1. MỞ ĐẦU
Công nghệ chuyển đổi giọng nói thành văn bản (Speech to Text - STT) hoặc nhận dạng giọng nói tự động (ASR) đang được áp dụng rất nhiều trong các ứng dụng thông minh, từ chat bot trợ lý ảo đến dịch vụ tự động hóa cuộc gọi và phân tích dữ liệu giọng nói. Các công cụ STT không chỉ giúp chuyển đổi giọng nói thành văn bản nhanh chóng mà còn cải thiện khả năng hiểu ngôn ngữ tự nhiên của máy móc.
Trong bài viết này, chúng ta sẽ khám phá một số mô hình Speech to Text nổi bật hiện nay như Whisper của OpenAI (open source), và Deepgram Nova của Deepgram (close source), đồng thời tìm hiểu cách triển khai.
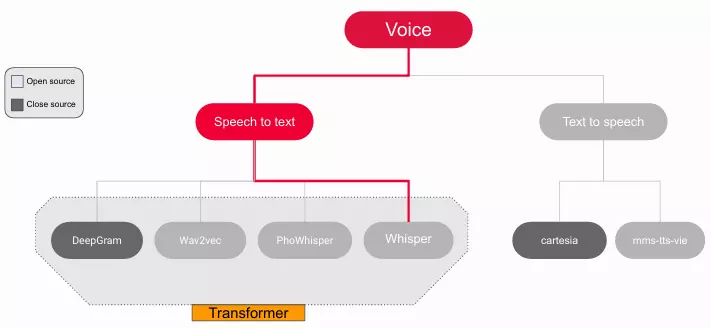
2. MỘT SỐ MÔ HÌNH SPEECH TO TEXT
2.1 Whisper
2.1.1 Whisper là gì ?
Whisper là một hệ thống nhận dạng giọng nói tự động (ASR) mã nguồn mở do OpenAI phát triển và giới thiệu vào cuối năm 2022 với khả năng nhận diện và xử lý âm thanh đa ngôn ngữ cùng với tốc độ và độ chính xác vượt trội. Làm nền tảng cho việc xây dựng các ứng dụng hữu ích và nghiên cứu sâu hơn về xử lý giọng nói.
2.1.2 Whisper hoạt động ra sao?
Whisper được đào tạo từ 680.000 giờ dữ liệu âm thanh được giám sát đa ngôn ngữ và đa nhiệm được thu thập từ internet. Hơn nữa, nó cho phép phiên âm bằng nhiều ngôn ngữ (98 ngôn ngữ bao gồm tiếng Việt), cũng như dịch từ các ngôn ngữ khác nhau. Whisper sử dụng mô hình "sequence-to-sequence", khi nhận vào giọng nói Whisper sẽ mã hóa âm thanh thành các đoạn dữ liệu (vector), sau đó sử dụng kiến trúc Transformer để giải mã thành văn bản.
2.1.3 Kiến trúc mô hình Whisper
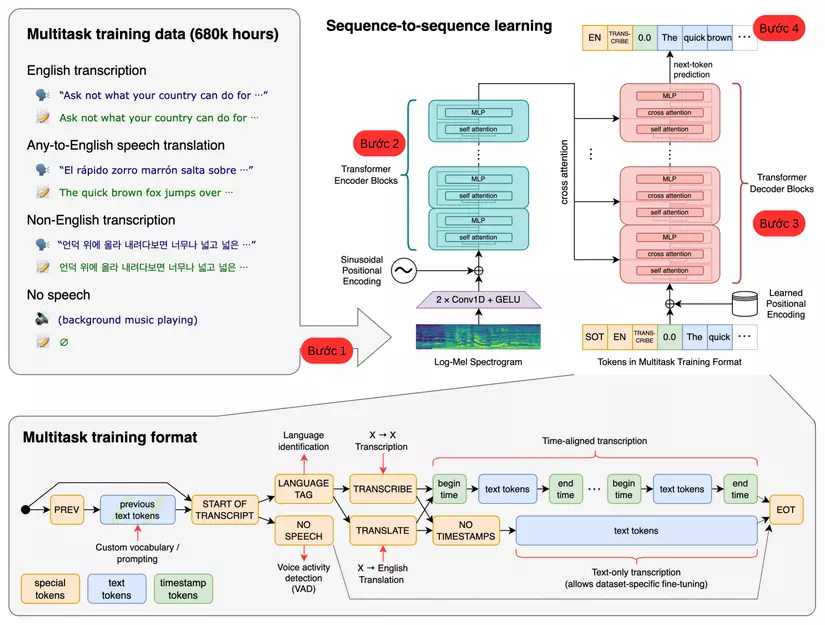
Sau đây mình sẽ tạm chia mô hình thành 4 bước để các bạn dễ hình dung:
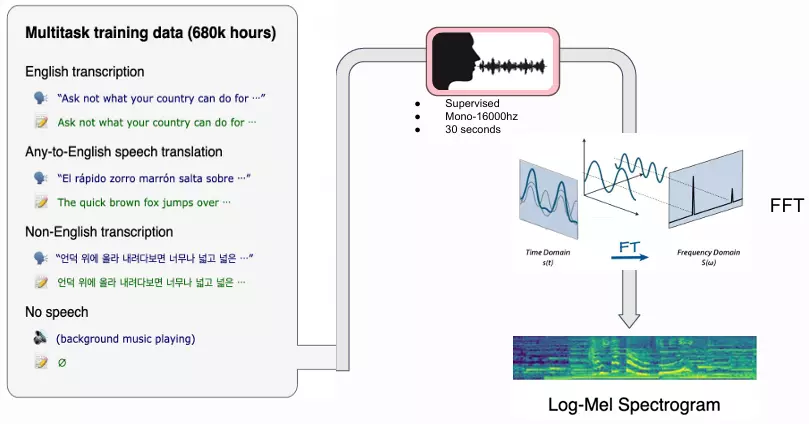
Bước 1: Xử lý âm thanh:
Dữ liệu đầu vào để train mô hình gồm dữ liệu âm thanh gắn nhãn được chuyển về dạng đơn kênh (Mono) và miền tần số 16000hz. Âm thanh sau đó được cắt thành đoạn mỗi 30 giây, đối với những đoạn âm thanh ngắn hơn 30 giây sẽ được đệm thêm khoảng lặng để phù hợp với mô hình. Tiếp theo áp dụng biến đổi Fourier Transform (cụ thể là Fast Fourier Transform các bạn có thể tham khảo thêm ở bài đọc) chuyển đổi thành quang phổ log-Mel bản chất cũng là các đoạn dữ liệu vector và sau đó được truyền vào bộ mã hóa. Bộ mã hóa và giải mã (Encoder and Decoder) được dựa trên kiến trúc Transformer.
Bước 2: Encoder:
Phần đầu tiên của mô hình là bộ mã hóa Encoder. Đây là phần chịu trách nhiệm xử lý âm thanh và trích xuất một đặc trưng cho những gì được nói trong các phân đoạn âm thanh. Nó bao gồm các phần sau:
- 2 x Conv1d và GELU activation function: dùng để trích xuất các đặc trưng từ log-Mel spectrogram đầu vào.
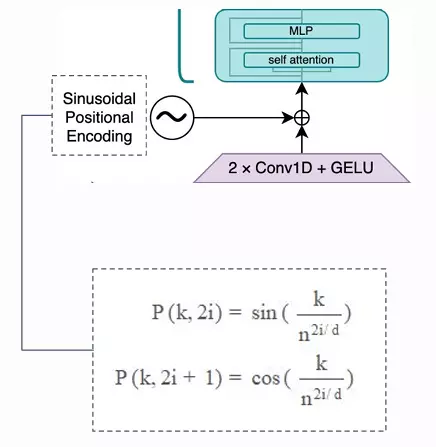
- Positional Embedding: Whisper sử dụng sinusoidal positional embedding cho phép mã hóa vị trí và vị trí của từng token và vị trí tương đối của từng token với nhau.
- Encoder block:
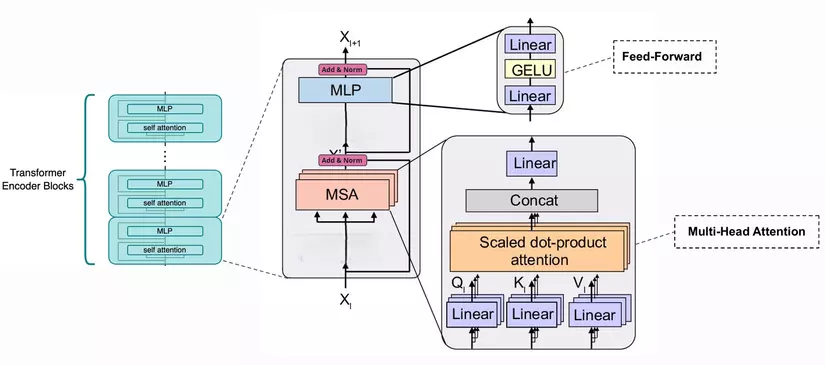
Một Encoder block tiêu chuẩn bao gồm multi-headed self attention layer và feed-forward layer với layer normalization và GELU activation function.
Multi-Head Attention Hạn chế ảnh hưởng của Global Attention trong việc trung hòa mối quan hệ giữa các từ với nhau trong nhiều phương diện. Multi-Head Attention sẽ chia nhỏ từng ma trận trong các ma trận Q , K và V thành h phần. Sau đó, Scale Dot-Product Attention và các kết quả sẽ được tổng hợp lại.
Scale Dot-Product Attention tập trung vào các phần thông tin quan trọng hơn trong dữ liệu, Xử lý tốt các mối quan hệ ngữ nghĩa trong dãy dữ liệu, Tăng khả năng học các mối quan hệ dài hạn trong dữ liệu dãy
Add & Norm layer Lớp này đơn giản là sẽ chuẩn hóa lại đầu ra của multi-head attention, mang lại hiệu quả cho việc nâng cao khả năng hội tụ.
Kết nối Residual Giảm thiểu vấn đề vanishing gradient, đảm bảo rằng các biểu diễn theo ngữ cảnh của các token đầu vào thực sự đại diện cho các token.
Feed-Forward Network (FFN) Khối FFN này sẽ có cấu trúc tương tự như trong các mô hình Transformer khác, bao gồm hai lớp tuyến tính và một hàm kích hoạt phi tuyến GELU ở giữa.
Bước 3: Decoder:
Phần giải mã của mô hình là bộ giải mã Decoder: Đây là phần chịu trách nhiệm tạo văn bản (phiên âm hoặc dịch). Whisper sử dụng một bộ giải mã khá chuẩn có thể được tìm thấy trong nhiều kiến trúc decoder transformer. Nó bao gồm các phần sau:
Multitask training format Định dạng đào tạo đa nhiệm. Đây là định dạng đơn giản để chỉ định tất cả các tác vụ và thông tin dưới dạng một chuỗi các mã thông báo đầu vào (input tokens) cho bộ giải mã Decoder. Các token này bao gồm một tag chỉ định ngôn ngữ (ví dụ như en hoặc vi), tác vụ là transcript hay là translate. Điều này cho phép mô hình, khá khéo léo, có khả năng xử lý nhiều tác vụ NLP khác nhau.
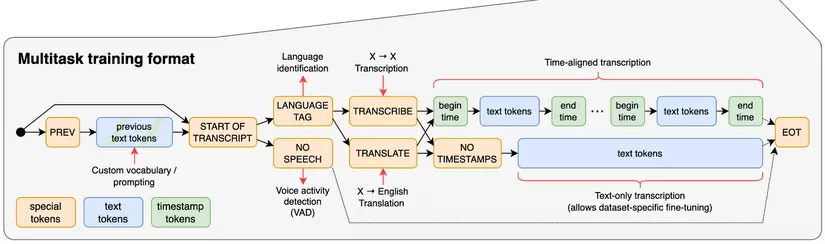
- Prev (Previous tokens): Đây là các mã thông báo (tokens) đầu vào của mô hình, bao gồm các tokens trước đó mà mô hình đã xử
- Prev text tokens: Đây là các text tokens trước đó đã được giải mã.
- Start of transcript (Bắt đầu phiên âm): mô hình sẽ xác định các thông tin ban đầu như ngôn ngữ của âm thanh và quyết định tiếp tục với việc dịch hoặc phiên âm.
- Language tag : sử dụng để hướng dẫn mô hình xử lý âm thanh theo ngôn ngữ tương ứng
- Transcribe: Chuyển tín hiệu âm thanh thành văn bản (text) cùng ngôn ngữ
- Translate: Dịch tín hiệu âm thanh từ ngôn ngữ này sang Tiếng Anh.
- Voice Activity Detection :Khối này xác định xem có giọng nói trong tín hiệu âm thanh hay không. Nếu không phát hiện giọng nói, mô hình sẽ không thực hiện phiên âm cho đoạn đó và chuyển thẳng đến điểm cuối (EOT).
- Time-aligned transcription: Quá trình này tạo ra một dạng phiên âm kèm dấu thời gian, mô hình sẽ thêm các special tokens chỉ định begin time và end time của từng đoạn văn bản được phiên âm.
- Text-only transcription :mô hình sẽ chỉ tạo ra các text tokens mà không kèm dấu thời gian, tức là chỉ xuất hiện văn bản không kèm theo thông tin thời gian bắt đầu/kết thúc của từng cụm từ.
- EOT (End of Transcript): kết thúc quá trình phiên âm hoặc dịch, mô hình đã hoàn tất nhiệm vụ và không có token hoặc dữ liệu nào khác cần xử lý.
Positional Embedding
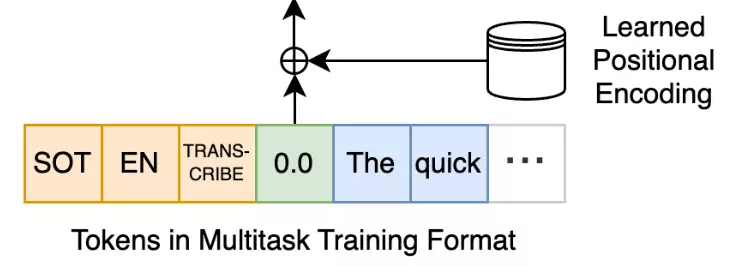
Whisper sử dụng learned positional embedding cho decoder block. Từng token được được biểu diễn bằng vector có thể học được trong quá trình huấn luyện tương tự như cách học embedding cho từng
Decoder block Khối giải mã chuẩn bao gồm Masked-Multi Head Attention, feed-forward layer và các lớp cross-attention với layer normalization và GELU activation function.
Tại sao lại dùng cross-Attention chứ không dùng Multi Head Attention ?
Cross-Attention đóng vai trò như một cơ chế để Decoder “nhìn vào” các đặc trưng ngữ nghĩa của âm thanh từ Encoder tại mỗi bước dự đoán. Điều này giúp Decoder có thể dự đoán các từ tiếp theo trong văn bản dựa trên cả ngữ cảnh âm thanh và ngữ cảnh ngôn ngữ.
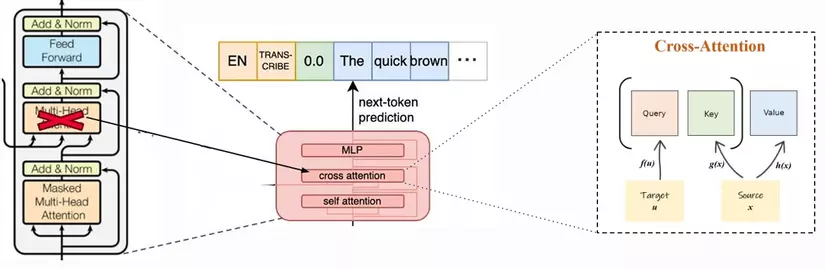
Bước 4 Lấy token đầu ra: Thêm token được dự đoán vào chuỗi token dự đoán
Ví Dụ:
-
Bắt đầu với token [|<EN>|, |<TRANSCRIBE>|, |<0.0>|, token được dự đoán là |<”The”>| thì chuỗi token được dự đoán hiện tại sẽ là [|<EN>|, |<TRANSCRIBE>|, |<0.0>|, |<”The”>|]
-
Chuyển chuỗi này (cùng với audio Encoding) đến Decoder:
Chuỗi token là [|<EN>|, |<TRANSCRIBE>|, |<0.0>|, |<”The”>|], cùng audio Encoding sẽ đi vào Decoder
-
Có được phân phối xác suất trên tất cả các token
Với chuỗi đầu vào [|<EN>|, |<TRANSCRIBE>|, |<0.0>|, |<”The”>|] mô hình có thể trả về xác suất phân phối:
Token xác suất phân phối “quick” 0,7 “brown” 0,1 “man” 0,05 “girl” 0,15 -
Lấy một mẫu token từ bản phân phối này
token |<”quick”>| có xác xuất cao nhất 0,7 sẽ được chọn làm token tiếp theo
-
Lặp lại các bước 1-4 cho đến khi tạo ra toàn bộ âm thanh hoàn chỉnh hoặc gặp dấu hiệu kết thúc |<”eos”>|
chuỗi token hiện tại là [|<EN>|, |<TRANSCRIBE>|, |<0.0>|, |<”The”>|, |<”quick”>|] và tiếp tục lặp lại các bước đến khi tạo ra câu hoàn chỉnh. Chuỗi có có thể có định dạng là [|<EN>|, |<TRANSCRIBE>|, |<0.0>|, |<”The”>|, |<”quick”>|, |<”fox”>|, |<”eos”>|]
Mình sẽ không đi sâu vào việc giải thích chi tiết những khâu nhỏ trong mô hình Whisper mà chỉ tập trung khái quát tổng quan. Nói chung đây là một tóm tắt nhanh quy trình:
- Bắt đầu với một đoạn âm thanh
- Xử lý trước đoạn âm thanh bằng cách đệm (hoặc cắt ngắn) đến 30 giây
- Xử lý nó để có được các đặc trưng âm thanh
- Chuyển các đặc trưng âm thanh cho bộ mã encoder để lấy âm thanh đã được mã hóa
- Âm thanh đã mã hóa sẽ chuyển đến bộ giải mã decoder để có được văn bản dự đoán (bằng cách lấy mẫu từ đầu ra của bộ giải mã)
2.2 Deepgram Nova
Deepgram Nova là công cụ API Speech to text hàng đầu trên thị trường tạo ra bởi Deepgram cũng dựa trên kiến trúc Transformer. Năm 2023 mô hình phiên âm - Deepgram Nova-2 được ra mắt, mặc dù là close source nhưng lại là công cụ cực kì mạnh mẽ cho các tác vụ Speech to text.
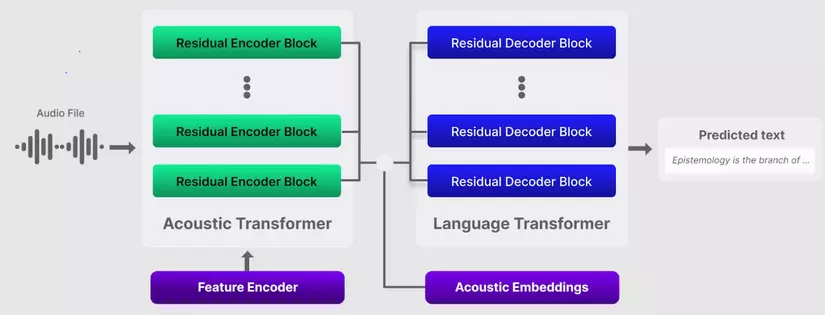
Kiến trúc Transformer của Deepgram Nova-2 đã được tối ưu hóa bằng cách sử dụng các thuật toán mô tả kiến trúc độc quyền để tăng độ chính xác phiên dịch mã mà không làm ảnh hưởng đến tốc độ suy luận. Vì thế tốc độ suy luận của Deepgram Nova-2 đạt trung bình 29,8 giây cho mỗi giờ âm thanh, tỉ lệ lỗi từ WER trung bình đạt 8,4% và chi phí API 0,0043$ cho mỗi phút âm thanh.
Để trực quan hơn so sánh với Whisper bằng hình sau:
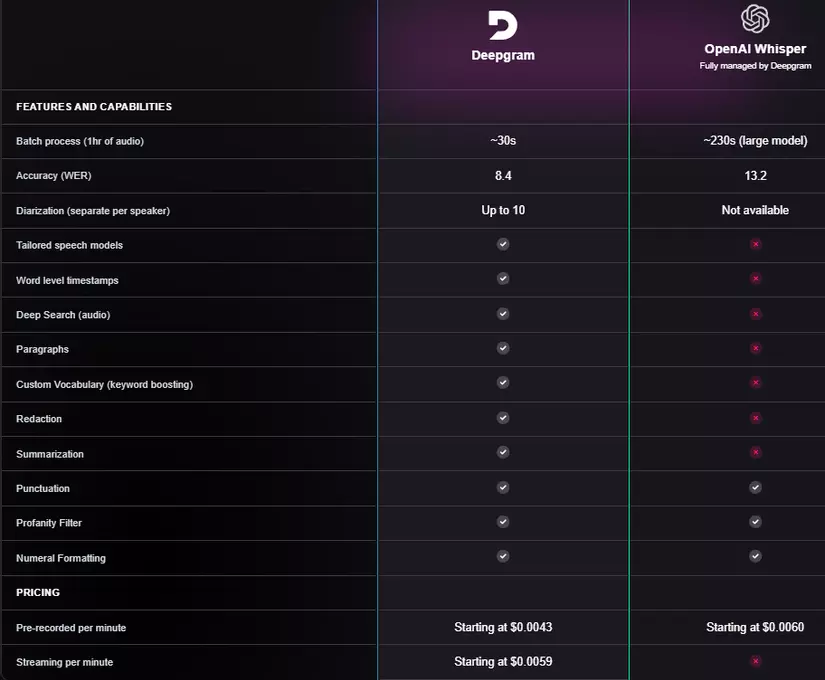
3. TRIỂN KHAI BÀI TOÁN
Mình sử dụng GPU T4 trên Google Colab trong toàn bộ quá trình triển khai.
3.1 Whisper-Large-v3-Turbo
- Cài đặt thư viện:
!pip install git+https://github.com/huggingface/transformers gradio
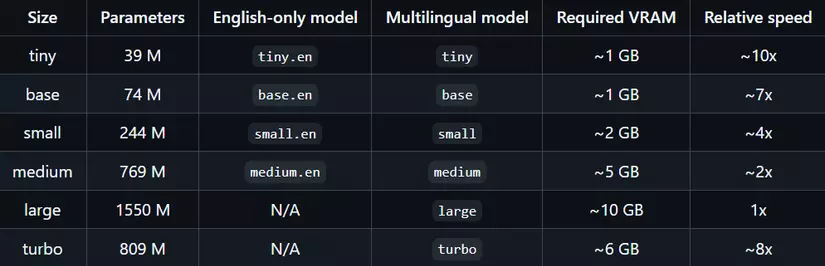
- Load model: Sử dụng model Whisper Large V3 Turbo mới nhất, bạn có có thể sử dụng các phiên bản nhẹ hơn dưới đây để phù hợp với cấu hình.
import torch
from transformers import pipeline # có thể sử dụng GPU hoặc CPU
device = "cuda:0" if torch.cuda.is_available() else "cpu"
pipe = pipeline("automatic-speech-recognition", "openai/whisper-large-v3-turbo", torch_dtype=torch.float16, device=device)
- Demo bằng Gradio: Mình sử dụng Gradio để dễ demo, các bạn có thể tìm hiểu kỹ hơn về thư viện Gradio ở đây
import gradio as gr def transcribe(inputs): if inputs is None: raise gr.Error("No audio file") text = pipe(inputs, generate_kwargs={"task": "transcribe"}, return_timestamps=True)["text"] return text demo = gr.Interface( fn=transcribe, inputs=[ gr.Audio(sources=["microphone", "upload"], type="filepath"), ], outputs="text", title="Whisper Large V3 Turbo: Transcribe Audio", description=( "Transcribe long-form microphone or audio inputs. Thanks to HuggingFace" ), allow_flagging="never",
)
demo.launch()
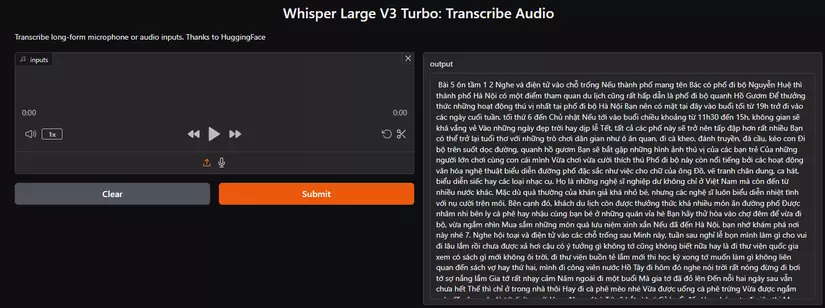
- Kết quả: Đây là kết quả sau khi mình tải lên một đoạn âm thanh tiếng Việt, bạn cũng có thể sử dụng đầu vào là âm thanh từ micro và từ đa số ngôn ngữ khác.
3.2 Deepgram nova-2
- Lấy Deepgram API key: Đầu tiên các bạn chỉ cần đăng nhập vào Deepgram thì sẽ được free khoảng 45000 phút dùng (thoải mái để sử dụng).
- Cài đặt thư viện:
!pip install deepgram-sdk==2.12.0
!pip install httpx
!pip install python-dotenv
- Load model: Sử dụng Deepgram Nova-2
Đầu tiên các bạn tải file muốn phiên âm lên google colab để lấy đường dẫn. vd /content/2019_hn_studentbookb1_5.mp3
from deepgram import Deepgram
import json, os dg_key = 'xxxxxxxx07e693ecb9547cbd865500xxxxxxx' # Deepgram API key
dg = Deepgram(dg_key) # Các định dạng hỗ trợ mp3, mp4, mp2, aac, wav, flac, pcm, m4a, ogg, opus, webm
MIMETYPE = 'mp3' # Thay vì một thư mục, đây là đường dẫn cụ thể đến file âm thanh
AUDIO_FILE_PATH = '/content/2019_hn_studentbookb1_5.mp3' # Đường dẫn đến file âm thanh # có thể sửa đổi các thông số của mô hình theo ý muốn!
params = { "punctuate": True, "model": 'nova-2', "language": 'vi', "smart_format": True, "paragraphs": True, "utterances": True, "utt_split": 0.8,
} # Gọi mô hình để phiên âm
def main(): if os.path.isfile(AUDIO_FILE_PATH): with open(AUDIO_FILE_PATH, "rb") as f: source = {"buffer": f, "mimetype": 'audio/' + MIMETYPE} res = dg.transcription.sync_prerecorded(source, params) # Lưu kết quả dưới dạng file .json with open(f"{AUDIO_FILE_PATH[:-4]}.json", "w") as transcript: json.dump(res, transcript) else: print(f"{AUDIO_FILE_PATH} is not a valid file.") return main()
- Phiên dịch: Đọc file đầu ra của bạn có đuôi json vừa tạo
# Đặt biến này thành đường dẫn đến tệp đầu ra mà bạn muốn đọc
OUTPUT = '2019_hn_studentbookb1_5.json' # JSON chứa đầy thông tin, nhưng nếu bạn chỉ muốn đọc bản ghi, chỉ cần chạy mã bên dưới!
def print_transcript(transcription_file): with open(transcription_file, "r") as file: data = json.load(file) result = data['results']['channels'][0]['alternatives'][0]['transcript'] result = result.split('.') for sentence in result: print(sentence + '.') print_transcript(OUTPUT)
- Kết quả:
Khả năng phiên dịch của Deepgram khá là vượt trôi cả về tốc độ và độ chính xác
Bài năm Uông Tâm một, hai, nghe và điền từ vào chỗ trống Nếu thành phố mang tên Bác có phố đi bộ Nguyễn Huệ, thì thành phố Hà Nội có một điểm tham quan du lịch cũng rất hấp dẫn là phố đi bộ quanh hồ Gươm. Để thưởng thức những hoạt động thú vị nhất tại phố đi bộ Hà Nội, bạn nên có mặt tại đây vào buổi tối từ mười chín giờ trở đi vào các ngày cuối tuần, tối thứ sáu đến chủ nhật Nếu tới vào buổi chiều khoảng từ mười một h30 đến mười lăm giờ, không gian sẽ khá vắng vẻ. Vào những ngày đẹp trời hay dịp lễ tết, tất cả các phố này sẽ trở nên tấp nập hơn rất nhiều. Bạn có thể trở lại tuổi thơ với những trò chơi dân gian như: ô ăn quan, đi cà kheo, đánh chuyền, đá cầu, kéo con, đi bộ trên suốt dọc đường, quanh hồ Gươm, bạn sẽ bắt gặp những hình ảnh thú vị của các bạn trẻ, của những người lớn chơi cùng con cái mình, vừa chơi vừa cười thích thú. Phố đi bộ này còn nổi tiếng bởi các hoạt động văn hóa, nghệ thuật biểu diễn đường phố đặc sắc, như việc cho chữ của ông đồ, vẽ tranh chân dung, ca hát, biểu diễn xiếc hay các loại nhạc cụ Họ là những nghệ sĩ nghiệp dư không chỉ ở Việt Nam mà còn đến từ nhiều nước khác. Mặc dù quà thường của khán giả khá nhỏ bé, nhưng các nghệ sĩ luôn biểu diễn nhiệt tình với nụ cười trên môi. Bên cạnh đó, khách du lịch còn được thưởng thức khá nhiều món ăn đường phố, được nhâm nhi bên ly cà phê hay nhậu cùng bạn bè ở những quán vỉa hè. Bạn hãy thử hòa vào chợ đêm để vừa đi bộ, vừa ngắm nhìn, mua sắm những món quà lưu niệm xinh xắn. Nếu đã đến Hà Nội, bạn nhớ khám phá nơi này nhé. Bảy. Nghe hội thoại và điền tử vào các chỗ trống sau. Minh này, tuần sau nghỉ lễ bọn mình làm gì cho vui đi. Lâu lắm rồi chưa được xả hơi, cậu có ý tưởng gì không? Tớ cũng không biết nữa, hay là đi thư viện quốc gia, xem có sách gì mới không? Ôi trời, đi thư viện buồn tẻ lắm. Mới thi học kỳ xong, tớ muốn làm gì không liên quan đến sách vợ, hay thứ hai mình đi công viên nước Hồ Tây đi. Hôm đó, nghe nói trời rất nóng, đừng đi bơi. Tớ sợ nắng lắm, da tớ rất nhạy cảm. Năm ngoái, đi một buổi mà ra tớ đã đỏ lên đến nỗi hai ngày sau vẫn chưa hết. Thế thì chỉ ở trong nhà thôi, hay đi cà phê mèo nhé, vừa được uống cà phê trứng vừa được ngắm mèo. Ơ, cậu quên là tớ dị ứng với lông động vật à? Tớ sẽ hắt xì hơi cả buổi đấy. Hay chúng ta đi siêu thị, mua nguyên liệu, rồi về nhà nấu ăn, hoặc mua vải, về tự may quần áo nhé. Ừ nhỉ! Tớ không nhớ là cậu bị dị ứng, nhưng nấu ăn thì ngày nào cũng nấu rồi. Thế này nhé, thứ hai đi đạp xe vào sáng sớm quanh Hồ Tây, không lo nắng đâu. Thứ ba, đi trung tâm thương mại gần trường mình xem phim. Còn thứ tư, tớ đang nghĩ rủ thêm An và Hoa, chúng mình tham quan làng văn hóa các dân tộc Việt Nam nhé, nghe nói đang có lễ hội. Chắc chắn cậu sẽ vui lắm. Đi đi. Nghe cũng khá thú vị đấy. Thứ năm hoặc thứ sáu, tớ sẽ theo ý kiến của cậu, chúng mình đi chợ hôm mua vải để tự may quần áo, tớ đang cần quần soóc và váy để đi biển với bố mẹ vào khoảng cuối tháng sau. Cậu đúng là tuổi ngựa.
Đến đây mình đã đánh giá và demo qua một 2 mô hình STT khá hot cho tới nay. Với open source, Whisper là một lựa chọn hợp lý cho những ai muốn nghiên cứu sâu hơn về lĩnh vực này. Với close source, Deepgram là một mô hình vượt trội. Cả 2 mô hình đều có thể phục vụ để giải quyết nhiều bài toán và làm cơ sở để xây dựng trợ lý ảo chat bot, tuy nhiên để có thể tạo được một chatbot ứng dụng hoàn chỉnh, ta còn cần xem xét thêm một số thứ nữa như memory cuộc hội thoại, tokenizer tiếng việt, tối ưu LLM,.... Hi vọng bài viết trên sẽ giúp các bạn hình dung tổng quan về Speech to text. Bài sau mình sẽ viết thêm về phần text to Speech (các mô hình hỗ trợ tiếng Việt). Cảm ơn bạn đọc 🥰!!!
4. TÀI LIỆU THAM KHẢO
https://openai.com/index/whisper/