SQL và NoSQL là chủ đề không còn xa lạ trong thời buổi hiện nay khi mà đi đâu cũng nghe bàn tán xôn xao MongoDB, Cassandra, CouchDB hay BigTable, DynamoDB...
- Postgres, MySQL, MSSQL là SQL. Còn MongoDB, Cassandra là NoSQL...
- NoSQL nhanh hơn SQL đấy, sao không dùng? MySQL lỗi thời rồi, chuyển sang MongoDB đi.
- Khi nào thì nên dùng NoSQL nhỉ, nếu SQL lỗi thời rồi thì sao vẫn còn được dùng ở rất rất nhiều các project?
Và vô vàn các câu hỏi hay lập luận, khẳng định đanh thép từ giới chuyên gia về vấn đề gây tranh cãi này. Còn mình thì nghĩ rằng.. thực ra chẳng có gì để phải tranh cãi nếu chúng ta hiểu đúng về SQL và NoSQL.
Nếu bạn chưa hiểu rõ về SQL và NoSQL thì hãy tiếp tục. Còn nếu bạn đã nắm chắc như lòng bàn tay thì.. cũng hãy đọc tiếp để góp ý, bổ sung cho mình nhé. Let's begin.
Question
Bất kì project nào cũng cần sử dụng đến database và một câu hỏi luôn thường trực mỗi khi chúng ta bắt đầu là nên chọn SQL hay NoSQL hay chơi cả 2 cho máu?
Muốn trả lời được ta cần hiểu rất rõ 2 loại này là gì, hoạt động thế nào, ưu nhược điểm ra sao để có thể áp dụng một cách linh hoạt và phù hợp nhất.
1) SQL
1.1) SQL là gì?
Đầu tiên là SQL, một LƯU Ý RẤT TO mình để ở đây là:
SQL không phải là một thứ gì đó nói về database và càng không phải là database. SQL là Structure Query Language: dịch sang tiếng Việt nghĩa là ngôn ngữ... mà thôi đừng dịch làm gì.
Cụ thể hơn, SQL là ngôn ngữ cho phép chúng ta viết các câu lệnh để thao tác với dữ liệu trong database:
- SELECT id, name FROM product
- DELETE FROM product WHERE id = 10
Không chỉ SELECT, DELETE mà còn kha khá các câu lệnh khác nhưng tựu chung lại là trông nó sẽ giống như dưới: bao gồm nhiều keywords, syntax này nọ và các parameters.
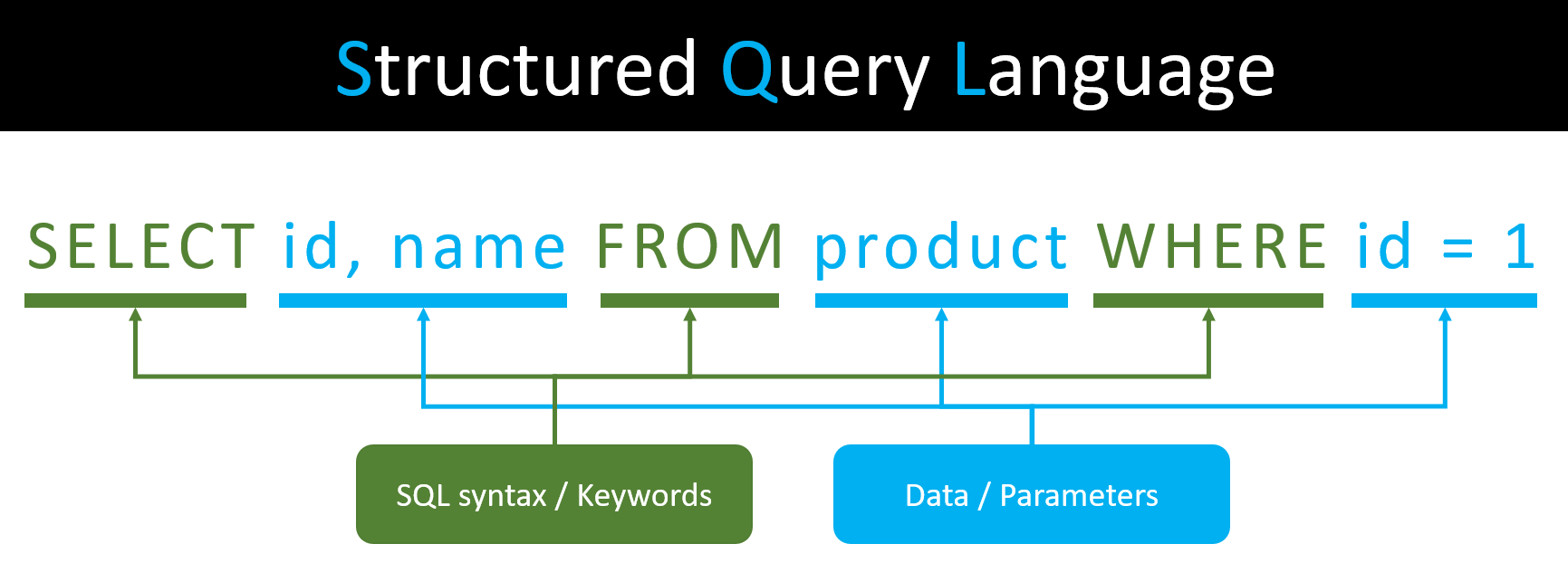
Túm cái váy lại SQL là một ngôn ngữ vô cùng powerful để tương tác (insert/update/delete/join...) với data trong database.
