Chắc hẳn là khái niệm đám mây từ khóa (word cloud) đã không còn xa lạ gì trong thời đại thông tin số bùng nổ như ngày nay. Chúng ta thường thấy nó xuất hiện trên các bài báo, công cụ tìm kiếm, thể hiện những từ khóa được tìm kiếm nhiều nhất hoặc là chủ đề của một nội dung nào đó.
Đám mây từ khóa hoặc đám mây thẻ (tag cloud) là biểu diễn dưới dạng đồ họa của tần suất xuất hiện của các từ, qua đó làm nổi bật các từ xuất hiện thường xuyên hơn trong (các) văn bản gốc. Từ trong hình ảnh càng lớn thì từ đó càng phổ biến và có ý nghĩa quan trọng.

Trong phạm vi bài viết này, mình sẽ sử dụng hai công cụ là Spacy và thư viện wordcloud của python để phân tích nội dung một văn bản bất kỳ và tạo đám mây từ khóa thể hiện tần suất và từ loại của các từ xuất hiện thường xuyên trong một văn bản, cụ thể là đối với văn bản tiếng Nhật. Mình cũng sẽ nêu ra một số vấn đề đặc thù có thể gặp phải khi làm việc với văn bản tiếng Nhật.
Các bước cụ thể như sau:
1. Làm sạch và chuẩn hóa text đầu vào
Khác với tiếng Việt, tiếng Anh hay các loại chữ latin thường sử dụng phương thức encoding phổ biến là UTF-8, tiếng Nhật sử dụng khá nhiều phương thức encode khác nhau (EUC-JP, ISO 2022 JP, vv., hoặc phổ biến nhất là Shift-JIS).
Bên cạnh đó, trong tiếng Nhật cũng có nhiều ký tự đặc biệt, đơn cử như kiểu full-width và half-width đối với ký tự latin:
Full-width: VIBLO 123
Half-width: VIBLO 123
Do vậy để dễ dàng thực hiện các bước tokenize cũng như vẽ word cloud tiếp theo, việc cần thiết là cần convert đoạn văn bản đầu vào textthành một định dạng chuẩn là UTF-8.
Module unicodedata của python có cung cấp một function phục vụ việc này là unicodedata.normalize(form, unistr), trong đó các form bao gồm ‘NFC’, ‘NFKC’, ‘NFD’, and ‘NFKD’. Sự khác nhau giữa các form có thể được tham khảo thêm trong bài này. (Thường thì ta sẽ dùng 'NFKC')
import unicodedata
text = unicodedata.normalize('NFKC', text)
Tiện thể bỏ đi các dấu câu (punctuation) và các ký tự đặc biệt khác
import re
text = re.sub(r"[!#$%&'()*+,-./:;<=>_@.com[\]^_`{|}~]", " ", text)
text = re.sub(r"\\n", "", text)
text = re.sub(r"\\", "", text)
text = re.sub(r"\n", "", text)
text = re.sub(r"\t", "", text)
text = re.sub(r'"', "", text)
Thông thường bước làm sạch text này sẽ bao gồm cả việc loại bỏ các stop words. Stop words là những từ xuất hiện nhiều trong một ngôn ngữ nhưng lại không mang nhiều ý nghĩa. Ví dụ như trong tiếng việt, stop words là những từ như: để, này, kia; trong tiếng Anh là những từ như: is, that, this... Dưới đây là một trong những cách lấy list stop words trong tiếng Nhật từ thư viện. Tùy vào từng bài toán cụ thể mà có thể chúng ta sẽ muốn chỉnh sửa và bổ sung danh sách này.
from urllib.request import urlopen slothlib_path = 'http://svn.sourceforge.jp/svnroot/slothlib/CSharp/Version1/SlothLib/NLP/Filter/StopWord/word/Japanese.txt'
slothlib_file = urlopen(slothlib_path)#.read()
slothlib_stopwords = [line.decode("utf-8").strip() for line in slothlib_file]
stop_words = [ss for ss in slothlib_stopwords if not ss==u''] stop_words
Output: ['あそこ', 'あたり', 'あちら', 'あっち', 'あと', 'あな', 'あなた', 'あれ', 'いくつ', 'いつ', 'いま', 'いや', 'いろいろ', 'うち', 'おおまか', ....]
Sau khi thực hiện bước tách từ dưới đây ta sẽ loại bỏ các từ trong danh sách stop words này khi thực hiện các bước tiếp theo.
