1. Vấn đề
Thực thể (entity) trong cơ sở dữ liệu cần có tối thiểu 2 thuộc tính đó là ID và status. Trong ID là một giá trị duy nhất dùng để xác định một đối tượng cụ thể trong một hệ thống hoặc một bản ghi trong cơ sở dữ liệu. ID là trường thông tin rất quan trọng vì nó đảm bảo tính nhất quán (không trùng lặp) trong quản lý thông tin.
ID có thể là một chuỗi các ký tự (550e8400-e29b-41d4-a716-446655440000) hoặc một dãy số tăng dần (1, 2, 3, …). Ví dụ cột ID là primary key với thuộc tính auto_increment trong Database (DB). Khi có một bản ghi mới, DB sẽ tăng giá trị ID này lên 1 đơn vị.
Logic auto_increment rất đơn giản tuy nhiên auto_increment trên 1 DB server sẽ không phù hợp trong hệ phân tán.
Vì có một số vấn đề sau:
- Performance: trong hệ phân tán, nhiều nodes có thể thực hiện thêm mới (insert) cùng lúc nên việc sinh ID được thực hiện trên 1 DB server có thể sẽ tăng độ trễ và ảnh hưởng tới hiệu năng (performance).
- Scalability: khả năng mở rộng không tốt vì việc sinh ID chỉ được thực hiện trên 1 DB server.
- Single point of failure: nếu DB server “toang", các node khác không thể gọi đến để sinh ID.
2. Yêu Cầu
Như vậy, chúng ta cần tìm một giải pháp sinh ID có thể giải quyết đc ít nhất 3 vấn đề trên để có thể chạy được trong hệ phân tán. Nhưng không chỉ có 3 yêu cầu trên, chúng ta còn cần phải làm rõ những yêu cầu khác. Dưới đây là tổng hợp một số yêu cầu của việc sinh ID:
- Một giá trị ID phải là duy nhất.
- ID chỉ gồm số hay có cả chữ và ký tự khác? ví dụ: chỉ bao gồm số.
- Độ dài của ID là bao nhiêu bit? ví dụ: 64bit
- ID có thể sắp xếp theo thứ tự thời gian không? ví dụ: có thể sắp xếp.
- Khả năng sinh bao nhiêu ID trong 1 giây? ví dụ: 10000 IDs trong vòng 1 giây.
3. Các hướng tiếp cận
Tiếp theo, chúng ta sẽ cùng đánh giá một số cách dưới đây để sinh ID trong hệ phân tán.
- Ticket Server
- Multi-master
- UUID
- ULID
- Twitter snowflake
- …
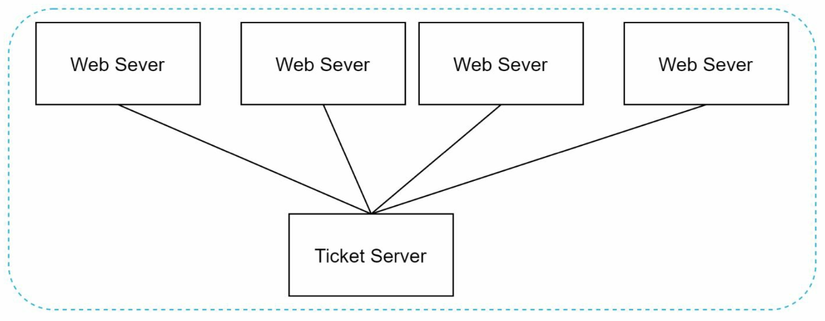
3.1. Ticket Server
Đây là một giải pháp mà Flicker đưa ra. Trong đó, ý tưởng vẫn là sử dụng tính năng auto_increment trên một DB server (Ticket Server) như đã đề cập ở phần Vấn đề. Các node web server sẽ gọi vào Ticket Server để lấy ID.
Ngoài ra, giải pháp của Flicker còn giải quyết được vấn đề tính duy nhất toàn cục (physical) và cục bộ (logical) trên các tập dữ liệu. Bằng cách sử dụng REPLACE thay vì INSERT. Nếu mọi người quan tâm tới vấn đề này thì có thể đọc thêm link dưới phần Tham khảo.
