Mở đầu
Dịch tự động hay còn gọi là dịch máy (tiếng Anh: machine translation) là một nhánh của xử lý ngôn ngữ tự nhiên thuộc phân ngành trí tuệ nhân tạo, nó là sự kết hợp giữa ngôn ngữ, dịch thuật và khoa học máy tính. Như tên gọi, dịch tự động thực hiện dịch một ngôn ngữ này (gọi là ngôn ngữ nguồn) sang một hoặc nhiều ngôn ngữ khác (gọi là ngôn ngữ đích) một cách tự động, không có sự can thiệp của con người trong quá trình dịch.
Lịch sử một số phương pháp dịch máy:
-
Rule-based Machine Translation (RBMT): Tập trung vào các quy tắc giúp chuyển đổi văn bản trong ngôn ngữ nguồn (source) sang ngôn ngữ đích (target) trên các cấp độ: từ vựng, cú pháp hoặc ngữ nghĩa.
Các quy tắc thường do nhà ngôn ngữ học phát triển. Do vậy hạn chế chính của phương pháp này là nó đòi hỏi rất nhiều nguồn lực về chuyên môn/ chuyên gia (có thể rất tốn kém) để xây dựng rất rất nhiều quy tắc và ngoại lệ, đồng thời nó không khái quát được cho những ngôn ngữ khác.
-
Statistical machine translation (SMT): sử dụng các mô hình thống kê (statistical model) học cách dịch văn bản từ ngôn ngữ nguồn sang ngôn ngữ đích dựa trên một bộ ngữ liệu (corpus) lớn.
Ý tưởng đằng sau dịch máy thống kê đến từ lý thuyết thông tin. Tài liệu được dịch theo phân bố xác suất trong đó là ngôn ngữ đích (ví dụ, Tiếng Việt) dịch từ là ngôn ngữ nguồn (ví dụ, Tiếng Nhật).
Các vấn đề của mô hình phân phối xác suất được tiếp cận theo một số cách. Một cách tiếp cận trực quan là áp dụng định lý Bayes, đó là , trong đó là xác suất để chuỗi nguồn là bản dịch của chuỗi đích , xác suất này gọi là mô hình dịch, và là xác suất chuỗi e thực sự xuất hiện trong ngôn ngữ đích, xác suất này gọi là mô hình ngôn ngữ. Phân tích này giúp tách các vấn đề thành hai bài toán con. Bản dịch tốt nhất được tìm bằng cách chọn ra bản có xác suất cao nhất:

Để áp dụng phương pháp này một cách đầy đủ, cần thực hiện việc tìm kiếm trên tất cả các chuỗi của ngôn ngữ đích. Khối lượng tìm kiếm này rất lớn, và nhiệm vụ thực hiện tìm kiếm hiệu quả là công việc của một bộ giải mã dịch máy, sử dụng nhiều kỹ thuật để hạn chế không gian tìm kiếm nhưng vẫn giữ chất lượng dịch thuật chấp nhận được.
Mặc dù hiệu quả, phương pháp này tập trung chủ yếu vào các cụm từ mà bỏ qua hàm nghĩa rộng hơn của văn bản. Đồng thời việc tiếp cận theo hướng dữ liệu (data-driven) cũng có nghĩa là mô hình có khả năng đã bỏ qua những đặc điểm về cú pháp trong ngôn ngữ.
-
Neural machine translation (NMT): sử dụng các mô hình neural network để học một mô hình thống kê cho quá trình dịch máy. Với phương pháp này, người ta chỉ cần huấn luyện một hệ thống duy nhất trên tập văn bản nguồn và văn bản đích (end-to-end system), không cần phải xây dựng một pipeline gồm các hệt thống chuyên biệt giống như SMT, không cần phải có nhiều kiến thức chuyên môn về ngôn ngữ, nhờ vậy mà có thể áp dụng cho các cặp ngôn ngữ khác nhau khá dễ dàng.
Trong bài này mình sẽ xây dựng một chương trình dịch máy NMT từ tiếng Nhật sang tiếng Việt sử dụng mô hình Encoder-Decoder cơ bản.
Machine translation là một bài toán sequence-to-sequence (seq2seq) điển hình do nó có đầu vào là một chuỗi (sequence) và đầu ra cũng là một chuỗi. Một thách thức của bài toán này là độ dài của chuỗi đầu vào và chuỗi đầu ra biến đổi liên tục và không giống nhau. Một trong những cách tiếp cận hiệu quả đó là Encoder-Decoder LSTM.