2. Tách từ (Tokenization) và gán nhãn từ loại (part-of-speech tagging)
Tiếp theo, để tạo được một đám mây từ khóa ta phải tìm kiếm các từ có tần suất xuất hiện lớn nhất trong đoạn văn. Để làm được điều này, ta cần phải thực hiện một bước đó là tokenization (tách từ).
Tách từ là một quá trình xử lý nhằm mục đích xác định ranh giới của các từ trong câu văn, cũng có thể hiểu đơn giản rằng tách từ là quá trình xác định các từ đơn, từ ghép… có trong câu. Đối với xử lý ngôn ngữ, để có thể xác định cấu trúc ngữ pháp của câu, xác định từ loại của một từ trong câu, yêu cầu nhất thiết đặt ra là phải xác định được đâu là từ trong câu. Vấn đề này tưởng chừng đơn giản với con người nhưng đối với máy tính, đây là bài toán rất khó giải quyết.
Đặc biệt đối với tiếng Nhật (cũng như một số ngôn ngữ khác như tiếng Trung, Hàn) vốn không có dấu cách giữa các từ, mà một từ có nghĩa lại được cấu thành từ một hoặc nhiều ký tự, việc tokenization càng trở nên không thể thiếu trong bài toán xử lý ngôn ngữ tự nhiên.
Phần lớn các công cụ tách từ (tokenizer) dùng cho tiếng Nhật đều sử dụng phương thức tokenization dạng lưới (lattice-based). Cụ thể là nó sẽ tạo một lưới (hay cấu trúc dữ liệu dạng đồ thị) bao gồm tất cả các token có khả năng thu được từ input (từ đơn, chuỗi từ), sau đó dùng thuật toán Viterbi để tìm được đường dẫn tối ưu nhất trên lưới này.
Sau khi thực hiện tokenization, spaCy có thể giúp chúng ta thực hiện việc gán nhãn từ loại (pos-tagging), dùng mô hình ngôn ngữ để gán nhãn cho token theo bối cảnh của từng câu. Sau này mình cũng sẽ dùng thông tin này để visualize lên wordcloud.
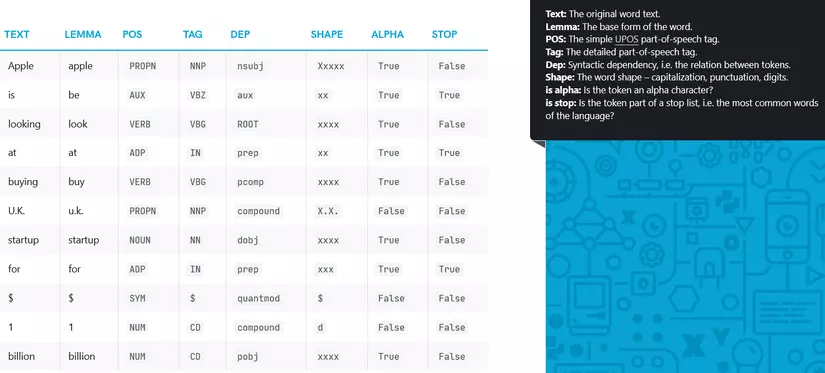
Trong bài viết này mình sẽ sử dụng thư viện spaCy để thực hiện tokenize văn bản. spaCy là một thư viện Python mã nguồn mở, miễn phí dùng để xử lý ngôn ngữ tự nhiên (Natural Language Processing – NLP). spaCy cung cấp nhiều mô hình mạng thần kinh để xử lý ngôn ngữ và nhận dạng thực thể tên, tách từ ở nhiều ngôn ngữ khác nhau, trong đó có cả tiếng Việt.
Cài đặt spaCy:
pip install -U spacy
Với tiếng Nhật, spaCy cung cấp 3 mô hình ngôn ngữ với các component và kích cỡ khác nhau để chúng ta lựa chọn. Các bạn có thể tham khảo thêm tại đây.
Cài đặt và load mô hình ngôn ngữ:
python -m spacy download ja_core_news_sm
import spacy
from spacy.lang.ja.examples import sentences nlp = spacy.load("ja_core_news_sm")
Tách từ và gán nhãn từ loại:
sentence = "この取引所で取引する最も簡単な方法は暗号通貨を預け入れることです。" doc = nlp(sentence) #Tokenization for token in doc: print(token.text, token.pos_, token.lemma_)
(Trong đó, token.pos_ là loại từ, token.lemma_ là nguyên thể - thể từ điển của từ, cái này khá tiện lợi đối với ngôn ngữ như tiếng Nhật, một động từ có thể có cả tá biến thể  )
)
Ta được kết quả như sau:

3. Tìm tần suất của các từ xuất hiện nhiều nhất
Mục đích cuối cùng của mình là tạo ra một chiếc word cloud thống kê tần suất xuất hiện và từ loại của các từ phổ biến trong đoạn văn bản. Vì vậy việc đầu tiên cần làm là thống kê tần suất và từ loại của những từ xuất hiện nhiều nhất.
