Giới Thiệu Về AWS Glue Data Catalog và AWS Athena
Trong lĩnh vực phân tích dữ liệu hiện đại, khả năng tổ chức và truy vấn dữ liệu một cách hiệu quả là yếu tố then chốt. AWS cung cấp hai dịch vụ mạnh mẽ giúp bạn đạt được điều này: Data Catalog và AWS Athena.
AWS Glue Data Catalog
AWS Glue Data Catalog là gì
Data Catalog là một kho lưu trữ metadata tập trung, được thiết kế để làm cho dữ liệu dễ dàng khám phá và sử dụng. Nó cung cấp một giao diện truy vấn đồng nhất cho tất cả các tài sản dữ liệu và hỗ trợ việc theo dõi các phiên bản thay đổi của dữ liệu.
Lợi Ích của Data Catalog
- Khám Phá Dữ Liệu: Giúp người dùng dễ dàng tìm kiếm và khám phá các tập dữ liệu có sẵn, tiết kiệm thời gian và công sức trong việc tìm kiếm thông tin cần thiết.
- Quản Lý Phiên Bản: Theo dõi và quản lý các phiên bản thay đổi của dữ liệu, giúp duy trì tính chính xác và nhất quán của dữ liệu qua thời gian.
- Giao Diện Truy Vấn Đồng Nhất: Cung cấp một giao diện truy vấn chung cho tất cả các tài sản dữ liệu, làm cho việc truy xuất và phân tích dữ liệu trở nên dễ dàng và hiệu quả hơn.
- Tích Hợp Dữ Liệu: Tạo một kho lưu trữ metadata đồng nhất từ nhiều nguồn khác nhau, hỗ trợ việc quản lý và phân tích dữ liệu từ các hệ thống phân tán.
AWS Athena
Định Nghĩa AWS Athena
AWS Athena là một dịch vụ phân tích dữ liệu tương tác cho phép bạn chạy truy vấn SQL trực tiếp trên các tập tin lưu trữ trong Amazon S3 mà không cần phải thiết lập hay quản lý máy chủ (serverless). Athena hỗ trợ nhiều định dạng file phổ biến như CSV, JSON, Parquet, ORC, và Avro, và tính phí dựa trên khối lượng dữ liệu được quét trong mỗi truy vấn.
Lợi Ích của AWS Athena
- Truy Vấn SQL Trực Tiếp: Cho phép bạn thực hiện các truy vấn SQL trực tiếp trên dữ liệu lưu trữ trong Amazon S3, giúp phân tích dữ liệu nhanh chóng mà không cần di chuyển dữ liệu đến một cơ sở dữ liệu khác.
- Không Cần Máy Chủ: Là dịch vụ serverless, bạn không cần phải thiết lập hoặc quản lý máy chủ, giúp tiết kiệm thời gian và công sức trong việc duy trì hạ tầng.
- Chi Phí Dựa Trên Dữ Liệu Quét: Tính phí dựa trên khối lượng dữ liệu được quét, giúp tối ưu hóa chi phí và chỉ trả tiền cho những gì bạn sử dụng.
- Hỗ Trợ Định Dạng File Phổ Biến: Hỗ trợ nhiều định dạng file như CSV, JSON, Parquet, ORC, và Avro, giúp bạn dễ dàng làm việc với các dữ liệu có cấu trúc và bán cấu trúc.
Hands-on
Trong phần hướng dẫn thực hành này, chúng ta sẽ cùng khám phá cách sử dụng hai dịch vụ mạnh mẽ của AWS: AWS Glue Data Catalog và AWS Athena. Hai dịch vụ này kết hợp với nhau cung cấp một giải pháp toàn diện cho việc quản lý metadata và phân tích dữ liệu.
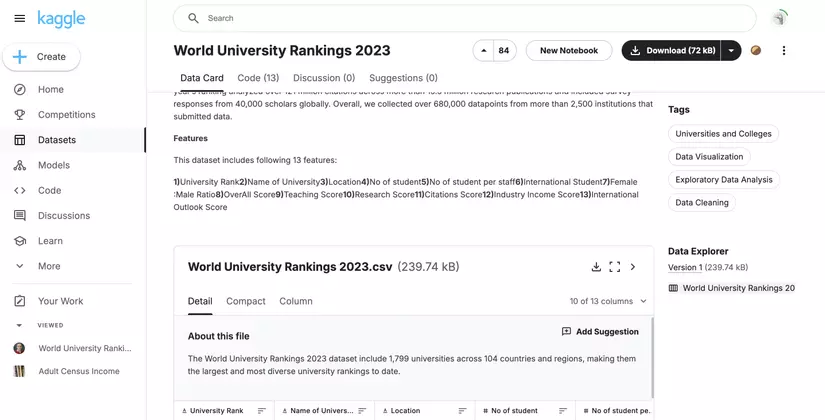
1. Tìm Dataset "World University Rankings 2023" trên Kaggle
- Mở trình duyệt web và truy cập Kaggle
- Đăng nhập vào tài khoản Kaggle của bạn hoặc đăng ký nếu bạn chưa có tài khoản.
