Machine Translation là gì?
Machine Translation(MT) là nhiệm vụ dịch một đoạn văn bản từ ngôn ngữ nguồn(source language) sang một ngôn ngữ đích(target language). Đơn giản như lúc ta bật google dịch lên rồi dịch câu tiếng Nhật: ’皆さん、おはようございます’。Ta được câu tiếng Việt là: "Chào buổi sáng tất cả mọi người".
Lịch sử của Machine Translation
Machine Translation bắt đầu được nghiên cứu từ những năm 50 bằng những chiếc máy tính cổ đại có sức mạnh còn yếu hơn cả máy casio bây giờ  MT được đầu tư rất nhiều bởi quân đội, nhưng cơ bản chỉ dựa trên những quy tắc đơn giản nên xảy ra rất nhiều vấn đề.
Những năm 1990 đến 2010, SMT(Statistical Machine Translation) được phát triển nhưng vẫn chưa đáp ứng được nhu cầu của người dùng.
Từ năm 2014 đến nay, NMT(Neura Machine Translation) bắt đầu được nghiên cứu và bước đầu đạt được sự tin cậy của người dùng.
MT được đầu tư rất nhiều bởi quân đội, nhưng cơ bản chỉ dựa trên những quy tắc đơn giản nên xảy ra rất nhiều vấn đề.
Những năm 1990 đến 2010, SMT(Statistical Machine Translation) được phát triển nhưng vẫn chưa đáp ứng được nhu cầu của người dùng.
Từ năm 2014 đến nay, NMT(Neura Machine Translation) bắt đầu được nghiên cứu và bước đầu đạt được sự tin cậy của người dùng.
Statistical Machine Translation
Ý tưởng chính của SMT là học một mô hình xác suất từ dữ liệu. Giả sử ta muốn dịch từ tiếng Pháp sang tiếng Anh.
Ta muốn tìm bản dịch tốt nhất bằng tiếng Anh(y) cho câu tiếng Pháp(x):
Sử dụng Bayes Rule ta có thể tách làm 2 thành phần được học riêng biệt:
Ta có thể coi: là Translation Model để hiểu cách từ và cum từ được dịch thế nào. Nó được học từ cả 2 ngôn ngữ.
là Language Model để biết được cách viết tiếng Anh tốt và dĩ nhiên nó chỉ được học từ tiếng Anh.
Tóm lại
- SMT là một lĩnh vực nghiên cứu khổng lồ, hệ thống tốt nhất của nó rất phức tạp.
- Hệ thống có nhiều thành phần con được thiết kế riêng biệt, rất nhiều các kỹ thuật đến từ Statistical learning.
- Cần các kỹ thuật feature engineering.
- Yêu cầu biên dịch và duy trì tài nguyên bổ sung.
- Rất nhiều nỗ lực của con người để duy trì nó.
Neural Machine Translation
Neural Machine Translation là gì?
Neural Machine Translation(NMT) là một cách để cho máy tính thực hiện dịch ngôn ngữ với một end-to-end neural network.
Kiến trúc neural network này được gọi là sequence-to-sequence model(aka seq2seq).
Dưới đây là hình ảnh minh họa:
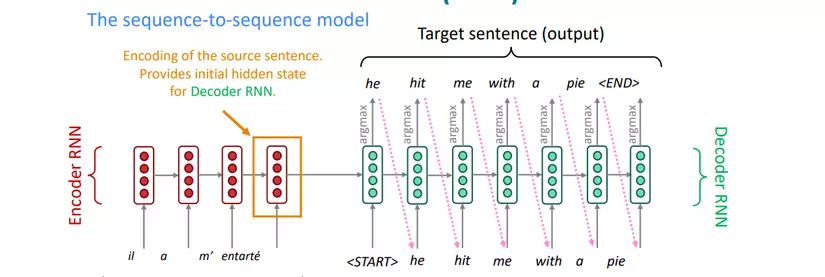
Seq2Seq
Seq2Seq là một mô hình được đề xuất từ năm 2014 cho việc dịch tiếng Anh-tiếng Pháp. Seq2Seq cũng là một Conditional Language Model. NMT-Seq2Seq tính toán một cách trực tiếp:
với là số bước thời gian.
Ở một cấp độ cao hơn, một mô hình Seq2Seq là một mô hình end-to-end với 2 mạng RNN(hoặc các biến thể của RNN):
- Encoder: Bộ mã hóa lấy câu nguồn làm đầu vào của mô hình và encode nó thành một context-vector có kích thước cố định.
- Decoder: Bộ giải mã sử dụng context-vector của encoder làm khởi tạo cho hidden-state đầu tiên.
Kiến trúc Seq2Seq - Encoder
Nhiệm vụ của Encoder là đọc câu nguồn cho mô hình Seq2Seq và tạo context-vector có kích thước cố định. Để làm được điều này, Encoder sử dụng một mạng RNN(thường là LSTM) để đọc từng token tại một bước thời gian . Hidden-state cuối cùng sẽ trở thành . Tuy nhiên, rất khó khăn để nén một chuỗi có độ dài tùy ý vào một context-vector có kích thước cố định duy nhất(đặc biệt với các nhiệm vụ khó như dịch thuật). Vì vậy encoder sử dụng multi-layer.
Encoder cũng làm một việc tương đối kỳ lạ đó là xử lý chuỗi theo trình tự ngược lại. Nghe vô lý những lại hết sức hợp lý . Việc xử lý như vậy giúp cho Decoder thực hiện một cách tốt hơn khi có lượng thông tin ở phía đầu chuỗi nguồn nhiều hơn, giúp cho việc dịch được tốt hơn ở những bước đầu, hay hiểu nôm na là: "Đầu có xuôi thì đuôi mới lọt". Sau đây là hình ảnh minh họa về encoder sử dụng LSTM:
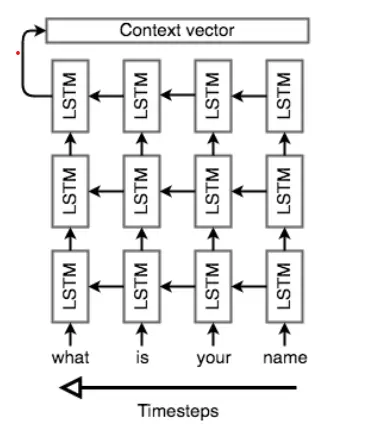
Bidirectional RNNs
Để giúp model nắm bắt tốt sự phụ thuộc trong câu nguồn, ta sử dụng Bidirectional RNNs.
Minh họa cho việc encoder sử dụng Bidirectional RNN:
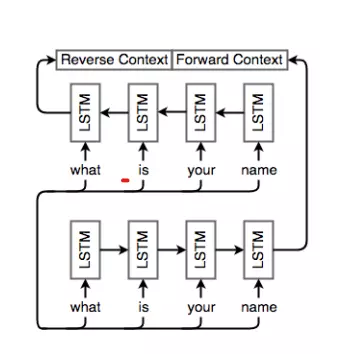
Kiến trúc Seq2Seq-Decoder
Decoder cũng là một mạng LSTM nhưng sử dụng phức tạp hơn encoder một chút. Về cơ bản ta sử dụng nó để tạo ra các từ ở mỗi bước thời gian. Để làm được điều đó, ta sử dụng multi-layer và khởi tạo hidden-state của layer đầu tiên bằng việc sử dụng context-vector của encoder.
Sau khi Decoder đã được thiết lập với context của encoder Sau đó ta sẽ đặt token vào cuối cùng của input(thêm một bước thời gian của encoder) hoặc ta có thể đặt vào đầu của output. Sau đó ta sẽ chạy qua các layer của LSTM theo sau cùng là softmax để tạo đầu ra. Ta lặp lại công việc trên qua các bước thời gian.
Khi ta có trình tự đầu ra, bây giờ sẽ đến công việc tính loss. Ở đây ta sử dụng Cross-Entropy Loss.
Một lưu ý là ta cả encoder và decoder đều được training tại cùng một thời điểm, việc này giúp cả hai cùng học được một cách biểu diễn context-vector.
Sau đây là hình ảnh minh họa cho decoder:
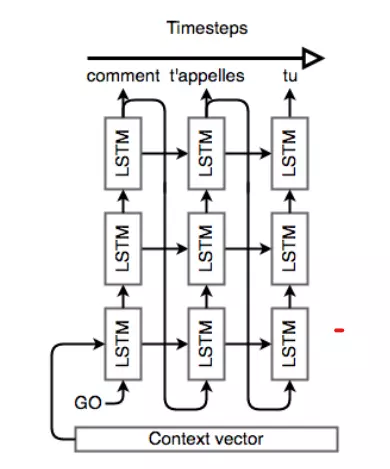 Lưu ý không có sự liên quan giữa độ dài của chuỗi nguồn và chuỗi đích. Tuy nhiên Seq2Seq thường kém hiệu quả với các chuỗi nguồn dài do các giới hạn thực tế của LSTM.
Lưu ý không có sự liên quan giữa độ dài của chuỗi nguồn và chuỗi đích. Tuy nhiên Seq2Seq thường kém hiệu quả với các chuỗi nguồn dài do các giới hạn thực tế của LSTM.
Các cách chọn đầu ra cho Seq2Seq-NMT
Giả sử bây giờ ta đã có được đầu ra softmax của các hidden-state. Công việc của chúng ta bây giờ là phải chọn chuỗi nguồn sao cho hợp lý vì không phải cứ lấy xác suất cao nhất của softmax của tất cả các bước thời gian là tốt. Tính toán đầu ra cuối cùng này thực chất đến từ SMT. Xem xét một mô hình tính toán của câu đích y và câu nguồn x. Ta muốn tìm
Vì không gian tìm kiếm có thể rất lớn, ta phải thu nhỏ kích thước của nó. Dưới đây là một số cách tiếp cận:
- Exhaustive search: Đây là ý tưởng đơn giản nhất. Chúng tôi tính toán xác xuất của mọi trường hợp có thể xảy ra rồi chọn lấy cái có xác suất cao nhất. Tuy nhiên cách này bất khả thi vì không gian tìm kiếm tăng theo cấp số nhân của input-size.
- Ancestral sampling: Ta thực hiện tính toán xác suất có điều kiện ở bước thời gian T chỉ phụ thuộc vào một số bước thời gian ở đằng trước:
Về mặt lý thuyết, cách này hiệu quả và chính xác về mặt góc nhìn. Tuy nhiên, trên thực tế cách này có hiệu suất thấp và phương sai khá cao.
- Greedy Search : Tại mỗi bước thời gian ta chọn xác suất cao nhất có thể xảy ra. Nói cách khác:
Cách làm này hiệu quả và tương đối tự nhiên. Tuy nhiên, nó không thể khám phá hết tất cả các trường hợp có thể xảy ra trong không gian xác suất của câu, và nếu nó mắc lỗi ở một bước thời gian thì hậu quả là tương đối lơn. Xem ví dụ sau:

- Beam Search: Đây là lựa chọn phổ biến và hiệu quả nhất cho đến thời điểm hiện tai. Ý tưởng của beam search là sẽ chọn lấy xác suất lớn nhất của một softmax trong một bước thời gian và chỉ xem sự lựa chọn cho một bước thời gian, cụ thể được giải thích trong hình sau:
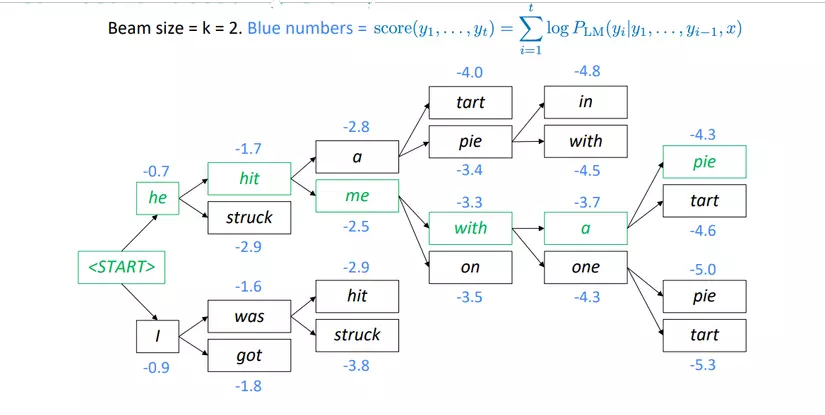 Beam search không đảm bảo tìm được trường hợp tối ưu, nhưng hiệu quả hơn khá nhiều so với greedy search và exhaustive search.