def create_postag_frequency(text): word_type_pair = {} doc = nlp(text) for token in reversed(doc): if token.is_stop == False and (token.pos_ == 'PROPN' or token.pos_ == 'NOUN' or token.pos_ == 'VERB' or token.pos_ == 'ADJ') and token.lemma_ not in stop_words: if (token.pos_ == 'VERB') and (token.lemma_[len(token.lemma_)-1] not in ['う', 'く', 'す', 'つ', 'ぬ', 'ふ', 'む', 'る', 'ゆ', 'ぐ', 'ず', 'づ', 'ぶ']): token.lemma_ += 'する' if token.pos_ == 'PROPN': token.pos_ = 'NOUN' if (token.lemma_, token.pos_) not in word_type_pair.keys(): word_type_pair[(token.lemma_, token.pos_)] = 1 else: word_type_pair[(token.lemma_, token.pos_)] += 1 return (word_type_pair)
Trong hàm create_postag_frequency mình chỉ chọn giữ lại các danh từ, danh từ riêng, động từ, tính từ, ngoài ra các từ loại khác như trợ động từ, phó từ, vv. và các từ thuộc list stop words thì bỏ qua. Các danh từ riêng được xếp chung với nhóm danh từ.
Các động từ thuộc nhóm 3 trong tiếng Nhật (đuôi する) được thêm する vào để phân biệt với các danh từ cùng gốc. Ví dụ như đoạn văn bản phía trên xuất hiện cả hai từ: 取引 với nghĩa là giao dịch - danh từ và 取引する là động từ mang nghĩa tiến hành giao dịch trao đổi mua bán, thì theo văn cảnh hai từ này sẽ được phân thành hai nhóm là NOUN và VERB.
Kết quả trả về là các cặp từ - loại từ và tần suất xuất hiện của chúng. Nhìn vào đó thì có thể thấy sơ qua được chủ đề chính của văn bản cũng như những nội dung được nhắc đến nhiều. Ta sẽ sắp xếp và lấy 20 từ xuất hiện nhiều nhất:
text = "日本(にほん、にっぽん)は東アジアの島国である。正式な国号は日本国(にほんこく)。国土が南北に広がっていることから南では亜熱帯、北では亜寒帯の気候の地域もあるが、主として温帯に属しているので年間を通じ温暖で安定した気候である。モンスーンの影響もあり、四季の変化に富んでいて季節によって寒暖の差がある。6月から7月にかけて北海道を除く日本の全土は梅雨と呼ばれる雨の多い季節で、9月から10月は台風が到来する季節である。台風が日本に近づくか上陸した場合、航空便は欠航が相次ぎ、鉄道も正常運行されない可能性がある。気象庁では週間天気予報を発表しているので、数日間先の天候を旅行前に確認しておくこともできる。日本(にほん、にっぽん)は東アジアの島国である。正式な国号は日本国(にほんこく)。" word_type_pair = create_postag_frequency(text) import operator
freq = sorted(word_type_pair.items(), key=lambda kv: kv[1], reverse=True)
NUM_WORDCLOUD = 20
freq = freq[:NUM_WORDCLOUD]
Output:

4. Vẽ wordcloud
Trong bài này chúng ta sẽ sử dụng thư viện wordcloud để vẽ đám mây từ khóa.
import matplotlib.pyplot as plt
import wordcloud
from wordcloud import (WordCloud, get_single_color_func)
Class wordcloud.WordCloud có các tham số cần chú ý sau:
- font_path: đường dẫn đến font được sử dụng (file định dạng OTF hoặc TTF), bạn có thể tải về font tiếng Nhật mà mình muốn sử dụng. Nếu dùng font default thì hiển thị sẽ bị lỗi
- height, width: chiều dài, rộng của hình
- prefer_horizontal: float (default=0.90) - tỷ lệ chữ xoay theo chiều ngang/ chiều dọc. Nếu giá trị này bằng 1, tất cả các chữ sẽ được xếp theo chiều ngang. Nếu giá trị <1, thuật toán sẽ xoay dọc chữ để vừa với hình
- mask: mảng binary dùng để vẽ wordcloud theo hình dạng xác định
- background_color, colormap: màu nền, màu chữ
Ngoài ra có một số tham số khác liên quan đến text processing nhưng phần này theo mình chúng ta nên thực hiện trước để customize đúng theo ý muốn rồi mới đưa vào wordcloud. Các bạn có thể tham khảo docs của thư viện nếu muốn tìm hiểu kỹ hơn.