- Sử dụng thanh tìm kiếm trên trang chính, nhập World University Rankings 2023 và nhấn Enter.
- Chọn dataset từ kết quả tìm kiếm và nhấn vào liên kết đến trang của dataset.
- Trên trang dataset, nhấn Download để tải file về máy tính của bạn. File này thường có định dạng ZIP chứa các file dữ liệu như CSV.
2. Tải File Lên Amazon S3
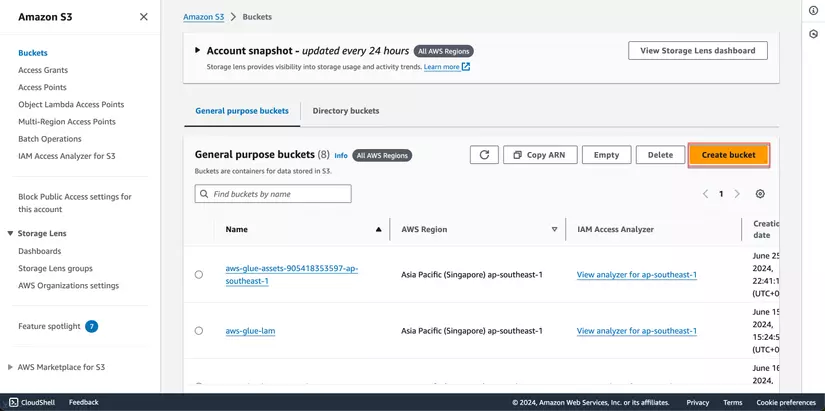
- Mở AWS Management Console và truy cập vào giao diện S3.
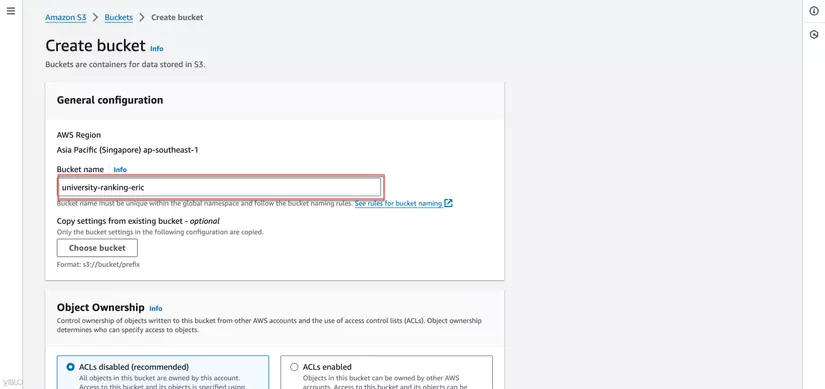
- Nhấn Create bucket để tạo một bucket mới, đặt tên và chọn vùng phù hợp, sau đó nhấn Create bucket.
- Trong danh sách các bucket, chọn bucket mà bạn muốn tải lên file.
- Nhấn Upload để mở cửa sổ tải lên.
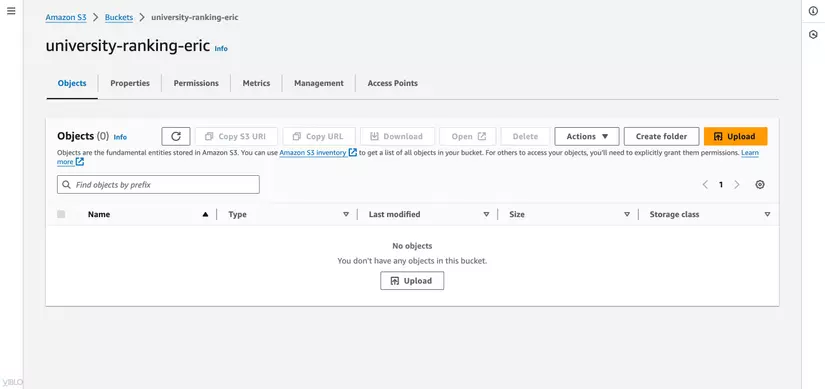
- Kéo và thả file dataset hoặc nhấn Add files để chọn file từ máy tính của bạn.
- Nhấn Upload để bắt đầu quá trình tải lên.
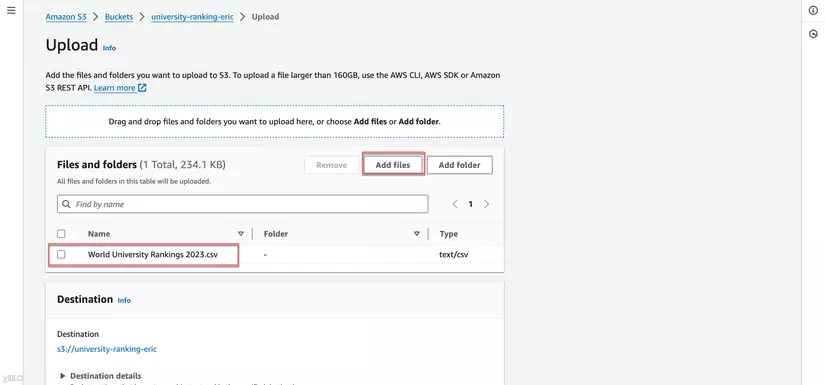
- Sau khi tải lên hoàn tất, kiểm tra danh sách các đối tượng (objects) trong bucket để xác nhận file đã được tải lên thành công.