Hệ thống này bao gồm 2 model:
- Model thứ nhất được gọi là Encoder, chịu trách nhiệm nhận chuỗi đầu vào (input sequence) và mã hóa (encode) nó thành một vector có độ dài cố định
- Model thứ hai là Decoder có nhiệm vụ giải mã (decode) vector trên và dự đoán chuỗi đầu ra.
1. Dataset
Trong bài này mình sử dụng bộ data: Tatoeba corpus from OPUS project gồm hơn 2000 cặp câu Nhật - Việt. Ngoài ra trong repo này có khá nhiều bộ dataset nữa được tổng hợp và chỉnh lý từ các nguồn khác nhau, các bạn có thể tham khảo thêm: https://github.com/ngovinhtn/JaViCorpus/
# read data
import string
vi_input = []
with open(f"{path}vi_data.txt") as f: for line in f: line = line.replace(' ', ' ').lower() vi_input.append(line.strip()) ja_input = []
with open(f"{path}ja_data.txt") as f: for line in f: ja_input.append(line.strip()) for i in zip(ja_input[:5], vi_input[:5]): print(i)
Output:
('私は眠らなければなりません。', 'tôi phải đi ngủ .')
('何してるの?', 'bạn đang làm gì đây ?')
('今日は6月18日で、ムーリエルの誕生日です!', 'hôm nay là ngày 18 tháng sáu , và cũng là ngày sinh nhật của muiriel !')
('お誕生日おめでとうムーリエル!', 'chúc mừng sinh nhật , muiriel !')
('ムーリエルは20歳になりました。', 'bây giờ muiriel được 20 tuổi .')
2. Data Preprocessing
Giống như những bài toán về NLP khác, các bước tiền xử lý dữ liệu cần thực hiện là:
-
Tokenization: tách câu thành các từ có nghĩa. Do đặc thù của tiếng Việt là một từ có thể được cấu tạo bởi nhiều tiếng, còn tiếng Nhật lại không có dấu cách giữa các chữ nên mình không thể tokenize giống tiếng Anh bằng cách dựa vào khoảng trắng giữa các chữ được. Hiện đã có rất nhiều bộ tokenizer dành riêng cho hai thứ tiếng. Trong bài này mình sẽ sử dụng thư viện
pyvicho tiếng Việt vàspacycho tiếng Nhật.!pip install pyvi !pip install -U pip setuptools wheel !pip install -U spacy !python -m spacy download ja_core_news_sm# Thêm token đánh dấu điểm bắt đầu và kết thúc của câu vào mỗi câu trong ngôn ngữ đích eos = '<eos>' bos = '<bos>' from pyvi import ViTokenizer vi_input_tokenize = [ViTokenizer.tokenize(i).split() for i in vi_input] for i in range(len(vi_input_tokenize)): vi_input_tokenize[i].insert(0, bos) vi_input_tokenize[i].insert(len(vi_input_tokenize[i]), eos) import spacy nlp = spacy.load("ja_core_news_sm") ja_input_tokenize = [[] for i in range(len(ja_input))] for i in range(len(ja_input)): doc = nlp(ja_input[i]) for token in doc: ja_input_tokenize[i].append(str(token)) -
Tạo một bộ từ vựng cho các từ có trong corpus, trong đó mỗi từ sẽ có một index tương ứng. Ở bước này mình dùng class
Tokenizercủa TF Keras.from tensorflow.keras.preprocessing.text import Tokenizer ja_tokenizer = Tokenizer(oov_token = '<oov>') ja_tokenizer.fit_on_texts(ja_input_tokenize) ja_vocabulary = ja_tokenizer.word_index ja_size = len(ja_vocabulary) print(ja_vocabulary) print(ja_size) # number of words in the vocabulary vi_tokenizer = Tokenizer() vi_tokenizer.fit_on_texts(vi_input_tokenize) vi_vocabulary = vi_tokenizer.word_index vi_size = len(vi_vocabulary) print(vi_vocabulary) print(vi_size)Output:
{'<oov>': 1, '。': 2, 'は': 3, 'の': 4, 'に': 5, 'た': 6, 'を': 7, ..., '資金': 1994, '広く': 1995, '投資': 1996} 1996 {'<bos>': 1, '<eos>': 2, '.': 3, 'tôi': 4, 'không': 5, 'anh': 6, '?': 7, 'bạn': 8, ..., 'kêu_gọi': 1632, 'đầu_tư': 1633, 'kinh_phí': 1634} 1634Tạo một bộ từ vựng để tra ngược lại (từ index -> từ):
ja_vocabulary_reverse = {} for key, value in ja_tokenizer.word_index.items(): ja_vocabulary_reverse[value] = key ja_vocabulary_reverse[0] = '' vi_vocabulary_reverse = {} for key, value in vi_tokenizer.word_index.items(): vi_vocabulary_reverse[value] = key vi_vocabulary_reverse[0] = '' print(ja_vocabulary_reverse) print(vi_vocabulary_reverse)Output:
{1: '<oov>', 2: '。', 3: 'は', 4: 'の', 5: 'に', 6: 'た', 7: 'を', ...} {1: '<bos>', 2: '<eos>', 3: '.', 4: 'tôi', 5: 'không', 6: 'anh', 7: '?', 8: 'bạn', ...} -
Mã hóa các câu đầu vào thành các chuỗi dựa trên index của bộ từ vựng vừa tạo, thực hiện padding để có các chuỗi độ dài bằng nhau.
from tensorflow.keras.preprocessing.sequence import pad_sequences ja_sequence = ja_tokenizer.texts_to_sequences(ja_input_tokenize) jamaxlen = max([len(i) for i in ja_sequence]) ja_sequence = pad_sequences(ja_sequence, maxlen = jamaxlen, padding = 'post') print(ja_sequence[0]) vi_sequence = vi_tokenizer.texts_to_sequences(vi_input_tokenize) vimaxlen = max([len(i) for i in vi_sequence]) vi_sequence = pad_sequences(vi_sequence, maxlen = vimaxlen, padding = 'post') print(vi_sequence[0])Output:
[ 10 3 780 98 62 84 43 28 2 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0] [ 1 4 29 21 133 3 2 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
3. Train/ test split, Generate batch
split_ratio = 0.9
split = round(len(vi_sequence)* split_ratio)
trainX = ja_sequence[:split]
testX = ja_sequence[split:]
trainY = vi_sequence[:split]
testY = vi_sequence[split:] train_samples = len(trainX)
val_samples = len(testX)
batch_size = 128
epochs = 200
latent_dim=128
Tạo data để đưa vào mô hình encoder-decoder:
Do lượng dữ liệu khá lớn để có thể load toàn bộ vào trong bộ nhớ, ta sẽ tạo một hàm generate các batch dữ liệu để pass vào mô hình bằng fit_generator()
def generate_batch(X, y, batch_size): while True: for j in range(0, len(X), batch_size): encoder_input_data = [] decoder_input_data = [] decoder_target_data = [] for i, (input_text, target_text) in enumerate(zip(X[j:j+batch_size], y[j:j+batch_size])): encoder_input_data.append(input_text) decoder_input_data.append(target_text) decodertargetdata = to_categorical(target_text, num_classes=vi_size+1)[1:] decoder_target_data.append(np.concatenate((np.array(decodertargetdata), np.zeros((1, vi_size+1))), axis = 0)) encoder_input_data = np.array(encoder_input_data) decoder_input_data = np.array(decoder_input_data) decoder_target_data = np.array(decoder_target_data) yield([encoder_input_data, decoder_input_data], decoder_target_data)
Để train mô hình encoder - decoder sequence to sequence, ta cần 3 mảng np.array như sau:
- encoder inputs: sequence của câu tiếng Nhật, đầu vào cho encoder, shape: (batch_size, jamaxlen)
- decoder inputs: sequence của câu tiếng Việt, đầu vào cho decoder, shape: (batch_size, vimaxlen)
- decoder outputs: decoder inputs sau khi đã onehot encoded, shape: (batch_size, vimaxlen, vi_size + 1) (+1 do chuỗi đã được zero-padded -> có thêm số 0). Lưu ý, với mỗi câu, decoder output sẽ sớm hơn 1 bước timestep so với decoder input. Tức là, nếu input là token ở vị trí thứ t thì output predict ra phải là token tiếp theo của nó, tức là t+1.
4. Xây dựng model
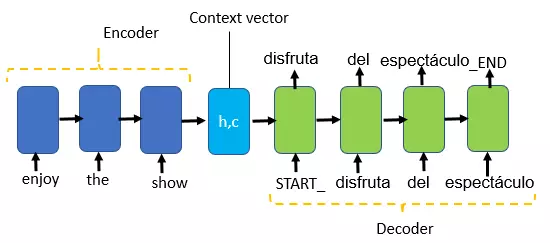
Encoder:
Encoder làm nhiệm vụ mã hóa chuỗi đầu vào thành một vector có độ dài cố định. Bao gồm các layer sau:
- Input layer: encode_input_data
- Embedding layer: đưa các sparse vector về dạng dense vector với số chiều thấp hơn. Các parameter: số từ trong bộ từ vựng, số chiều của vector sau khi embedded, mask_zero = True để mask out - bỏ qua phần zero padding trong input
- LSTM layer: set
return_state = Trueđể lấy hidden state và cell state của encoder. Các state này sau đó sẽ được pass vào decoder.
