
Mùa thu năm ngoái, Wall Street Journal đưa tin rằng 23% MBA Harvard đang tìm việc vẫn chưa có việc làm sau ba tháng tốt nghiệp. Sau đó, tháng trước, Anthropic công bố nghiên cứu về tác động của AI lên thị trường lao động, trong đó xếp các nhà phân tích tài chính vào nhóm 10 ngành nghề có nguy cơ bị AI thay thế cao nhất.
Sự lo lắng là dễ hiểu. Nhưng chúng tôi cho rằng điều đó vẫn còn quá sớm.
Chúng tôi đã stress-test các mô hình AI tiên tiến với các bài toán suy luận tài chính phản ánh công việc thực tế như phân tích báo cáo lợi nhuận, đánh giá thương vụ, và tài liệu trình bày cho nhà đầu tư. Kết quả cho thấy một khoảng cách đáng kể giữa hiệu suất trên benchmark tiêu chuẩn và hiệu suất khi xử lý các đầu vào phức tạp, đa phương thức mà nhà đầu tư thực sự sử dụng hằng ngày.
Khi cung cấp dữ liệu tài chính thực tế kết hợp biểu đồ, đồ thị và hình ảnh thay vì số liệu dạng văn bản, độ chính xác giảm đáng kể. GPT-5.4, Gemini 3.1 Pro và Claude Opus 4.6 đều gặp hai lỗi chính: đọc sai giá trị từ tài liệu hình ảnh dày đặc và áp dụng sai phép toán tài chính ngay cả khi dữ liệu đầu vào là đúng.
Thiết lập thử nghiệm
Chúng tôi xây dựng 25 bài toán dựa trên tài liệu tài chính thực tế: báo cáo lợi nhuận, slide trình bày cho nhà đầu tư, roadmap sản phẩm và bảng phí quy định. Mỗi bài yêu cầu xác định các con số cụ thể từ tài liệu và thực hiện một phép tính tài chính như biên lợi nhuận, tốc độ tăng trưởng, tỷ lệ pha loãng hoặc tỷ lệ. Mỗi bài chỉ có một đáp án số duy nhất, nên việc chấm điểm rất rõ ràng: đúng hoặc sai.
Chúng tôi bắt đầu với ảnh gốc của tài liệu (chỉ hình ảnh), sau đó tạo phiên bản chỉ văn bản bằng cách viết lại nội dung từ ảnh thành text. Điều này giúp tách hai dạng lỗi mà benchmark thường gộp chung: mô hình có biết tính toán không? và mô hình có đọc được tài liệu không?
Chúng tôi thử nghiệm ba mô hình: GPT-5.4, Gemini 3.1 Pro và Claude Opus 4.6 trên cả hai phiên bản, tổng cộng 50 lần đánh giá mỗi mô hình (25 bài × 2 dạng). Mỗi mô hình nhận cùng prompt và cùng dữ liệu. Nếu kết quả cuối cùng nằm trong khoảng sai số cho phép so với đáp án đúng, thì được tính là pass.
Kết quả
Mô hình cần đọc được tài liệu để suy luận đúng
Trước khi chạy toàn bộ thử nghiệm, chúng tôi kiểm tra nhanh: chỉ đưa câu hỏi mà không cung cấp tài liệu, yêu cầu mô hình trả lời dựa trên kiến thức đã học.
Kết quả rất rõ ràng. Trong 25 bài, Claude Opus 4.6 đúng 1/25 (4%), GPT-5.4 đúng 1/25 (4%), và Gemini 3.1 Pro đúng 0/25 (0%). Hai mô hình chỉ đúng một bài duy nhất (task_136) — đây là một đáp án số nguyên nhỏ mà họ đoán trúng ngẫu nhiên.
Điều này cho thấy benchmark thực sự đo khả năng suy luận từ tài liệu, không phải khả năng nhớ số liệu tài chính.