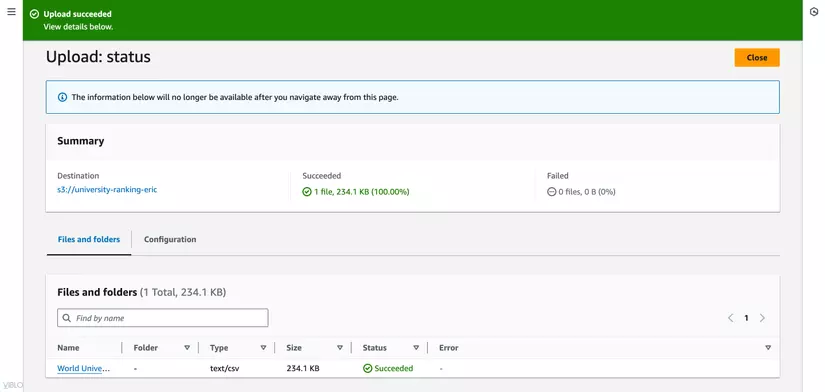
3. Tạo IAM Role cho AWS Glue
- Mở AWS Management Console và truy cập vào giao diện IAM.
- Trong thanh điều hướng bên trái, chọn Roles và nhấn Create role.
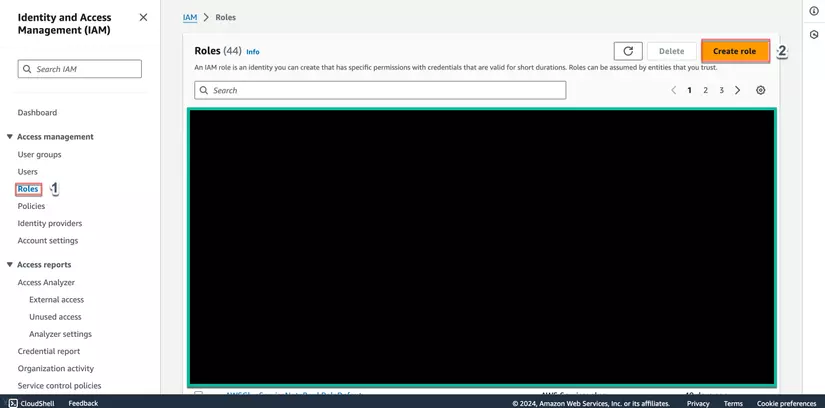
- Trong phần Select trusted entity, chọn AWS service, chọn Glue, và nhấn Next.
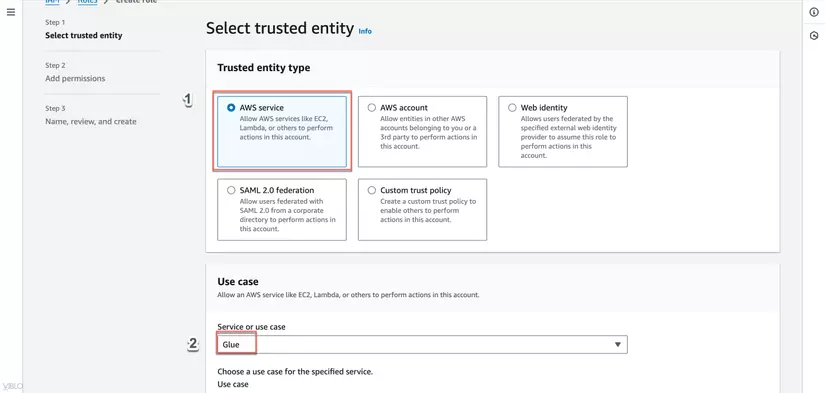
- Trong phần Attach permissions policies, tìm và chọn policy AWSGlueServiceRole và AmazonS3FullAccess, sau đó nhấn Next.