# Define an input sequence and process it.
encoder_inputs = Input(shape=(None,))
enc_emb = Embedding(ja_size+1, latent_dim, mask_zero = True)(encoder_inputs)
encoder_lstm = LSTM(latent_dim, return_state=True)
encoder_outputs, state_h, state_c = encoder_lstm(enc_emb)
# We discard `encoder_outputs` and only keep the states.
encoder_states = [state_h, state_c]
Decoder:
Gồm các layer:
- Input layer: decoder_input_data
- Embedding layer
- LSTM layer: nhận đầu vào từ embedding layer và encoder states. Set
return_seq=Truevì ta cần decoder output sau mỗi timestep để predict token tiếp theo. Setreturn_state=Trueđể lấy internal state dùng khi inference. - Dense layer: số node là số lượng từ vựng trong ngôn ngữ đích, hàm kích hoạt là softmax để predict ra token tiếp theo sau mỗi timestep.
# Set up the decoder, using `encoder_states` as initial state.
decoder_inputs = Input(shape=(None,))
dec_emb_layer = Embedding(vi_size+1, latent_dim, mask_zero = True)
dec_emb = dec_emb_layer(decoder_inputs)
# We set up our decoder to return full output sequences,
# and to return internal states as well. We don't use the
# return states in the training model, but we will use them in inference.
decoder_lstm = LSTM(latent_dim, return_sequences=True, return_state=True)
decoder_outputs, _, _ = decoder_lstm(dec_emb, initial_state=encoder_states)
decoder_dense = Dense(vi_size+1, activation='softmax')
decoder_outputs = decoder_dense(decoder_outputs)
Compile và run model:
model = Model([encoder_inputs, decoder_inputs], decoder_outputs)
model.compile(optimizer=RMSprop(learning_rate=0.001), loss='categorical_crossentropy', metrics=['acc'])
model.fit_generator(generator = generate_batch(trainX, trainY, batch_size = batch_size), steps_per_epoch = train_samples//batch_size, epochs=epochs, validation_data = generate_batch(testX, testY, batch_size = batch_size), validation_steps = val_samples//batch_size, )
Kết quả:
Epoch 200/200
14/14 [==============================] - 11s 819ms/step - loss: 0.0049 - acc: 0.9980 - val_loss: 0.4400 - val_acc: 0.7955
5. Inference
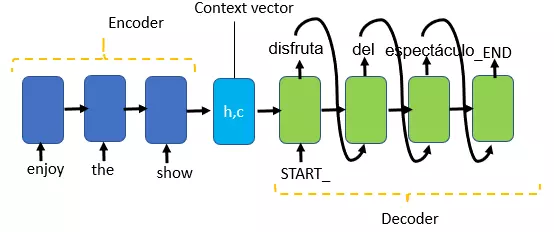
Các bước inference:
- Truyền chuỗi đầu vào vào mô hình encoder để lấy ra hidden state và cell state của mạng LSTM
- Mô hình decoder sẽ predict ra từng token một. Input trong bước đầu tiên của decoder là hidden state + cell state của encoder (hay còn gọi là context vector) và token bắt đầu câu <bos>
- Token output của decoder sẽ được truyền vào như input của decoder trong time step tiếp theo.
- Trong mỗi time step, decoder sẽ trả ra một one-hot encoded vector. Ta áp dụng hàm np.argmax để lấy ra chỉ số của token và convert ngược lại về từ trong ngôn ngữ đích.
- Lặp lại đến khi gặp token kết thúc câu <eos> hoặc vượt quá số lượng từ.