Mô hình xử lý text tốt hơn hình ảnh
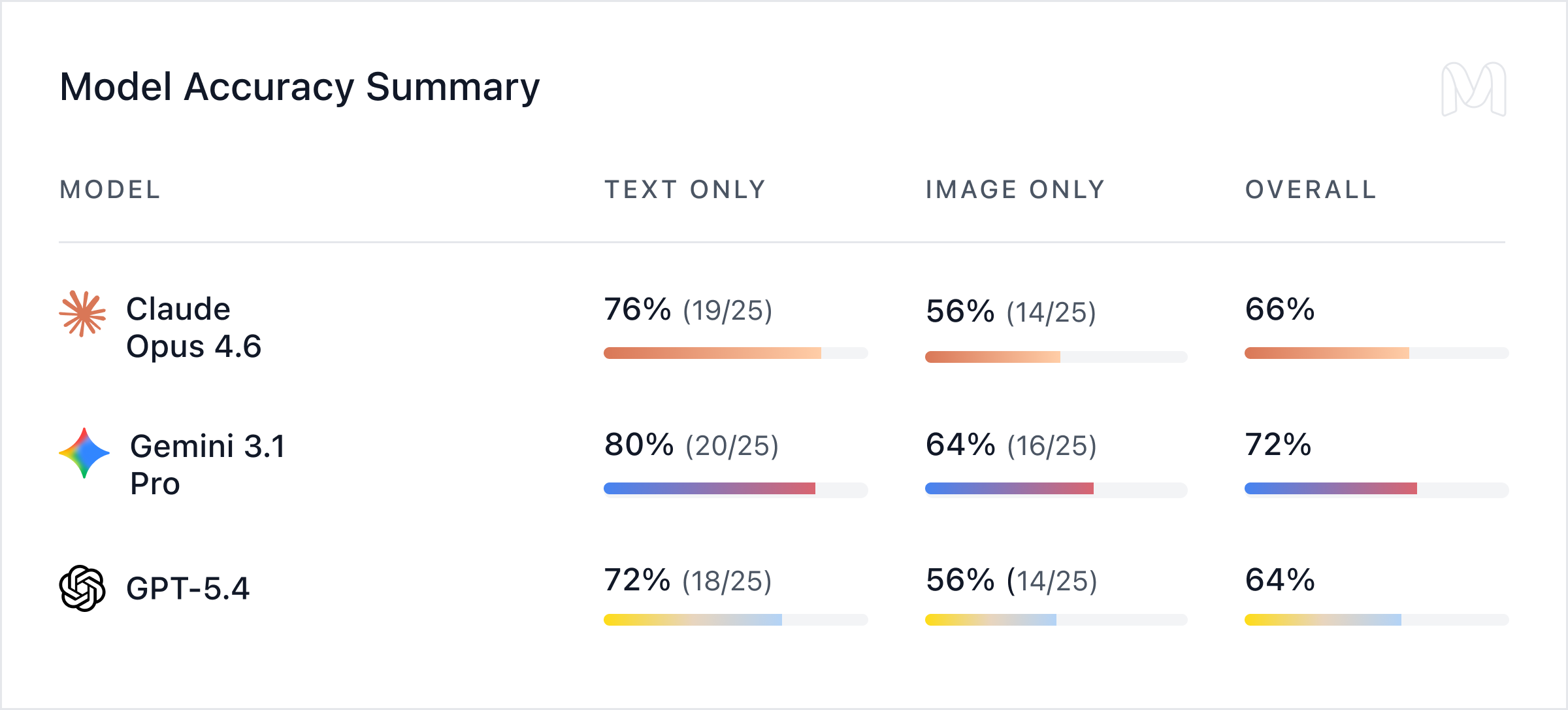
Khi được cung cấp văn bản sạch, hiệu suất khá tốt: độ chính xác từ 72% (GPT-5.4) đến 80% (Gemini 3.1 Pro), Claude Opus 4.6 đạt 76%. Nhưng khi chỉ dùng ảnh, độ chính xác giảm xuống còn 56%–64%, tương đương giảm 16–20 điểm phần trăm.
Sự suy giảm từ text sang image rất nhất quán: Claude Opus 4.6 giảm 20 điểm, Gemini 3.1 Pro và GPT-5.4 đều giảm 16 điểm. Điều này cho thấy điểm yếu chung của các mô hình hiện đại: trích xuất thông tin từ tài liệu tài chính dạng hình ảnh vẫn là nút thắt lớn.