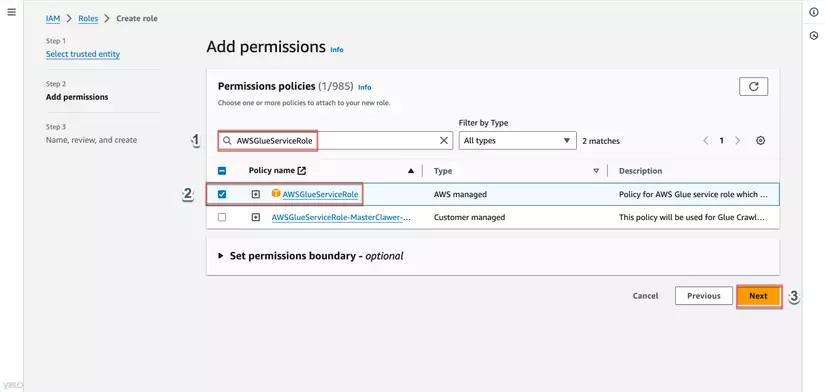
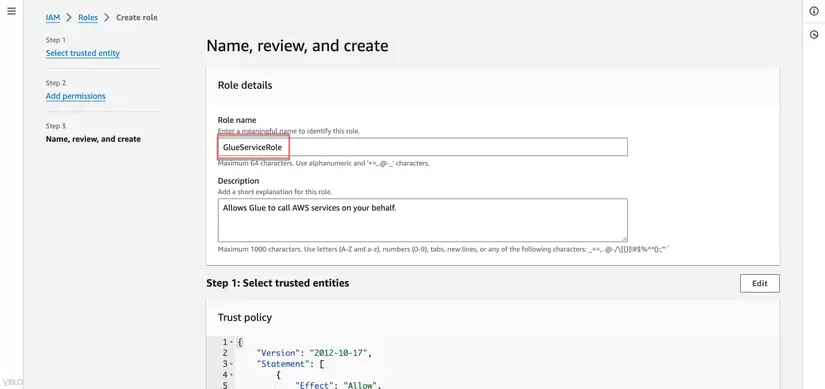
- Đặt tên cho role, ví dụ: GlueServiceRole, kiểm tra lại các thông tin và nhấn Create role.
4. Tạo Glue Crawler
- Mở AWS Management Console và truy cập vào giao diện AWS Glue.
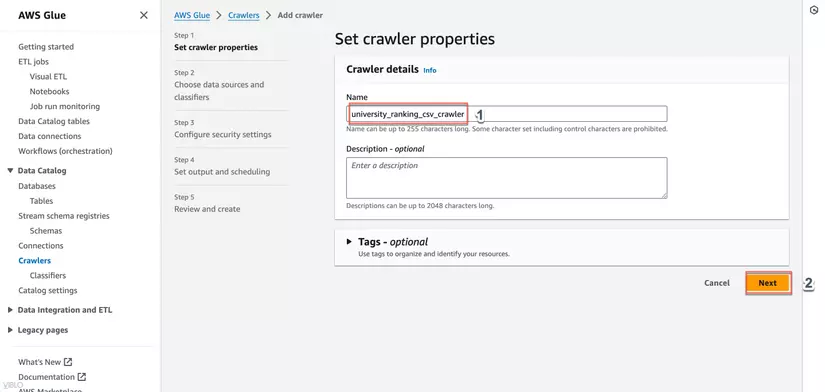
- Trong thanh điều hướng bên trái, chọn Crawlers và nhấn Add crawler.
- Đặt tên cho crawler và nhấn Next.
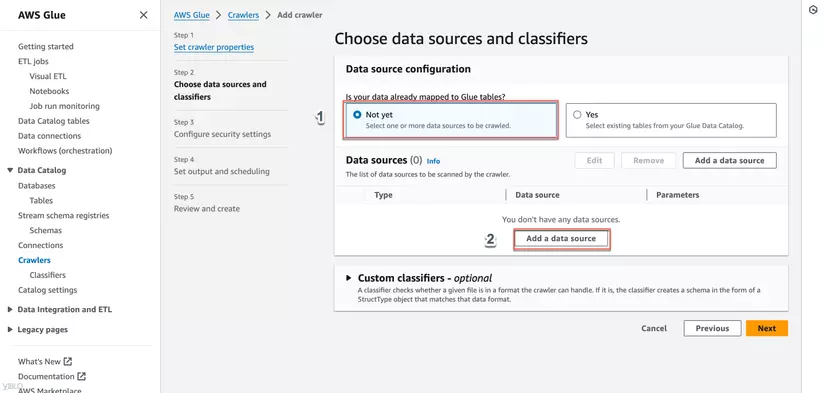
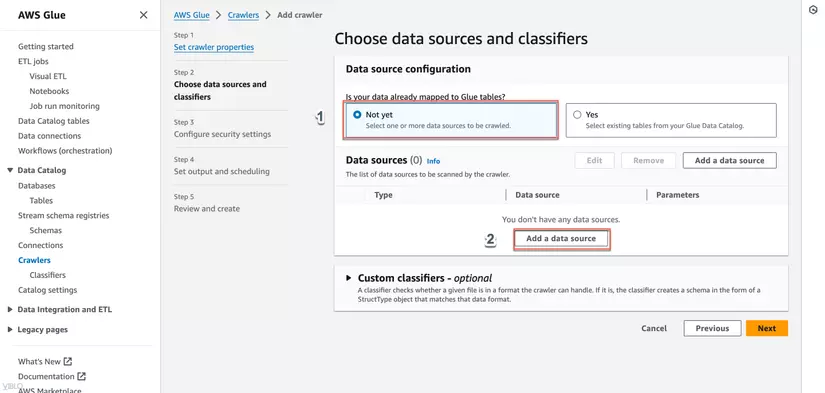
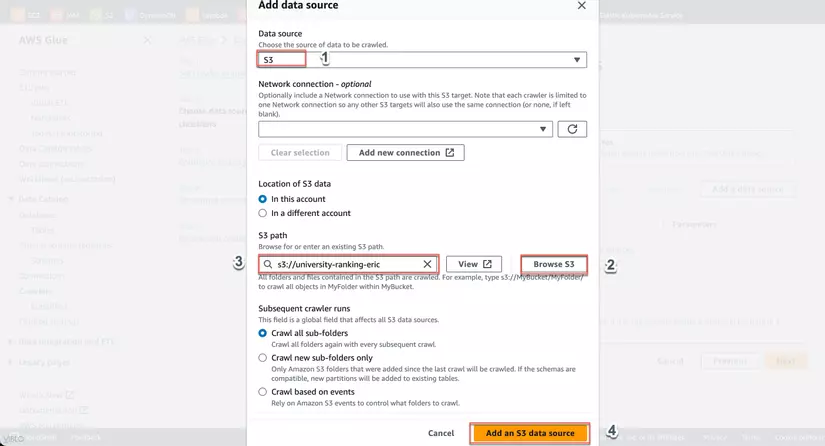
