Mẹo SEO: Nếu bạn muốn hiểu cách tìm kiếm thực sự hoạt động, hãy đọc các bài viết kỹ thuật từ những người xây dựng hệ thống truy xuất, thay vì chỉ đọc các case study SEO.
Tôi vừa đọc công trình gần đây của Cursor về tìm kiếm regex tốc độ cao, và đó là một lời nhắc rất rõ rằng hiệu năng tìm kiếm thường bắt đầu từ thiết kế lập chỉ mục (indexing) và truy xuất (retrieval), chứ không chỉ là “phép màu” của xếp hạng (ranking).
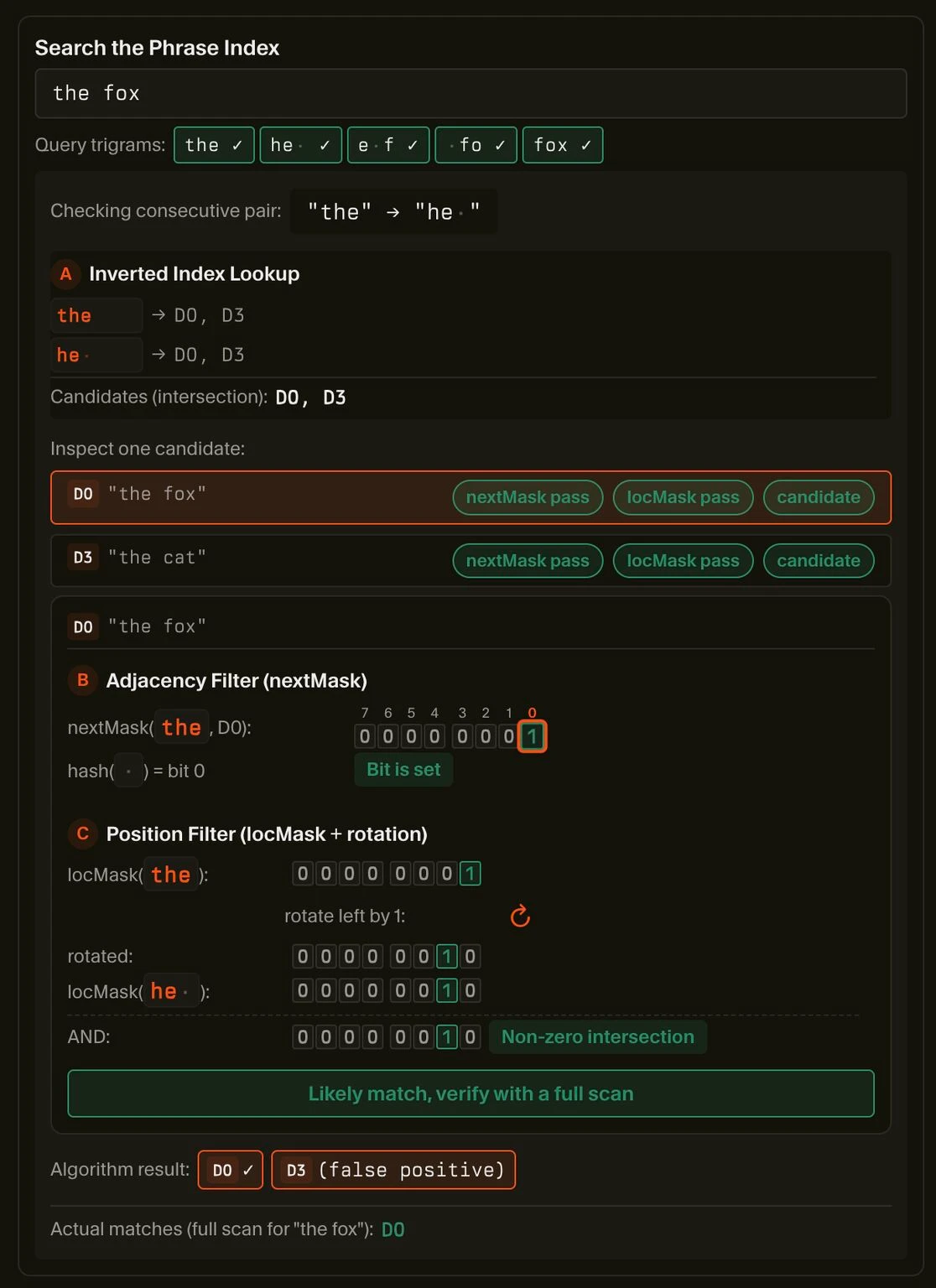
Bài viết của họ đi từ inverted index (chỉ mục đảo) và posting list (danh sách ghi), đến phân rã n-gram, rồi đến bước lọc theo cụm từ (phrase-aware filtering) — nơi hệ thống kiểm tra xem các chuỗi có thực sự đứng liền kề nhau hay không trước khi thực hiện quét toàn bộ.
Hình minh họa dưới đây thể hiện ý tưởng đó rất rõ: một hệ thống có thể tìm ra các tài liệu ứng viên vì chúng chia sẻ các trigram, nhưng điều đó không có nghĩa là cụm từ thực sự tồn tại trong tài liệu. Bạn vẫn cần thêm logic để kiểm tra tính liền kề và vị trí.
Đây là một bài học SEO rất đáng giá.
Hai trang có thể chứa cùng các thuật ngữ, thực thể, hoặc thậm chí cách diễn đạt tương tự, nhưng chất lượng truy xuất sẽ thay đổi khi hệ thống có thể xác định:
-
Thuật ngữ nào xuất hiện cùng nhau
-
Thuật ngữ nào xuất hiện gần nhau
-
Chuỗi nào là khớp thực sự so với khớp giả (false positive)
Cursor xây dựng thêm các bộ lọc này vì việc quét regex kiểu brute-force vẫn có giới hạn. Trong các monorepo rất lớn, họ cho biết các tìm kiếm bằng ripgrep có thể mất hơn 15 giây, nên họ cố gắng giảm không gian tìm kiếm trước khi thực hiện bước xác minh tốn kém.
Họ cũng mô tả việc chấp nhận chi phí cao hơn ở giai đoạn lập chỉ mục, bao gồm các chiến lược n-gram thưa (sparse n-gram), để làm cho thời gian truy vấn nhanh hơn đáng kể.
Vì sao điều này quan trọng với SEO
Tối ưu cho công cụ tìm kiếm nên bao gồm việc hiểu cách các hệ thống truy xuất:
-
Tạo ra tập tài liệu ứng viên (generate candidates)
-
Lọc ứng viên (filter candidates)
-
Xác minh khớp thực sự (verify matches)
-
Sau đó mới quyết định nội dung nào đáng để đánh giá sâu hơn
Đó là lý do vì sao cấu trúc cụm từ (phrase structure), cấu trúc đoạn văn (passage structure), ngữ cảnh nội bộ (internal context), và độ gần ngữ nghĩa (semantic proximity) lại quan trọng đến vậy.
Bạn càng hiểu rõ về inverted indexing, phrase indexing, và các kỹ thuật tối ưu truy xuất như trên, bạn càng hiểu vì sao một số trang dễ được hệ thống tìm thấy, diễn giải và tin tưởng hơn — trong khi những trang khác có thể không bao giờ xuất hiện trong kết quả tìm kiếm.
Khi các mô hình AI thu thập và lọc thông tin cho người dùng, một điểm nghẽn thực sự đang dần xuất hiện: hiệu năng tìm kiếm. Các kỹ sư tìm kiếm sẽ tối ưu hóa công cụ và quy trình của họ giống như cách Cursor đã làm với grep.