Khi nói đến SQL vs NoSQL chúng ta ngầm hiểu đó là nói về 2 loại DBMS khác nhau.
- Relational database: MySQL, MSSQL, Postgres... Đây là những database thường sử dụng để lưu trữ dữ liệu có cấu trúc rõ ràng, có tính quan hệ với nhau và quan trọng nhất là sử dụng SQL để truy vấn data.
- Non-relational database:: MongoDB, Cassandra, DynamoDB... Hiểu một cách đơn giản nó ngược lại so với SQL. Đây là những database có khả năng lưu trữ dữ liệu phi cấu trúc, không cần thể hiện quan hệ ràng buộc với nhau, không sử dụng SQL để truy vấn data.
1.2) Database structure
Chắc chắn từ thuở chân ướt chân ráo mới vào nghề, gần như 100% chúng ta bắt đầu với SQL và relational database.
Trong relational database, các data được tổ chức dưới dạng table bao gồm column (field) và row. Chúng ta cần biết rõ data schema để tiến hành tạo column cho phù hợp. Ví dụ với table Product chứa thông tin của các sản phẩm bao gồm một vài column cơ bản như id, product_name, price, description.
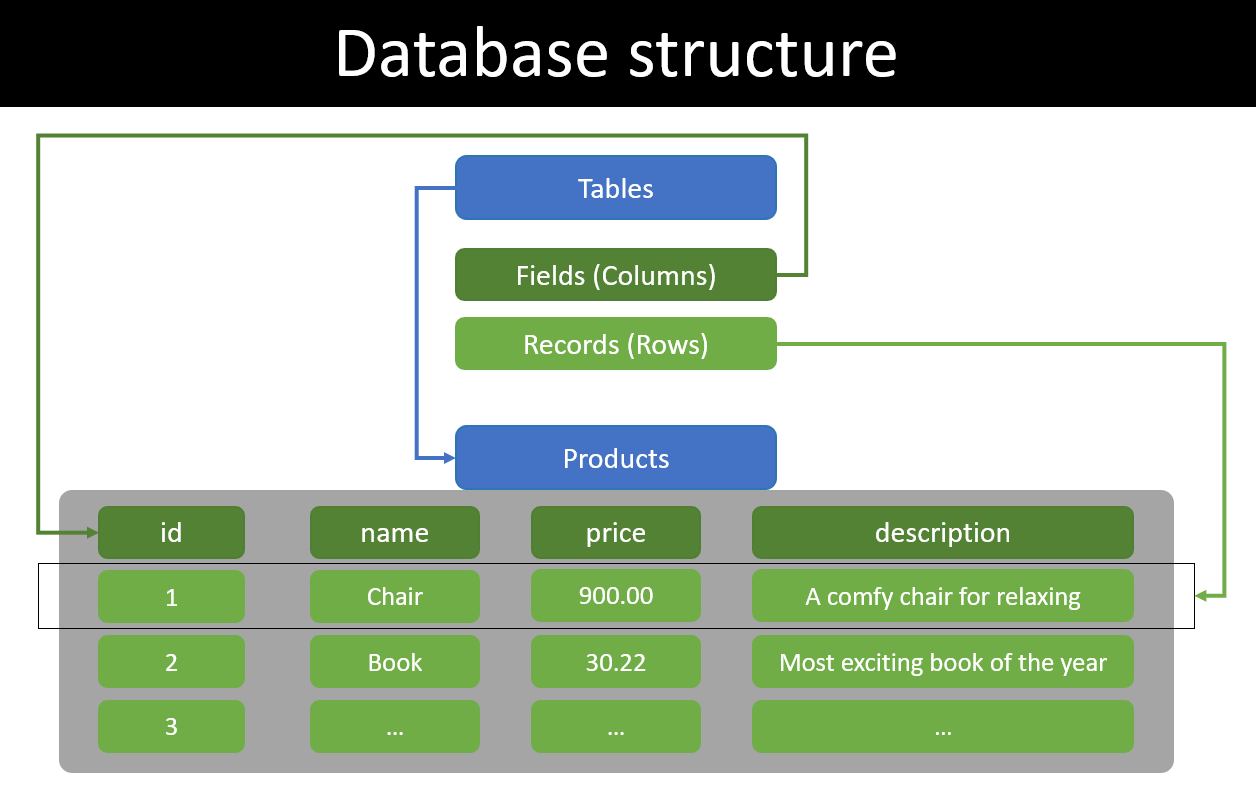
Khi có một sản phẩm mới thì thêm một record vào table Product với các thông tin id, name, price, description. Nếu sản phẩm mới không có thông tin description cũng chẳng phải vấn đề gì lớn lắm. Nhưng nếu sản phẩm mới có thêm một vài extra data như tags, manufatured date... thì đúng là khó rồi.