Ưu điểm:
- Đảm bảo tính duy nhất.
- Đơn giản.
- Dễ triển khai, phù hợp với những hệ thống vừa và nhỏ.
- ID chỉ gồm số.
Nhược điểm: có 3 nhược điểm đã đề cập ở trên như
- Hiệu năng chưa cao.
- Single point of failure. Nếu chạy thêm 1 ticker server phụ và có bộ đếm giống ticket server chính thì sẽ phát sinh thêm vấn đề về đồng bộ dữ liệu giữa 2 server.
- Để cải thiện khả năng mở rộng thì chúng ta đến với cách tiếp theo.
Bạn có thể tham khảo thêm một giải pháp tương tự, chúng ta có thể sử dụng lệnh INCR của Redis để sinh ID.
3.2. Multi-master
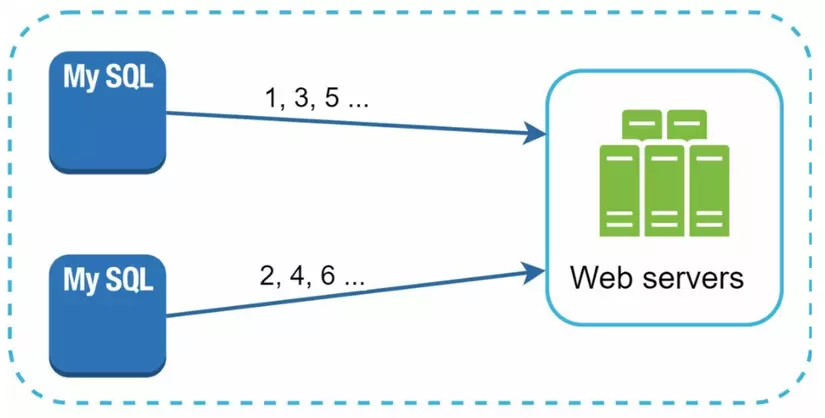
Cách này cũng sử dụng tính năng auto_increment. Tuy nhiên, việc sinh ID sẽ được thực hiện trên nhiều DB server thay vì chạy trên 1 DB server. Để ID của các DB server sinh ra không bị trùng nhau thì trên mỗi DB server sẽ được cấu hình auto tăng thêm K đơn vị, trong đó K là số DB server.
Để cấu hình auto tăng thêm 2 đơn vị trên một bảng, đầu tiên ta tạo bảng có auto_increment như bình thường. Sau đó, xét thêm cấu hình auto_increment_increment
SET SESSION auto_increment_increment = 2;
Ưu điểm:
- Đảm bảo tính duy nhất.
- ID chỉ gồm số.
- Dễ triển khai.
- Tăng khả năng mở rộng
Nhược điểm:
- Tuy tăng được khả khả mở rộng nhưng giải pháp này không thực sự linh hoạt. Khi thêm vào hoặc gỡ ra 1 DB server thì hệ thống sẽ phải down time một khoảng thời gian để cập nhật số lượng DB server.
- IDs có thể không tăng đều giữa các DB server. Ví dụ: DB server A có 3 bản ghi có id 1, 3, 5. Tuy nhiên lúc này DB server B mới chỉ có 1 bản ghi id = 2.
- Cần thêm giải pháp để hỗ trợ mở rộng ra nhiều data center.
3.3. UUID
Sử dụng UUID là một cách khác để dễ dàng tạo ra nhiều unique IDs. UUID là một chuỗi gồm 128bit và thường được sửa dụng trong các hệ thống máy tính. Ví dụ: 550e8400-e29b-41d4-a716-446655440000
UUID có tỉ lệ đụng đô (collusion), sinh ra 2 ID trùng nhau, là rất thấp. Với UUIDv4 thì ngay cả khi sinh 1 tỉ UUIDs trong 1 giây thì phải mất hơn 100 năm thì mới có khả năng sinh trùng ID.
Với cách này, chúng ta không cần server tập trung nào để sinh ID. Mà việc này sẽ được thực hiện ngay trên các ứng dụng và được thực hiện một cách độc lập.
Ưu điểm:
- Siêu đơn giản.
- Khả năng mở rộng cao.