Define inference model
# Encode the input sequence to get the "Context vectors"
encoder_model = Model(encoder_inputs, encoder_states) # Decoder setup
# Below tensors will hold the states of the previous time step
decoder_state_input_h = Input(shape=(latent_dim,))
decoder_state_input_c = Input(shape=(latent_dim,))
decoder_state_input = [decoder_state_input_h, decoder_state_input_c]
# Get the embeddings of the decoder sequence
dec_emb2= dec_emb_layer(decoder_inputs) # To predict the next word in the sequence, set the initial states to the states from the previous time step
decoder_outputs2, state_h2, state_c2 = decoder_lstm(dec_emb2, initial_state=decoder_state_input)
decoder_states2 = [state_h2, state_c2] # A dense softmax layer to generate prob dist. over the target vocabulary
decoder_outputs2 = decoder_dense(decoder_outputs2) # Final decoder model
decoder_model = Model( [decoder_inputs] + decoder_state_input, [decoder_outputs2] + decoder_states2)
Inference lookup
def decode_sequence(input_seq): # Encode the input as state vectors. states_value = encoder_model.predict(input_seq) # Generate empty target sequence of length 1. target_seq = np.zeros((1,1)) # Populate the first character of target sequence with the start character. target_seq[0, 0] = vi_vocabulary[bos] # Sampling loop for a batch of sequences (to simplify, here we assume a batch of size 1). stop_condition = False decoded_sentence = '' # greedy search while not stop_condition: output_tokens, h, c = decoder_model.predict([target_seq] + states_value) # print(output_tokens) # Sample a token sampled_token_index = np.argmax(output_tokens[0, -1, :]) # print(sampled_token_index) sampled_word =vi_vocabulary_reverse[sampled_token_index] decoded_sentence += ' '+ sampled_word # Exit condition: either hit max length or find stop character. if (sampled_word == eos or len(decoded_sentence) > 100): stop_condition = True # Update the target sequence (of length 1). target_seq = np.zeros((1,1)) target_seq[0, 0] = sampled_token_index # Update states states_value = [h, c] return decoded_sentence
Thử in ra một vài kết quả trong tập test nào:
test_gen = generate_batch(testX, testY, batch_size = 1)
(input_seq, actual_output), _ = next(test_gen)
decoded_sentence = decode_sequence(input_seq)
print('Input Source sentence:', ''.join([ja_vocabulary_reverse[i] for i in input_seq[0]]))
print('Actual Target Translation:', ' '.join([vi_vocabulary_reverse[i] for i in actual_output[0]]))
print('Predicted Target Translation:', decoded_sentence)
Input Source sentence: あなたはいつからラテン語を勉強しましたか。
Actual Target Translation: <bos> anh học tiếng la - tinh từ bao_giờ ? <eos> Predicted Target Translation: anh học tiếng la - tinh từ bao_giờ ? <eos>
Input Source sentence: 私は彼の威嚇をぜんぜん怖くない。
Actual Target Translation: <bos> tôi hoàn_toàn không sợ những sự đe_dọa của hắn . <eos> Predicted Target Translation: tôi hoàn_toàn không sợ những sự đe_dọa của hắn . <eos>
Input Source sentence: 私の弟は上手にギターを弾けます。
Actual Target Translation: <bos> em_trai tôi chơi ghi - ta rất giỏi . <eos> Predicted Target Translation: em_trai tôi chơi ghi - ta rất giỏi . <eos>
Input Source sentence: 豚は小屋にいない。
Actual Target Translation: <bos> lợn không có ở trong chuồng . <eos> Predicted Target Translation: tôi không nghĩ như_vậy . <eos>
Input Source sentence: 彼は彼女にチョコレートを買ってあげた。
Actual Target Translation: <bos> anh ta đã mua cho cô ấy sô cô la . <eos> Predicted Target Translation: anh ấy đã thổ_lộ là thích tôi . <eos>
Input Source sentence: 私は彼が野球をするのを見た。
Actual Target Translation: <bos> tôi đã xem anh ấy chơi bóng_chày . <eos>
Predicted Target Translation: tôi đã xem anh ấy chơi bóng_chày . <eos>
Input Source sentence: 遅れてごめん。
Actual Target Translation: <bos> xin_lỗi tôi đến trễ . <eos>
Predicted Target Translation: xin_lỗi tôi đến trễ . <eos>
Kết luận:
Từ một số kết quả in ra ở trên có thể thấy mô hình của chúng ta đã dự đoán khá ổn cho phần lớn các câu. Kể cả với những câu dự đoán sai thì câu output cũng có ý nghĩa.
Như vậy trong bài này mình đã giới thiệu các bước để xây dựng một mô hình dịch máy cơ bản cho tiếng Nhật -> tiếng Việt. Ở bài tiếp theo mình sẽ tiếp tục cải thiện mô hình này. Cảm ơn các bạn đã đọc và nếu có góp ý, câu hỏi gì các bạn có thể trao đổi thêm ở comment nhé!
Reference
https://machinelearningmastery.com/introduction-neural-machine-translation/
https://vi.wikipedia.org/wiki/Dịch_máy_thống_kê
https://blog.keras.io/a-ten-minute-introduction-to-sequence-to-sequence-learning-in-keras.html
https://towardsdatascience.com/implementing-neural-machine-translation-using-keras-8312e4844eb8