Beam search không đảm bảo tìm được trường hợp tối ưu, nhưng hiệu quả hơn khá nhiều so với greedy search và exhaustive search.
Ví dụ về Seq2Seq-NMT:
Giả sử ta muốn dịch một câu tiếng Anh: "What is your name" sang một câu tiếng Pháp: "Quel est ton nom". Đầu tiên ta sẽ bắt đầu với 4 one-hot vectors cho đầu vào. Sau đó ta sẽ sử dụng embedding từ cho 4 one-hot vectors này. Tiếp theo ta đưa chúng vào multi-layer LSTM với việc đọc câu theo thứ tự ngược lại và mã hóa chúng thành một context-vector(Encoder). Context-vector này được sử dụng để khởi tạo hidden-state của layer đầu tiên của một multi-layer LSTM khác. Sau đó thực hiện softmax trên đầu ra của hidden-layer cuối cùng ta được từ đầu tiên của chuỗi đích. Kể từ bước thời gian tiếp theo, ta có 2 sự lựa chọn, hoặc dùng đầu ra của bước thời gian trước làm đầu vào, hoặc dùng từ của câu nguồn của tệp dữ liệu để tiến hành làm đầu vào(teacher forcing). Sau đó tiếp tục tính softmax của hidden-layer cuối cùng. Trong quá trình backprop, weight của LSTM-encoder được cập nhật để giúp cho việc biểu diễn không gian vector từ tốt hơn, trong khi đó weight của LSTM-decoder được cập nhật để tạo ra các câu chính xác về mặt ngữ pháp liên quan đến context-vector của encoder.
Ưu điểm của NMT
- Cho hiệu suất tốt hơn các mô hình Machine Translation khác.
- Sử dụng context hiệu quả hơn.
- Sử dụng các cụm từ tương đồng tốt hơn.
- Cài đặt chỉ bằng một end-to-end neural network
- Cần ít nỗ lực human-engineering hơn SMT
Nhược điểm của NMT
- Khó có thể hiểu được sâu bên trong một mô hình NMT đang thực hiện những gì nên rất khó để debug.
- NMT rất khó để kiểm soát.
Một số cách đánh giá một mô hình Machine Translation
- Human Evaluation: Phương pháp đầu tiên và có thể ít gây ngạc nhiên nhất là để mọi người tự đánh giá tính đúng đắn, đầy đủ và thông thạo của hệ thống dịch.Giống như Turing Test, nếu bạn có thể đánh lừa con người rằng không thể phân biệt bản dịch do con người tạo ra với bản dịch hệ thống của bạn, mô hình của bạn đã vượt qua bài kiểm tra để trông giống như một câu ngoài đời thực.
- Bilingual Evaluation Understudy(BLEU): Trong năm 2002, cách nhà nghiên cứu của IBM đã phát triển e Bilingual Evaluation Understudy (BLEU). Đến nay nhiều biến thể của BLEU đã được sinh ra, BLEU là một trong các phương pháp tin cậy nhất trong Machine Translation.(Link về BLEU paper mình để ở phần tài liệu tham khảo)
Kết luật
Như vậy, mình đã giới thiệu một cách tổng quan về NMT. Hiện nay rất nhiều mô hình NMT đã được sinh ra dựa trên Attention, Transformer, BERT, v.v. Nhưng để hiểu được những mô hình NMT mới này, ta chắc chắn phải nắm được gốc dễ của NMT. Trong các phần tiếp theo của series NMT, mình sẽ cùng mọi người tìm hiểu về Attention và tiến hành cài đặt một mô hình NMT đơn giản.
Tài liệu tham khảo
- https://www.aclweb.org/anthology/P02-1040.pdf - paper về BLEU Score
- http://colah.github.io/posts/2015-08-Understanding-LSTMs/ - blog giúp mọi người hiểu hơn về LSTM
- https://arxiv.org/pdf/1409.3215.pdf - original paper về seq2seq NMT
- https://arxiv.org/pdf/1706.03762.pdf - "Attention all you need" nghe tên đã thấy cháy :v
- https://arxiv.org/pdf/1810.04805.pdf - Paper về BERT