Thực ra cũng không khó lắm, chỉ cần tạo thêm column mới. Ok, vậy nếu tiếp tục có 1 sản phẩm khác lại thêm vài extra data khác thì sao, và cứ liên tục như vậy... thì đúng là.. khó vẫn hoàn khó. Ngoài ra, các sản phẩm không có extra data thì giá trị của các column đó sẽ là null, là empty. Đại khái trông sẽ như này:
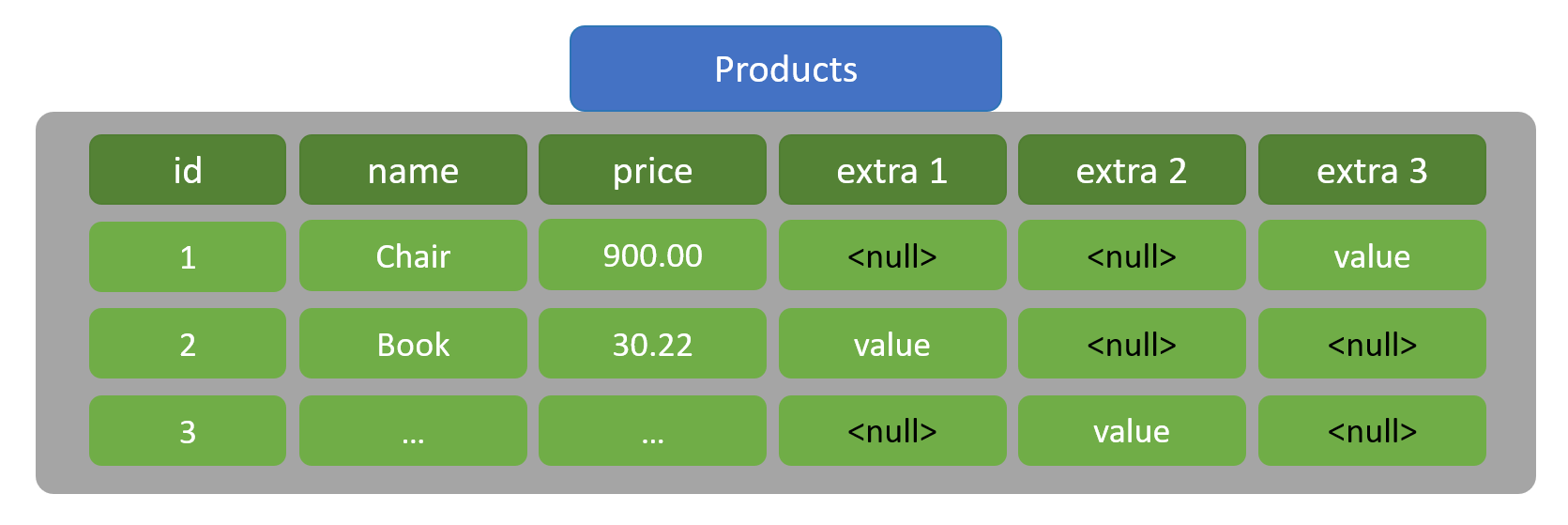
Như vậy với relational database, ta cần xác định rõ cấu trúc của data được lưu vào database hay nói cách khác là define clearly data schema và nó cũng là điều cực kì quan trọng. Vì toàn bộ các record (row) trong table đều phải tuân thủ theo các column đã được define và chỉ có thể thực hiện thao tác với data theo dạng đó (table/row/column).
Dù product có extra field hay không thì cũng đều cần đưa về một format để insert vào table. Nếu có giá trị thì lưu giá trị, nếu không có thì lưu null, chẳng thể bỏ đi được.
1.3) Relation
Một điều quan trọng khác trong thế giới relational database là không chỉ thao tác với một table mà có thể với nhiều table khác và những table này cũng có thể có relation (quan hệ).
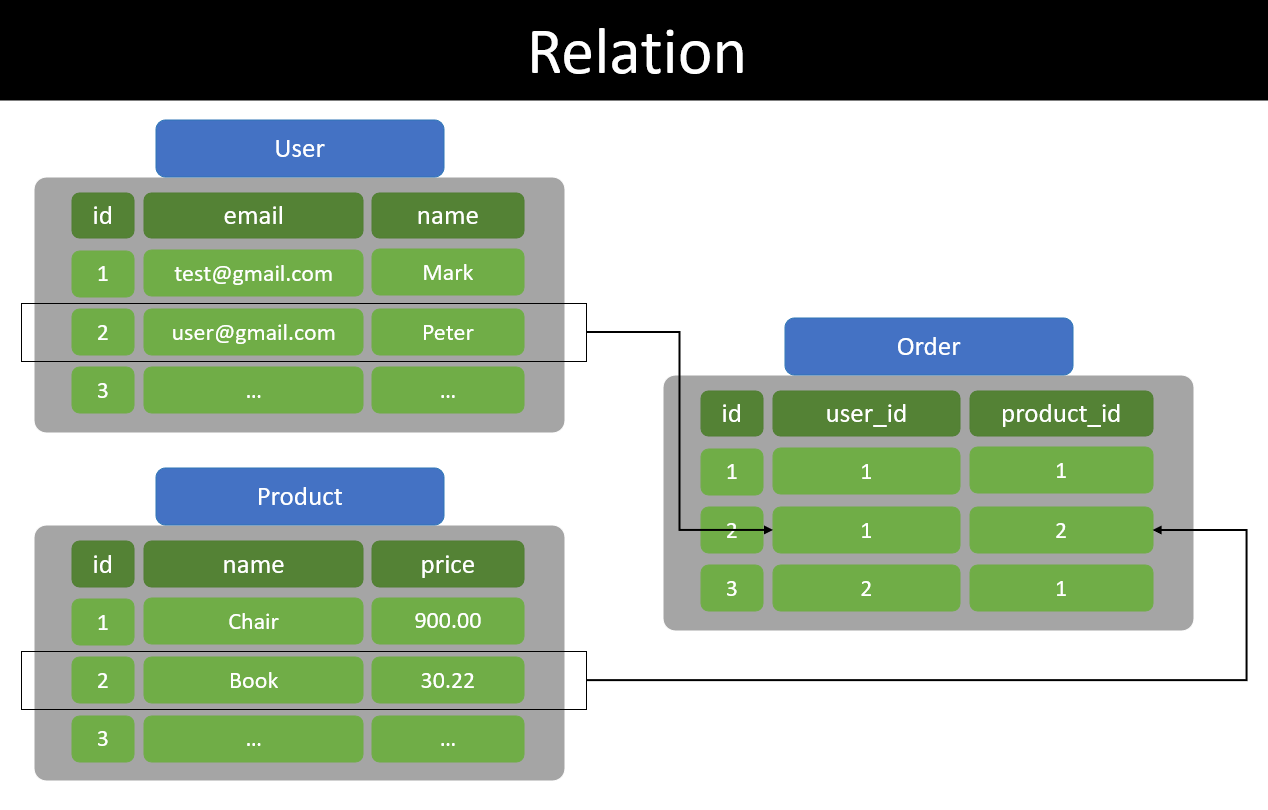
Ví dụ có 3 tables User, Order và Product đại diện cho 3 thứ quan hệ với nhau: khách hàng, đơn hàng và sản phẩm.
- User: lưu thông tin khách hàng.
- Product: lưu thông tin về sản phẩm.
- Order: lưu thông tin đơn hàng mà khách hàng đã đặt. Một user có thể có nhiều order, và một product có thể thuộc nhiều order khác nhau. Trực tiếp tạo nên sự liên quan giữa user, product và order.
Từ đó chúng ta có thể tạo một kết nối từ hai thứ tưởng chừng không liên quan nhưng lại rất lan quyên đến nhau là user và product. Trông thế này:
1.4) Types of relation
Phần này chắc chắn đã quá quen thuộc, không cần trình bày dài dòng. Tuy nhiên mình vẫn muống đưa vào vì nó chính là điểm mạnh của SQL và relational database. Có tất cả 3 loại relation là:
- One to One.
