bảng tạm thời đã tạo.
- Lấy ra 10 giao dịch mua hàng đầu tiên:
top_10_transactions = spark.sql("SELECT * FROM retail_data LIMIT 10")
top_10_transactions.show()
- Tính tổng doanh số bán hàng theo sản phẩm:
sales_by_product = spark.sql(""" SELECT product_id, SUM(sales_amount) AS total_sales FROM retail_data GROUP BY product_id ORDER BY total_sales DESC
""")
sales_by_product.show()
- Lấy ra các giao dịch mua hàng có giá trị lớn hơn 100:
high_value_transactions = spark.sql(""" SELECT * FROM retail_data WHERE sales_amount > 100
""")
high_value_transactions.show()
Điều quan trọng là trong mỗi truy vấn, chúng ta sử dụng ngôn ngữ SQL để chỉ định các thao tác truy vấn và biến đổi dữ liệu. Cú pháp và cách sử dụng tương tự như khi bạn làm việc với một cơ sở dữ liệu quan hệ thông thường, giúp cho việc sử dụng Spark SQL trở nên dễ dàng và tiện lợi đối với những người đã quen với SQL.
2. DataFrames Integration:
Spark SQL tích hợp chặt chẽ với DataFrames trong Apache Spark. Thực tế, mọi DataFrame trong Spark đều có một bảng tương ứng trong Spark SQL, và bạn có thể sử dụng các phương thức DataFrame cũng như SQL để truy vấn dữ liệu.
Dưới đây là một ví dụ cụ thể về cách DataFrames tích hợp với Spark SQL trong Apache Spark:
Giả sử bạn có một tập dữ liệu chứa thông tin về khách hàng và giao dịch mua hàng, và bạn muốn tính tổng doanh số bán hàng của mỗi khách hàng bằng cách sử dụng cả DataFrames và Spark SQL.
Đầu tiên, bạn cần nạp dữ liệu từ tệp CSV hoặc từ một nguồn dữ liệu khác vào DataFrame:
from pyspark.sql import SparkSession # Khởi tạo SparkSession
spark = SparkSession.builder \ .appName("Customer Sales Analysis") \ .getOrCreate() # Nạp dữ liệu từ tệp CSV vào DataFrame
df = spark.read.csv("path/to/customer_sales_data.csv", header=True, inferSchema=True)
Tiếp theo, bạn có thể sử dụng DataFrames để thực hiện các biến đổi trên dữ liệu để tính tổng doanh số bán hàng của mỗi khách hàng:
from pyspark.sql.functions import sum # Biến đổi dữ liệu để tính tổng doanh số bán hàng của mỗi khách hàng
customer_sales = df.groupBy("customer_id").agg(sum("sales_amount").alias("total_sales"))
Sau đó, bạn có thể sử dụng Spark SQL để truy vấn và xem kết quả của DataFrame đã được biến đổi:
# Tạo view tạm thời từ DataFrame
customer_sales.createOrReplaceTempView("customer_sales_view") # Truy vấn thông tin tổng doanh số bán hàng của mỗi khách hàng
sales_by_customer = spark.sql(""" SELECT customer_id, total_sales FROM customer_sales_view ORDER BY total_sales DESC
""")
sales_by_customer.show()
Trong ví dụ này, chúng ta sử dụng DataFrames để tính tổng doanh số bán hàng của mỗi khách hàng và sau đó sử dụng Spark SQL để truy vấn và hiển thị kết quả. Bạn có thể thấy rằng cả DataFrames và Spark SQL được tích hợp chặt chẽ với nhau, giúp bạn thực hiện các tác vụ phức tạp trong Apache Spark một cách dễ dàng và hiệu quả hơn.
3. Dữ liệu có cấu trúc:
Spark SQL thích hợp cho việc xử lý dữ liệu có cấu trúc. Bạn có thể sử dụng Spark SQL để truy vấn và biến đổi dữ liệu trong các bảng có cấu trúc được định nghĩa trước, giúp bạn dễ dàng thực hiện các tác vụ phân tích dữ liệu và báo cáo.