Có thể dùng method generate(text) để tạo wordcloud từ một đoạn text bất kỳ hoặc generate_from_frequencies(frequencies[, …]) tạo worldcloud từ một dictionary gồm các từ khóa và tần suất của chúng. Với trường hợp tiếng Nhật chúng ta dùng cách thứ 2.
# create words' frequencies: {'word1': frequency1, 'word2': frequency2, vv.}
word_freq = {}
for pair in freq: word_freq[pair[0][0]] = pair[1] wc = wordcloud.WordCloud(max_words=NUM_WORDCLOUD, background_color="#FFE6EE", colormap="cividis", font_path=f"{path}TakaoMincho.ttf", prefer_horizontal=0.8, mode="RGB").generate_from_frequencies(word_freq) plt.figure(figsize=(30, 30))
plt.imshow(wc, interpolation="bilinear")
plt.axis("off")
plt.savefig('wordcloud.png')
Kết quả:

Nếu muốn đám mây từ tạo ra tuân theo một hình dạng nào đó, ta có thể thêm vào parameter mask một lớp mask tạo thành từ hình ảnh mong muốn. Ví dụ ở đây mình sẽ tạo mask theo dạng hình tròn cơ bản. Trên thực tế khi tập văn bản lớn, có nhiều từ thì bạn có thể tạo cho nó bất kỳ hình dạng nào 
import numpy as np
# read the mask image
cloud_mask = np.array(Image.open("round.jpg")) # create wordcloud
wc = wordcloud.WordCloud(max_words=NUM_WORDCLOUD, background_color="white", colormap="viridis", font_path=f"{path}TakaoMincho.ttf", mask=cloud_mask, prefer_horizontal=1, mode="RGB").generate_from_frequencies(word_freq) plt.figure(figsize=(40, 20))
plt.imshow(wc, interpolation="bilinear")
plt.axis("off")
plt.savefig('wordcloud.png')

Nếu muốn tô màu các từ khóa theo một quy luật nào đó. Ví dụ như trong bài này mình muốn tô các tính từ bằng màu xanh lá, danh từ là màu xanh dương và động từ là màu đỏ, ta có thể sử dụng method .recolor như sau:
# dictionary which maps color to corresponding key word:
color_to_words = { 'noun': [], 'verb': [], 'adj': []
}
for pair in freq: word_type = pair[0][1].lower() color_to_words[word_type].append(pair[0][0])
color_to_words['#00aedb'] = color_to_words.pop('noun')
color_to_words['#d11141'] = color_to_words.pop('verb')
color_to_words['#00b159'] = color_to_words.pop('adj') class SimpleGroupedColorFunc(object): """Create a color function object which assigns EXACT colors to certain words based on the color to words mapping Parameters ---------- color_to_words : dict(str -> list(str)) A dictionary that maps a color to the list of words. default_color : str Color that will be assigned to a word that's not a member of any value from color_to_words. """ def __init__(self, color_to_words, default_color): self.word_to_color = {word: color for (color, words) in color_to_words.items() for word in words} self.default_color = default_color def __call__(self, word, **kwargs): return self.word_to_color.get(word, self.default_color) wc = wordcloud.WordCloud(max_words=NUM_WORDCLOUD, background_color="white", font_path=f"{path}TakaoMincho.ttf", prefer_horizontal=1, mode="RGB").generate_from_frequencies(word_freq) default_color = 'grey'
grouped_color_func = SimpleGroupedColorFunc(color_to_words, default_color)
wc.recolor(color_func=grouped_color_func) plt.figure(figsize=(40, 20))
plt.imshow(wc, interpolation="bilinear")
plt.axis("off")
plt.savefig('wordcloud.png')

Ngoài ra thì sau khi tạo được wordcloud object là wc thì chúng ta có thể tự tùy chỉnh các attributes của nó theo ý muốn sau đó mới in ra.
Trên đây mình đã giới thiệu với các bạn các bước phân tích văn bản tiếng Nhật và sử dụng kết quả đó để vẽ đám mây từ khóa. Rất mong nhận được sự góp ý của các bạn, đặc biệt là nếu có vấn đề gì khác với văn bản tiếng Nhật thì mình cũng rất mong được cùng trao đổi tại bài này
Cảm ơn các bạn đã đọc!
References: