1. MỞ ĐẦU
Chatbot đã được con người sử dụng và áp dụng rất nhiều trong các sản phẩm. Điển hình có thể kể đến là chatbot tư vấn bán hàng, chatbot hỏi đáp quy trình, .... Các chatbot này được xây dựng dựa trên kịch bản có sẵn, theo từ khóa, hoặc tiên tiến hơn nữa là áp dụng NLP như Rasa, ChatterBot, Dialogflow, ...Những sản phẩm này đều không có khả năng tương tác tự nhiên với con người, cũng như không cover được hết các trường hợp, dẫn đến gây ra các hiệu ứng ngược cho người dùng. Tuy nhiên, từ khi Chat GPT và mô hình ngôn ngữ lớn (Large Languae Model - LLM) ra đời, một cuộc thay máu cho toàn bộ hệ thống chatbot trước đây được khai sinh.
Đặc biệt, từ khi mô hình Llama được ra mắt vào tháng 2 năm 2023 bởi Meta AI, một loạt paper nghiên cứu về LLM finetuning, quantizing, optimizing,... đã liên tục ra đời. Kéo theo đó, việc có thể xây dựng một con chatbot với chi phí nhỏ cho riêng doanh nghiệp đã không còn xa vời. Dưới đây, mình sẽ xây dựng một con chatbot nho nhỏ có mục tiêu tra cứu thông tin trong tài liệu. Hi vọng, có thể giúp các bạn dễ dàng tiếp cận cũng như bắt đầu với LLM.
2. PHƯƠNG PHÁP SỬ DỤNG LÀ GÌ?
Trong phần này, mình sẽ không đi sâu vào các phương pháp hiện có, mà chỉ sơ lược lại một số hướng chính cũng như hot hiện nay. Chi tiết về các phương pháp - hướng nghiên cứu, các bạn có thể đọc của bạn Bùi Tiến Tùng lightweight-fine-tuning (đây cũng là một trong những người bạn giúp mình tìm hiểu về LLM 😁). Cụ thể, cho dễ hình dung, mình sẽ đưa ra 2 hướng nổi bật nhất hiện nay:
- Parameter Efficient Finetuning (PEFT): Loại này thường áp dụng khi bạn không có một tập dữ liệu đủ lớn và domain của bạn khác so với LLM ban đầu, ví dụ như chatbot sinh câu lệnh SQL, chatbot giải bài tập, ... (Nếu thời gian tới có thời gian, mình sẽ làm demo về loại này cũng như nói sâu hơn về ưu nhược điểm của nó).
- Embedding + RAG: Nhược điểm của các mô hình LLM là không thể trả lời những dữ liệu mới cũng như tính realtime, khi gặp các câu hỏi này, chatbot thường tạo ra những câu trả lời không chính xác. Vì vậy, người ta đã nghĩ ngay đến việc sử dụng RAG (Retrieval Augmented Generation) để trả lời cho các câu hỏi mang tính chuyên ngành và thông tin mới. Kết hợp với prompt design để hạn chế câu trả lời fake của nó.
Như vậy, với mục tiêu tra cứu tài liệu, chúng ta đã biết mình cần đi theo hướng nào phải không nào =))))
À, còn một thứ nữa sẽ cần tìm hiểu đó là framework Langchain. Có thể hiểu đơn giản, LangChain là một khung mã nguồn mở cho phép chúng ta làm việc với các LLM với các thành phần bên ngoài khác để phát triển các ứng dụng. Mục tiêu của LangChain là liên kết các LLM, chẳng hạn như GPT-3.5 và GPT-4 của OpenAI, với một loạt nguồn dữ liệu bên ngoài để tạo và thu được kết quả theo ý muốn.
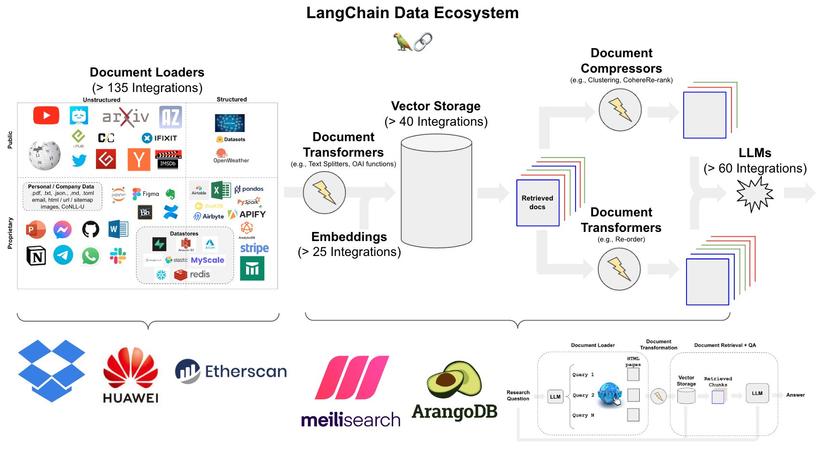
À, lại còn một điều nữa là mình sẽ demo trên Gg colab với card T4 nhé =))))) Bắt đầu thôi nào!
3. Xây dựng bài toán
3.1. Chuẩn bị và thiết lập môi trường
Các bạn cần cài đặt các thư viện sau: openai, langchain, ... Chú ý, việc cài đặt này nên đúng version nhé để tránh bị lỗi, vì hiện tại langchain vẫn đang được phát triển từng ngày.
!pip install -Uqqq pip --progress-bar off
!pip install -qqq openai==0.27.4 --progress-bar off
!pip install -Uqqq watermark==2.3.1 --progress-bar off
!pip install -qqq langchain==0.0.173 --progress-bar off
!pip install -qqq chromadb==0.3.23 --progress-bar off
!pip install -qqq pypdf==3.8.1 --progress-bar off
!pip install -qqq pygpt4all==1.1.0 --progress-bar off
!pip install -qqq pdf2image==1.16.3 --progress-bar off
!pip install -Uqqq tiktoken==0.3.3 --progress-bar off
!pip install -Uqqq unstructured[local-inference]==0.5.12 --progress-bar off
Sau đó, các bạn import thư viện vào:
import os
import textwrap import chromadb
import langchain
import openai
from langchain.chains import RetrievalQA
from langchain.chat_models import ChatOpenAI
from langchain.document_loaders import TextLoader, UnstructuredPDFLoader, YoutubeLoader, PyPDFLoader
from langchain.embeddings import HuggingFaceEmbeddings, OpenAIEmbeddings
from langchain.indexes import VectorstoreIndexCreator
from langchain.llms import OpenAI
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import Chroma
from langchain.llms import GPT4All
from pdf2image import convert_from_path
3.2. Load Data & Model
Ở phần này, mình sẽ down một file PDF làm ví dụ cho các bạn. File này tổng hợp một vài kiến thức về Data Warehouse mà trước mình tìm hiểu (tiện dùng luôn 😁). Ngoài ra, mình sẽ sử dụng OpenAI để lấy mô hình GPT3.5 làm mô hình cơ sở (các bạn có thể thay thế bằng mô hình khác như BLOOM, LLama 2,... để so sánh kết quả nhé)
# Download file pdf
!gdown https://drive.google.com/uc?id=16kk1KEqoorpVghSlMLI7O7PCfhr0Fucc
# Load mô hình
from getpass import getpass
OPENAI_API_KEY = getpass()
os.environ["OPENAI_API_KEY"] = OPENAI_API_KEY
model = OpenAI(temperature=0, model_name="gpt-3.5-turbo")
3.3. Load Data & Model
Sau khi đã có mô hình và file PDF, ta sẽ embedding file PDF này thành DB Vector. Thật may, Langchain hỗ trợ luôn việc chuyển FDF thành vector thông qua UnstructuredPDFLoader và PyPDFLoader. Việc của chúng ta chỉ cần đưa đường dẫn vào và run thôi =)))).
# Chuyển file PDF về dạng text
pdf_loader = UnstructuredPDFLoader("Li_thuyet_Hadoop.pdf")
pdf_pages = pdf_loader.load_and_split()
# Text Splitters
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1024, chunk_overlap=64)
texts = text_splitter.split_documents(pdf_pages)
len(texts)
Tiếp theo, mình sẽ thông qua một mô hình để có thể embedding toàn bộ text này:
# Sử dụng mô hình embedding
MODEL_NAME = "sentence-transformers/all-MiniLM-L6-v2"
hf_embeddings = HuggingFaceEmbeddings(model_name=MODEL_NAME)
# Chuyển toàn bộ text thông qua mô hình embedding về dạng vector và lưu dưới dạng db
db = Chroma.from_documents(texts, hf_embeddings, persist_directory="db")
3.4. Sử dụng Chain và Prompt
Prompt templates hiểu đơn giản là các chỉ dẫn, các yêu cầu, các ví dụ để cho chatbot hướng tới đúng mục đích mà chúng ta cần. Chain là khung hay phương tiện giúp chúng ta đưa các prompt cũng như type vào mô hình ngôn ngữ và sau đó nhận về kết quả.
Ở phần dưới này, mình sẽ tạo 1 prompt đơn giản và đưa vào và sử dụng chain để hỏi đáp.
# Prompt đơn giản được sử dụng
custom_prompt_template = """Sử dụng các thông tin sau đây để trả lời câu hỏi của người dùng.
Nếu bạn không biết câu trả lời, chỉ cần nói rằng bạn không biết, đừng cố bịa ra câu trả lời.
Tất cả câu trả lời của bạn đều phải trả lời bằng tiếng việt Context: {context}
Question: {question} """
# Hàm khởi tạo Prompt sẽ sử dụng
from langchain import PromptTemplate
def set_custom_prompt(): """ Prompt template for QA retrieval for each vectorstore """ prompt = PromptTemplate(template=custom_prompt_template, input_variables=['context', 'question']) return prompt
# Khai báo prompt và chain
prompt = set_custom_prompt()
chain = RetrievalQA.from_chain_type( llm=model, chain_type="stuff", retriever=db.as_retriever(search_kwargs={"k": 2}), chain_type_kwargs={'prompt': prompt}
)
3.5. Hỏi đáp thông tin tài liệu
Và đây là thành quả demo nho nhỏ của mình, mình sẽ hỏi bot một vài câu hỏi đơn giản nhá 😁:
query = "MapReduce là gì?"
response = chain.run(query)
print_response(response)
# MapReduce là một mô hình lập trình và kỹ thuật xử lý dữ liệu phân tán trong Big Data. Nó bao gồm hai
tác vụ quan trọng là map và reduce. Mô hình này được phát triển bởi Google và được sử dụng để tự
động song song hóa và phân phối các phép tính quy mô lớn trên các cụm máy tính lớn.
query = "Hadoop là gì?"
response = chain.run(query)
print_response(response)
# Hadoop là một hệ sinh thái phần mềm mã nguồn mở được sử dụng để xử lý và lưu trữ dữ liệu lớn. Nó bao
gồm các thành phần như HDFS, Hive, Pig, YARN, MapReduce, Spark, HBase, Oozie, Sqoop, Zookeeper, và
nhiều công cụ khác. Hadoop được xây dựng trên ngôn ngữ Java và tương thích trên nhiều nền tảng khác
nhau.
query = "Kiến trúc của Hadoop gồm những gì?"
response = chain.run(query)
print_response(response)
# Kiến trúc của Hadoop bao gồm các thành phần sau: 1. Hadoop Distributed File System (HDFS): Hệ thống
file phân tán của Hadoop, nằm ở trên cùng của hệ thống file cục bộ và giám sát quá trình. 2.
MapReduce: Mô hình xử lý dữ liệu phân tán trong Hadoop, sử dụng các công cụ để phân tách và xử lý dữ
liệu trên các nút trong cụm. 3. YARN (Yet Another Resource Negotiator): Quản lý các thành viên trong
nhóm máy chủ và phân phối tài nguyên cho các ứng dụng chạy trên Hadoop. 4. ZooKeeper: Hệ thống quản
lý và bầu cử leader trong Hadoop, đảm bảo tính nhất quán và sẵn sàng của dữ liệu. 5. Hadoop Common:
Bao gồm các thư viện và công cụ chung được sử dụng bởi các thành phần khác trong Hadoop. 6. Hadoop
Ozone: Hệ thống lưu trữ đối tượng phân tán trong Hadoop, cung cấp khả năng lưu trữ và truy xuất dữ
liệu theo kiểu đối tượng. 7. Hadoop HDFS Federation: Cung cấp khả năng mở rộng và phân chia dữ liệu
trên nhiều cụm HDFS. 8. Hadoop HDFS High Availability: Cung cấp khả năng sao lưu và khôi phục tự
động cho HDFS, đảm bảo tính sẵn sàng và tin cậy của dữ liệu. 9. Hadoop HDFS Erasure Coding: Sử dụng
mã hóa xóa để giảm bớt lưu trữ dự phòng và tăng hiệu suất lưu trữ trong HDFS. 10. Hadoop HDFS
Snapshots: Cung cấp khả năng tạo và quản lý các bản snapshot của dữ liệu trong HDFS, cho phép khôi
phục dữ liệu về trạng thái trước đó.
Có thể thấy, câu trả lời của chatbot sau khi mình sử dụng RAG là khá tốt, cũng khá chính xác =))))
Code toàn bộ mình sẽ để ở đây: Colab
Tuy nhiên, đây chỉ là demo nho nhỏ. Vì vậy, để có thể tạo được một chatbot ứng dụng hoàn chỉnh, ta còn cần xem xét thêm một số thứ nữa như memory cuộc hội thoại, tokenizer tiếng việt, tối ưu LLM, ... Hi vọng, với những thứ mình làm ở trên sẽ giúp cho các bạn hình dung cũng như bắt đầu với chatbot LLM.