- Độ dài cố định
Nhược điểm:
- Vẫn có khả năng xảy ra đụng độ.
- UUID không thể sắp xếp theo thời gian.
- UUID dài nên tốn nhiều không gian lưu trữ hơn.
- UUIDv4 chứa 1 chuỗi random nên gây ra khó khăn trong quá trình đánh index của DB.
3.3.1. Đọc thêm
- Một số trường hợp người ta có thể gọi UUID là GUID (Globally Unique Identifier).
- UUID có nhiều version, mỗi version đều có ưu nhược điểm riêng.
- Bạn có thể đọc thêm về vấn đề khi sử dụng UUID với MySQL và một số cách khắc phục ở phần Tham khảo [4] bên dưới.
3.4. ULID
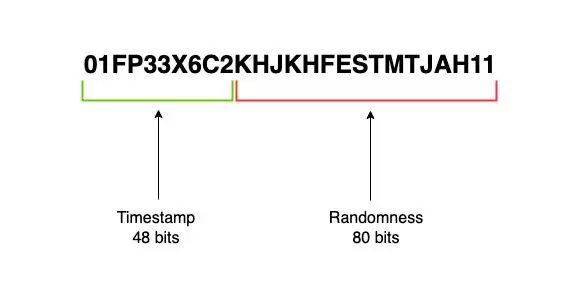
ULID được thiết kế để có thể sắp xếp được về mặt cấu trúc. Cấu trúc của ULID gồm Timestamp (48 bits) và Randomness (80 bits). Nhưng sẽ được encode thành một chuỗi gồm 26 ký tự.
Ưu điểm:
- Có chứa thông tin timestamp.
- Có thể sắp xếp được theo thời gian.
- Độ dài cố định
- Không chứa ký tự đặc biệt (URL safe: thân thiện với web)
- Case insentive
Nhược điểm:
- Xác suất xảy ra đụng độ thấp tuy nhiên vẫn có và cao hơn UUIDv4. ULID có 80 random bits trong khi UUIDv4 có 122 random bits.
- Vẫn tương đối dài.
3.5. NanoID
Nếu bạn cần một cách sinh ID có khả năng tuỳ chỉnh cao thì bạn có thể tham khảo thêm về NanoID [7]. Ví dụ: kw2c0khavhl. Tuy nhiên, bạn cần lưu ý một số điểm sau: bản thân NanoID chưa có cơ chế sắp xếp và xác suất xảy ra đụng độ có thể cao.
3.6. Twitter snowflake
Trong những cách trên, có trường hợp chưa đáp ứng được yêu cầu về khả năng mở rộng, có trường hợp lại chưa đáp ứng được yêu cầu về độ dài, … Nhưng còn một cách khác có thể đáp ứng những yêu cầu trên đó là Snowflake ID của Twitter.
Snowflake ID gồm 64 bit và có cấu trúc như sau:

- Sign Bit (1 bit): luôn là 0
- Timestamp (41 bits): số milisecond kể từ Twitter epoch (mốc 2010-11-04).
- Datacenter ID (5 bits): mã định danh cho datacenter. Giá trị được khởi tạo khi bắt đầu chạy trình Snowflake generator.
- Machine ID (5 bits): mã định danh cho máy trong datacenter. Giá trị được khởi tạo khi bắt đầu chạy trình Snowflake generator.
- Sequence Number (12 bits): Số đếm tăng dần cho các ID được sinh trong một mili giây. Số đếm này sẽ reset về 0 khi sang milisecond khác. Dùng để đảm bảo tính duy nhất trong một mili giây. Như vậy, 1 máy có sinh 2 ^ 12 (=4096) IDs trong vòng 1 mili giây.
Ví dụ một Snowflake ID (một số nguyên 64-bit): 689369924653004799.