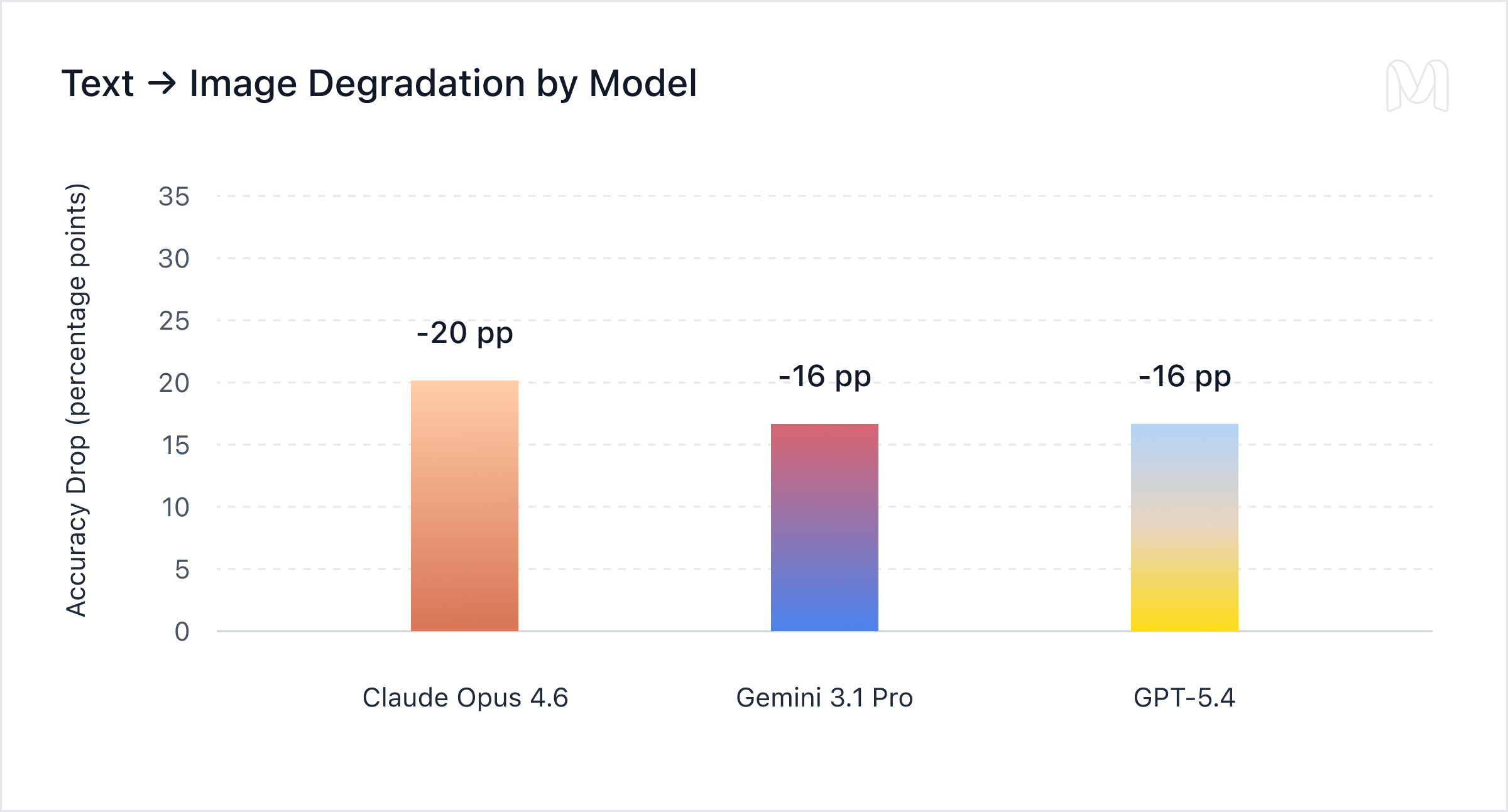
Cùng một bài toán, kết quả khác nhau
Ví dụ rõ nhất là task_138, liên quan đến mô hình Rising Wedge của Fidelity. Câu hỏi yêu cầu tính chênh lệch giá giữa hai đường xu hướng tại điểm vào lệnh.
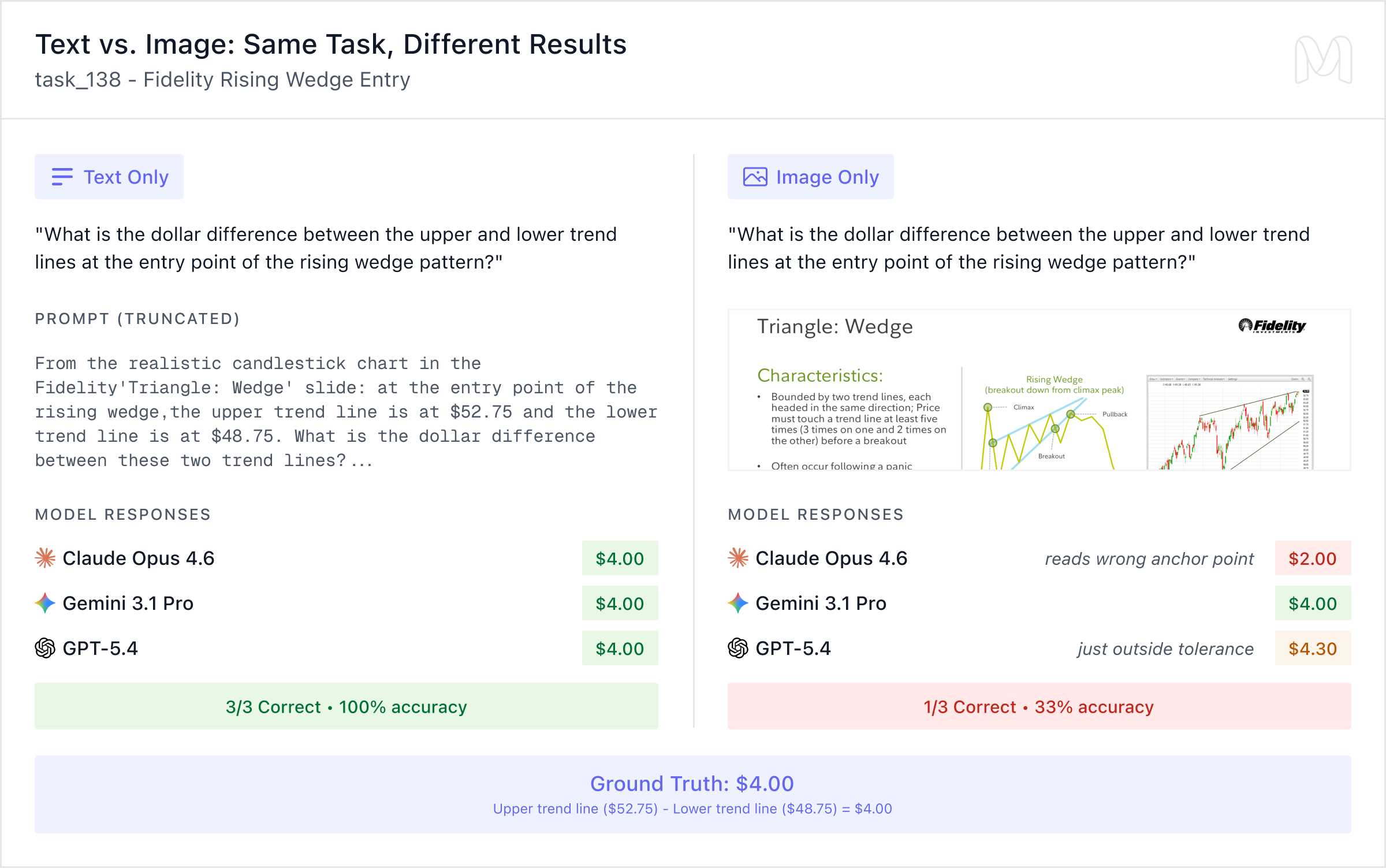
Ở dạng text, cả ba mô hình đều trả lời đúng ($4.00). Nhưng ở dạng image, chỉ Gemini 3.1 Pro đúng. Claude Opus 4.6 đọc sai điểm và trả $2.00. GPT-5.4 gần đúng nhưng lệch ($4.30). Mô hình biết cách tính nhưng không đọc đúng dữ liệu từ biểu đồ.
Hai dạng lỗi chính
Khi phân tích sâu, chúng tôi thấy hai dạng lỗi chính:
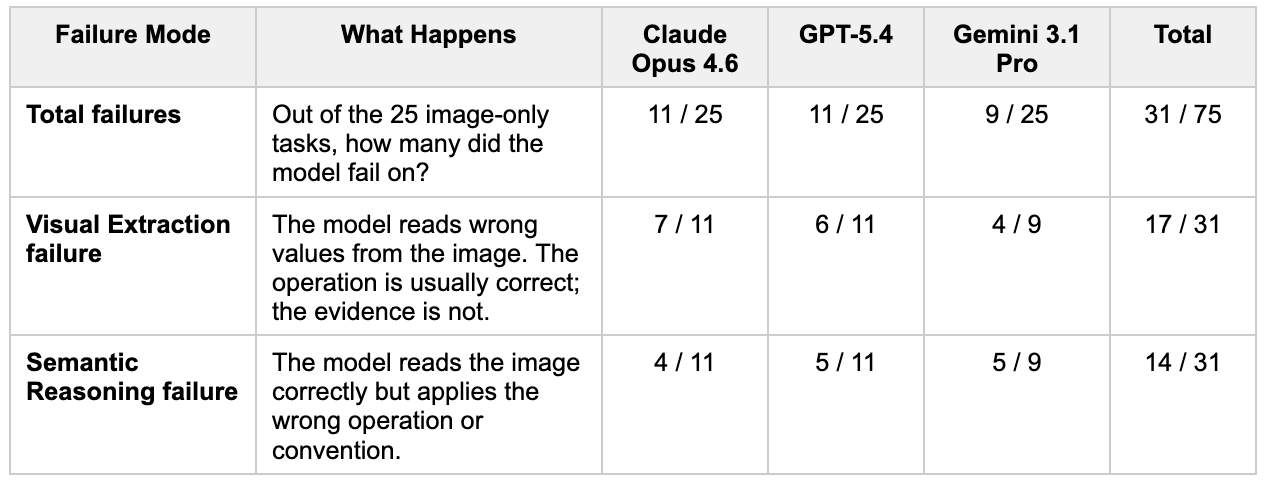
Trích xuất hình ảnh là nguyên nhân chính khiến mô hình thất bại. Chúng thường lấy nhầm dữ liệu trong các biểu đồ phức tạp, đặc biệt khi có nhiều biểu đồ trong cùng một trang. Đây là tình huống thực tế, nơi mô hình phải tự xác định vùng thông tin liên quan.
Lỗi suy luận ít thấy hơn nhưng đáng chú ý. Ngay cả khi có dữ liệu đúng (ở dạng text), mô hình vẫn có thể áp dụng sai phép toán — ví dụ tính chênh lệch tuyệt đối thay vì phần trăm, hoặc đảo ngược tỷ lệ. Đây đều là phép tính cơ bản, cho thấy vấn đề nằm ở cách mô hình thực hiện suy luận nhiều bước.
Trong một số trường hợp, cả hai lỗi xuất hiện cùng lúc: đọc sai dữ liệu và tiếp tục suy luận sai trên dữ liệu đó.
Vì sao điều này quan trọng
Các benchmark AI hiện tại không phản ánh công việc tài chính thực tế. Khác với các benchmark như ChartQA hay DocVQA (thường dùng dữ liệu sạch và đơn giản), các bài toán này sử dụng tài liệu thực tế phức tạp — nơi cần xác định đúng dữ liệu trước khi suy luận.
Trong thực tế, nhà đầu tư phải xử lý dữ liệu lộn xộn như PDF 40 trang với bảng biểu lồng nhau, nhiều biểu đồ, ghi chú và phân tích biên lợi nhuận.
Kết quả cho thấy các mô hình hiện tại xử lý bước trích xuất hình ảnh kém hơn nhiều so với những gì benchmark thể hiện. Xu hướng cải thiện là rõ ràng, nhưng trước khi nói về việc AI thay thế các nhà phân tích tài chính, cần đặt câu hỏi: AI thực sự giỏi ở điều gì, và trong điều kiện nào?