Dữ liệu có cấu trúc thường là dữ liệu được tổ chức dưới dạng bảng có các cột và hàng, tương tự như trong một cơ sở dữ liệu quan hệ. Dưới đây là một ví dụ cụ thể về cách làm việc với dữ liệu có cấu trúc trong Apache Spark sử dụng Spark SQL:
Giả sử chúng ta có một tập dữ liệu về các khách hàng của một cửa hàng bán lẻ, bao gồm các thông tin như ID khách hàng, tên, tuổi và địa chỉ. Tập dữ liệu này có thể được tổ chức dưới dạng một tệp CSV như sau:
customer_id,name,age,address 1,John,30,123 Main St 2,Alice,25,456 Elm St 3,Bob,35,789 Oak St
Chúng ta có thể sử dụng Apache Spark và Spark SQL để đọc và xử lý tập dữ liệu này như sau:
from pyspark.sql import SparkSession # Khởi tạo SparkSession
spark = SparkSession.builder \ .appName("Structured Data Example") \ .getOrCreate() # Đọc dữ liệu từ tệp CSV và tạo DataFrame
df = spark.read.csv("path/to/customer_data.csv", header=True, inferSchema=True) # Hiển thị dữ liệu
df.show()
Kết quả sẽ hiển thị như sau:
+-----------+-----+---+-----------+
|customer_id| name|age| address|
+-----------+-----+---+-----------+
| 1| John| 30| 123 Main St|
| 2|Alice| 25| 456 Elm St|
| 3| Bob| 35| 789 Oak St|
+-----------+-----+---+-----------+
Sau khi đọc dữ liệu vào DataFrame, chúng ta có thể sử dụng Spark SQL để thực hiện các truy vấn và biến đổi dữ liệu. Ví dụ, để lọc ra các khách hàng có tuổi trên 30, chúng ta có thể sử dụng câu lệnh SQL như sau:
# Tạo view tạm thời từ DataFrame
df.createOrReplaceTempView("customers") # Truy vấn dữ liệu
result = spark.sql("SELECT * FROM customers WHERE age > 30")
result.show()
Kết quả sẽ là:
+-----------+----+---+-----------+
|customer_id|name|age| address|
+-----------+----+---+-----------+
| 3| Bob| 35| 789 Oak St|
+-----------+----+---+-----------+
Đây là một ví dụ cụ thể về cách làm việc với dữ liệu có cấu trúc trong Apache Spark sử dụng Spark SQL để đọc, truy vấn và biến đổi dữ liệu từ một tệp CSV.
4. Hỗ trợ nhiều định dạng dữ liệu:
Spark SQL hỗ trợ nhiều định dạng dữ liệu phổ biến như JSON, CSV, Parquet, Avro và Hive. Điều này cho phép bạn đọc và ghi dữ liệu từ nhiều nguồn khác nhau và thực hiện các phương pháp phân tích dữ liệu trên chúng.
5. Tối ưu hóa hiệu suất:
Spark SQL được tối ưu hóa để tận dụng các tính năng in-memory của Apache Spark, giảm thiểu việc truy cập dữ liệu từ đĩa và tối ưu hóa việc thực thi truy vấn SQL trên dữ liệu phân tán.
6. Tích hợp với các thư viện và công cụ khác:
Spark SQL tích hợp chặt chẽ với các công cụ và thư viện khác trong hệ sinh thái Spark như MLlib, GraphX và Streaming, giúp bạn kết hợp các phương tiện phân tích dữ liệu khác nhau để thực hiện các nhiệm vụ phức tạp trong lĩnh vực Big Data.
Tóm lại, Spark SQL cung cấp một cách tiếp cận linh hoạt và hiệu quả để thực hiện các truy vấn và biến đổi dữ liệu bằng ngôn ngữ SQL trên dữ liệu phân tán trong Apache Spark. Điều này làm cho việc xử lý và phân tích dữ liệu trở nên dễ dàng và hiệu quả hơn trong lĩnh vực Big Data.