Khi triển khi hệ thống Snowflake ID generator sẽ như sau:
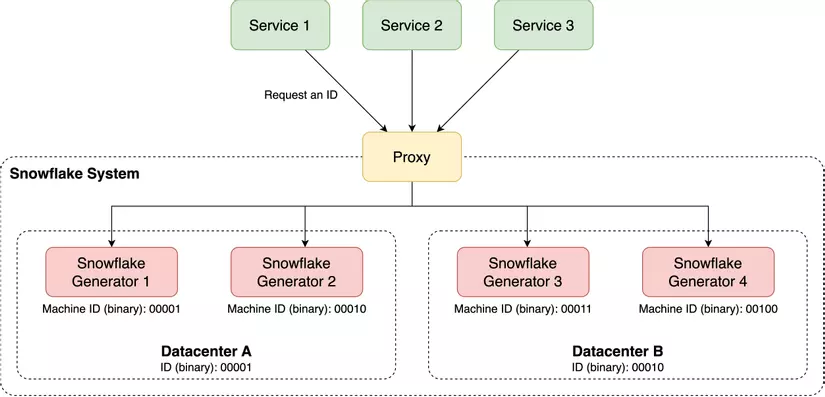
Ưu điểm:
- Đảm bảo được tính duy nhất.
- Có khả năng mở rộng tốt.
- Có thể sắp xếp theo thứ tự thời gian.
- Cấu trúc đơn giản.
- Độ dài gọn nhẹ (1 số nguyên 64-bit) dễ dàng thao tác và lưu trữ.
Nhược điểm:
- Để triển khai giải pháp này sẽ phức tạp và tốn kém.
- Giới hạn về khoảng thời gian hoạt động. Phần timestamp có 41 bits nghĩa là Snowflake ID generator có thể hoạt đông trong vòng 2 ^ 41 miliseconds (~ 69.7 năm). Do cấu trúc và logic sinh ID đơn giản, bạn có thể điểu chỉnh độ dài của phần timestamp, datacenter id, machine id và mốc epoch để khắc phục phần nào nhược điểm này.
- Giá trị các ID không liên tục.
- Một máy có thể sinh 4096 IDs trong vòng 1 mili giây. Đây là một con số tương đối lớn, tuy nhiên nó cũng là 1 giới hạn chúng ta cần để lưu ý.
Dựa trên ý tưởng của Snowflake ID, Sony có một sinh ID khác (Sonyflake ID [8]), có khoảng thời gian hoạt động lâu hơn (~174 năm) nhưng sinh ID chậm hơn Snowflake ID.
4. Tổng Kết
- Đầu tiên chúng ta cần xác định hết yêu cầu và các yêu cầu tối thiểu của việc sinh ID.
- Không có giải pháp nào có thể đáp ứng được tất cả yêu cầu. Đa số các trường hợp chúng ta chỉ cần có một tập con của các yêu cầu đề cập ở trên. Ví dụ trường hợp A, ta không yêu cầu có khả năng sort. Trường hợp B, chúng ta không yêu cầu ID chỉ có số. Trường hợp C, ta cần một giải pháp dễ triển khai, … Dựa vào yêu cầu cụ thể để ta chọn ra giải pháp phù hợp nhất.
- Nếu các giải pháp trên chưa đáp được yêu cầu của bạn thì bạn hoàn toàn có thể tạo ra 1 cách sinh ID phục vụ riêng bài toán của bạn.
Bạn đang sử dụng cách thức nào để sinh ID, hãy comment ở dưới giúp mình nhé.
Nếu mọi người thấy bài viết hữu ích thì nhờ mọi người share để nội dung của Ronin được nhiều người biết hơn.
Cám ơn mọi người. 🙏
5. Tham khảo
[1] Sách System Design Interview: An Insider’s Guide - Alex Xu
[2] Ticket Servers: https://code.flickr.net/2010/02/08/ticket-servers-distributed-unique-primary-keys-on-the-cheap/
[3] UUID: https://en.wikipedia.org/wiki/Universally_unique_identifier
[4] Vấn đề khi sử dụng UUID với MySQL: https://planetscale.com/blog/the-problem-with-using-a-uuid-primary-key-in-mysql
[5] ULID: https://wiki.tcl-lang.org/page/ULID
[6] Shopify dùng ULID sinh Idempotency Key: https://shopify.engineering/building-resilient-payment-systems
[7] NanoID: https://zelark.github.io/nano-id-cc/
[8] SonyFlake ID: https://github.com/sony/sonyflake
🧑💻 100+ Ronin Engineers: https://roninhub.com/
📚️ System Design VN: https://fb.com/groups/systemdesign.vn