- Trong phần Choose data sources and classifiers, chọn S3 và cung cấp đường dẫn đến bucket hoặc thư mục S3 chứa dữ liệu của bạn, sau đó nhấn Next.
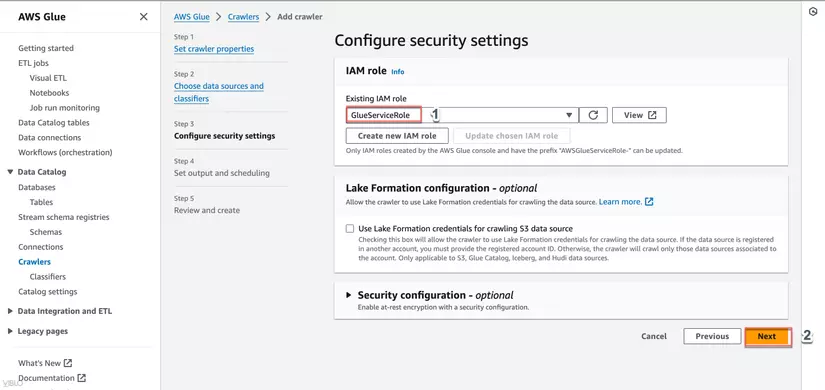
- Trong phần Choose an IAM role, chọn một IAM role GlueServiceRole hiện có, sau đó nhấn Next.
- Trong phần Configure the crawler's output, tạo database nơi bạn muốn lưu metadata và đặt tên cho bảng.
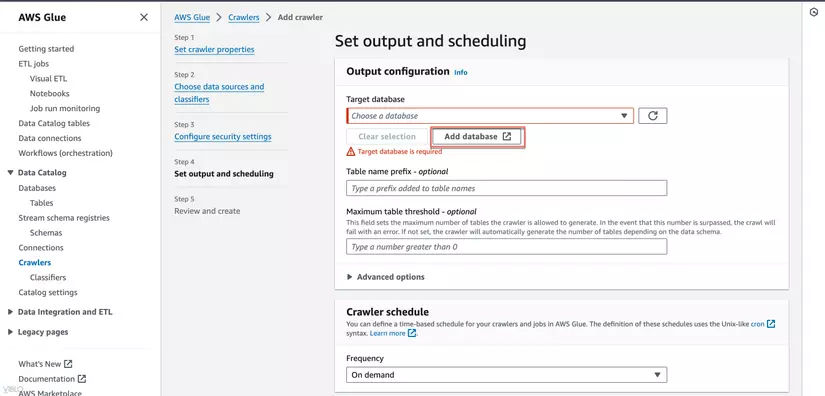
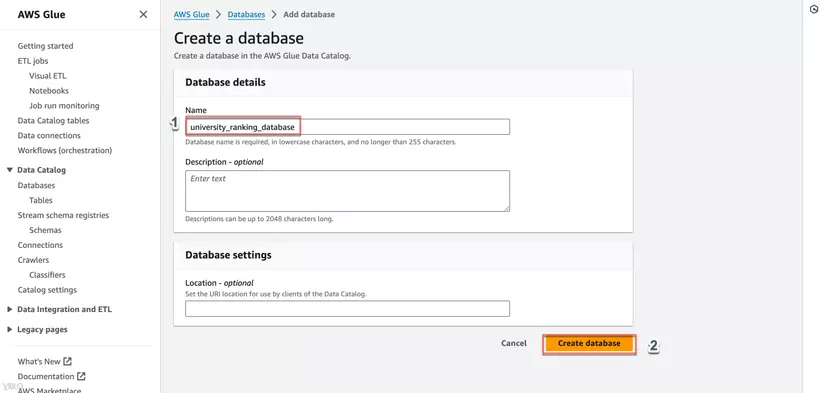
-
Trở lại Configure the crawler's output chọn database vừa tạo
-
Trong phần Create a schedule for this crawler, chọn tần suất chạy crawler nếu muốn hoặc chọn Run on demand, sau đó nhấn Next.
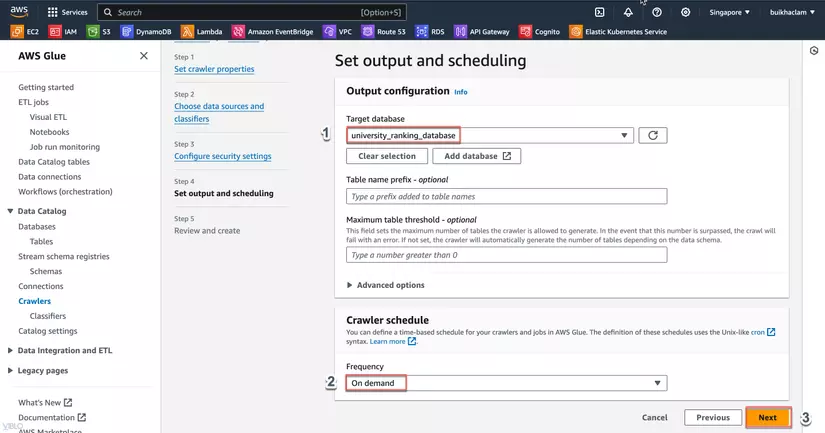
- Xem lại các cấu hình của crawler và nhấn Finish để hoàn tất việc tạo crawler.
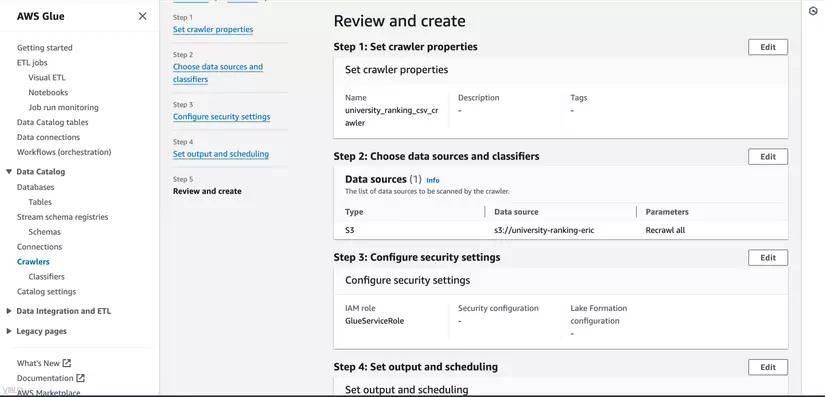
5. Chạy Glue Crawler
- Trong danh sách các crawlers, chọn crawler mà bạn vừa tạo.
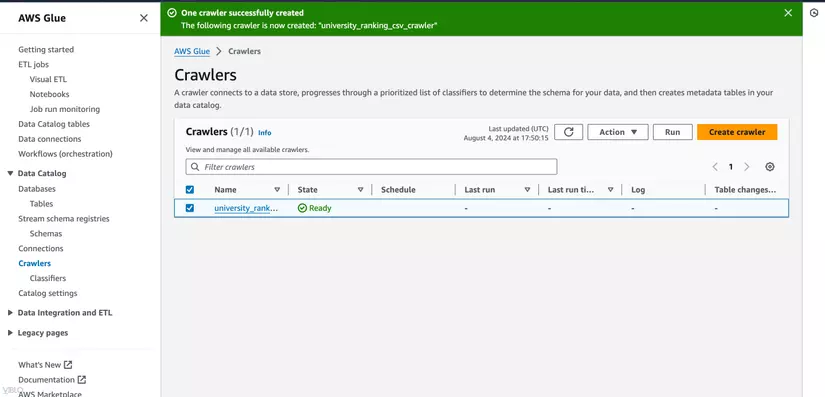
- Nhấn Run để bắt đầu quá trình quét và thu thập metadata.
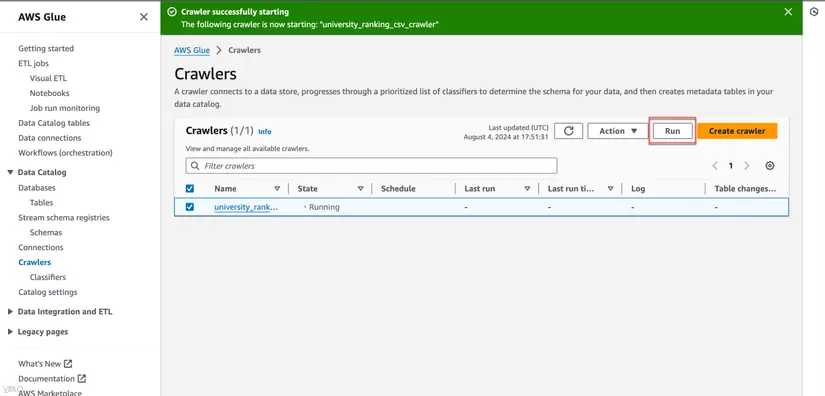
6. Xem Table Vừa Tạo Từ AWS Glue Crawler
- Chọn database đã cấu hình trong bước tạo Glue Crawler
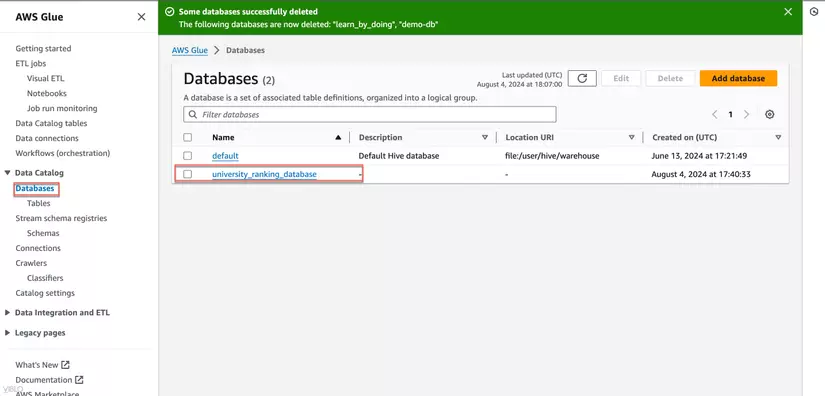
- Trong phần chi tiết của database, chọn Tables in database
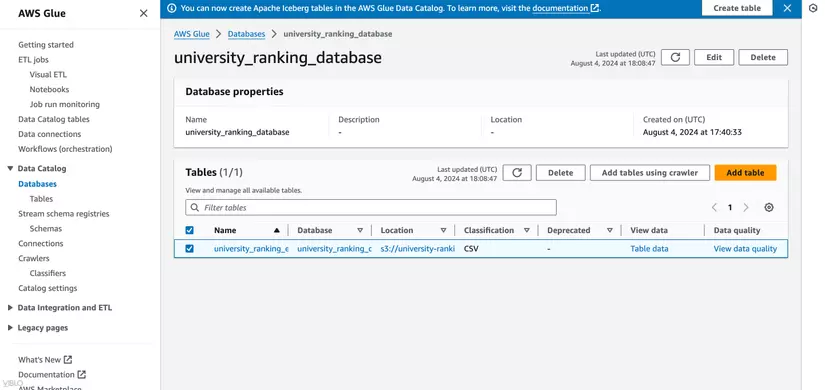
- Chọn table mà Glue Crawler vừa tạo để xem chi tiết về cấu trúc và metadata của table
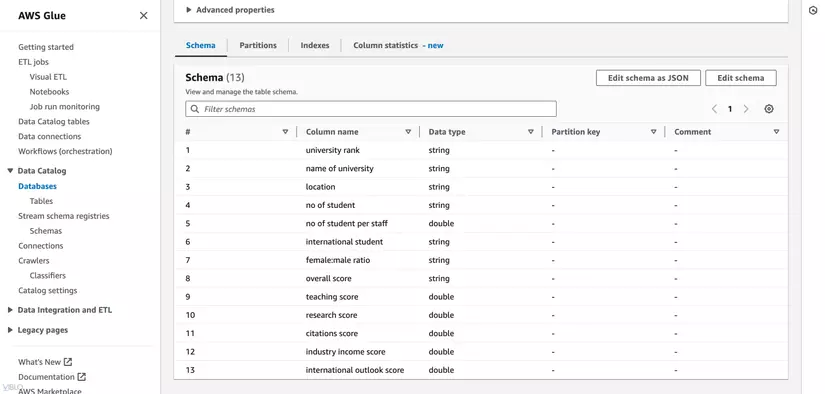
7. Truy Vấn Dữ Liệu Với AWS Athena
- Mở AWS Management Console và truy cập vào giao diện Amazon Athena
- Trong thanh điều hướng bên trái, chọn Query Editor
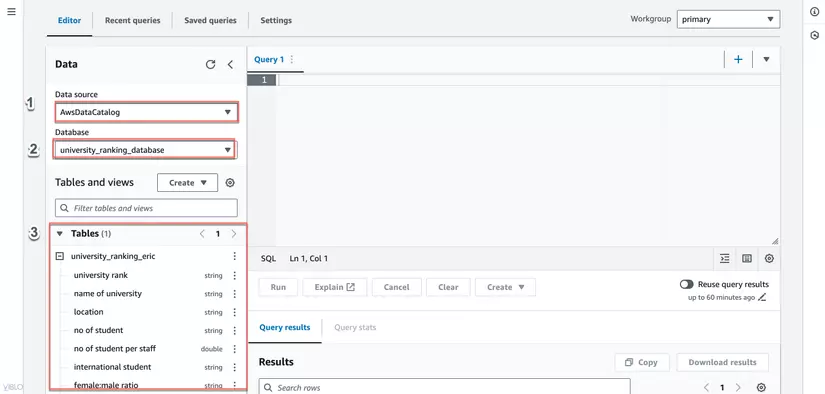
- Trong Query Editor, chọn database mà bạn đã cấu hình trong Glue Crawler từ danh sách dropdown
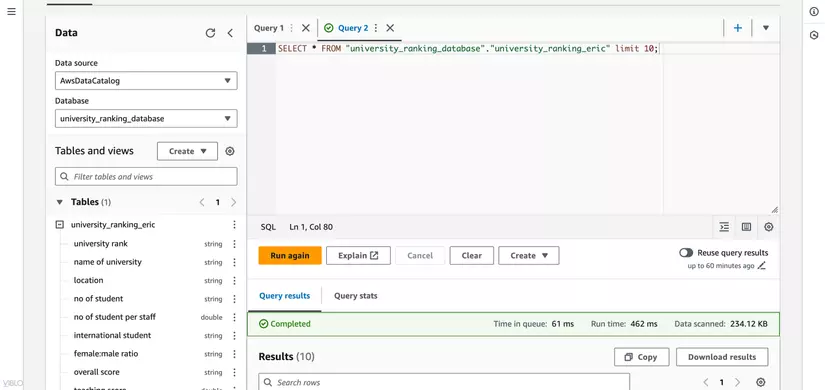
- Nhập câu truy vấn SQL để truy vấn dữ liệu từ table, ví dụ
SELECT * FROM "university_ranking_database"."university_ranking_eric" limit 10;
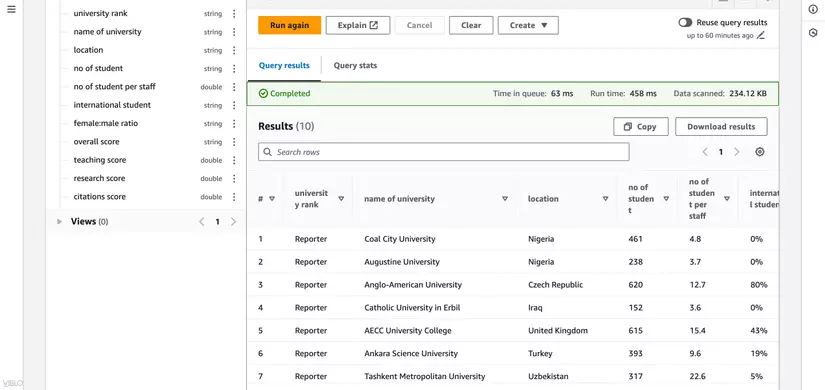
- Truy vấn tất cả thông tin về 10 trường đại học hàng đầu theo điểm tổng quát
SELECT *
FROM "university_ranking_database"."university_ranking_eric"
ORDER BY "overall score" DESC
LIMIT 10;
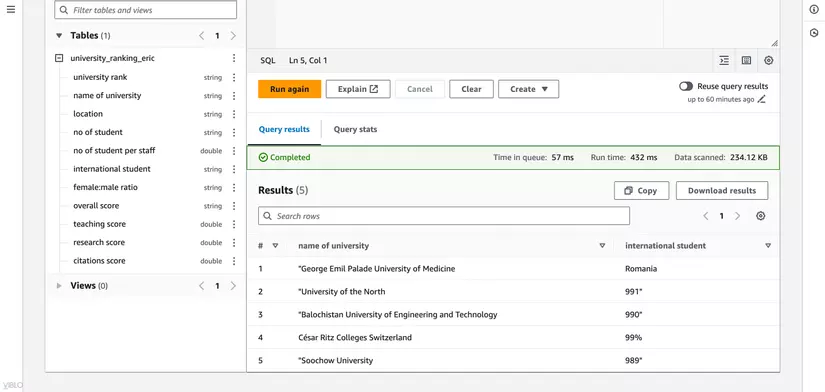
- Tìm các trường đại học có tỷ lệ sinh viên quốc tế cao nhất:
SELECT "name of university", "international student"
FROM "university_ranking_database"."university_ranking_eric"
ORDER BY "international student" DESC
LIMIT 5;
- Tìm trường đại học có điểm nghiên cứu cao nhất ở một địa điểm cụ thể:
SELECT "name of university", "research score"
FROM "university_ranking_database"."university_ranking_eric"
WHERE "location" = 'United States'
ORDER BY "research score" DESC
LIMIT 5;
- Truy vấn trường đại học với tỷ lệ nữ
SELECT "name of university", "female:male ratio"
FROM "university_ranking_database"."university_ranking_eric"
ORDER BY "female:male ratio" DESC
LIMIT 5;
- Tìm các trường đại học có điểm giảng dạy và điểm nghiên cứu cao nhất:
SELECT "name of university", "teaching score", "research score"
FROM "university_ranking_database"."university_ranking_eric"
ORDER BY "teaching score" DESC, "research score" DESC
LIMIT 10;