- One to Many.
- Many to Many.
1.4.1) One to One
Ví dụ có 2 table là UserInfo: lưu thông tin chung như tên, tuổi, giới tính... và UserContact: lưu thông tin liên lạc.
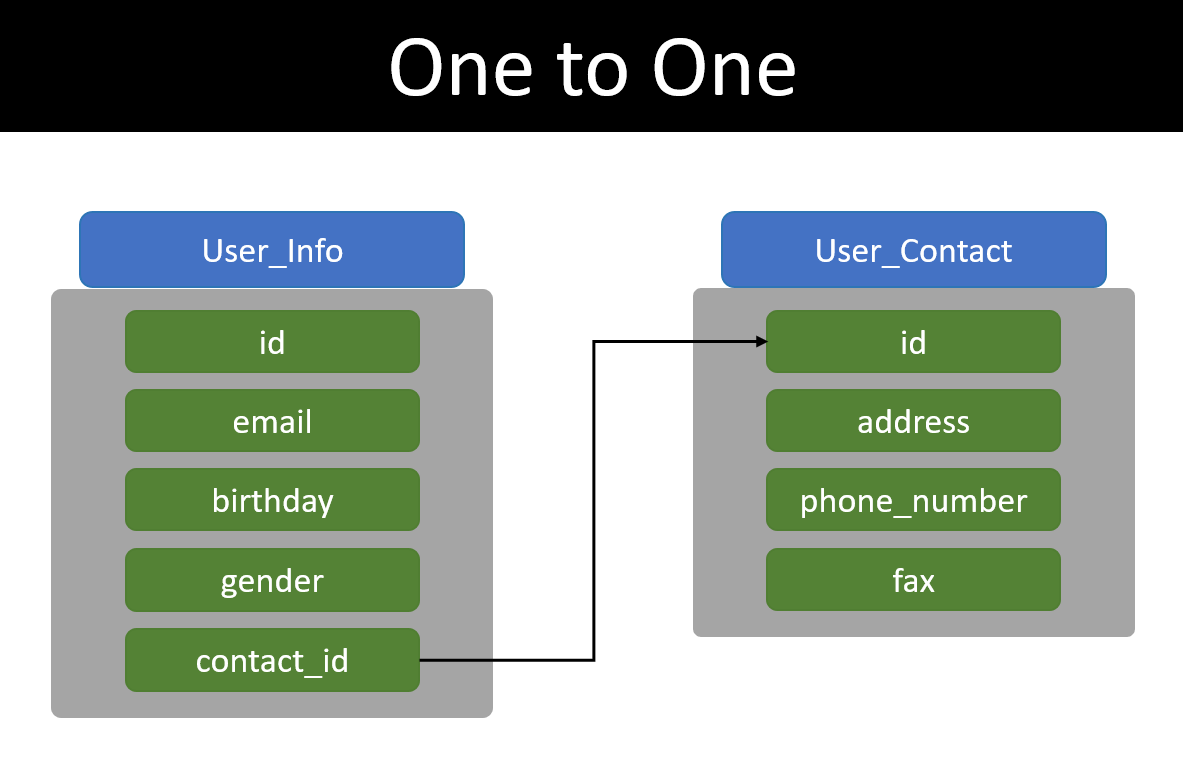
Một user chỉ có một record ở table UserInfo và related đến một record ở table UserContact thông qua contact_id.
Có thể một số bạn sẽ đặt câu hỏi sao không gộp chung thành một table cho đơn giản mà phải tách làm 2 table và quan hệ One to One làm gì cho phức tạp?
Có 2 lí do chính cho việc này:
- Khách quan: tăng tốc độ thao tác (insert/delete/update/select) với data, tất nhiên nó là rất nhỏ và chỉ phát huy tác dụng khi table có số lượng record cực lớn. Nhưng vì sao lại tăng tốc độ? Chúng ta cần hiểu cơ chế database lưu trữ data và cách thức data được lấy lên từ disk thế nào (có thể tìm hiểu kĩ hơn ở series này của mình nhé).
- Chủ quan: làm cho database trông clear hơn và phục vụ đúng mục đích hơn. Nếu gộp cả 2 table vào thì có tới 20 columns chẳng hạn, nhưng nếu tách ra 3 - 4 table phục vụ cho từng mục đích khác nhau thì số lượng columns chỉ còn 5 - 6. Ví dụ có những lúc chỉ cần thông tin liên lạc để gửi mail thì select từ table UserContact, hoặc hiển thị profile thì chỉ cần UserInfo.
1.4.2) One to Many
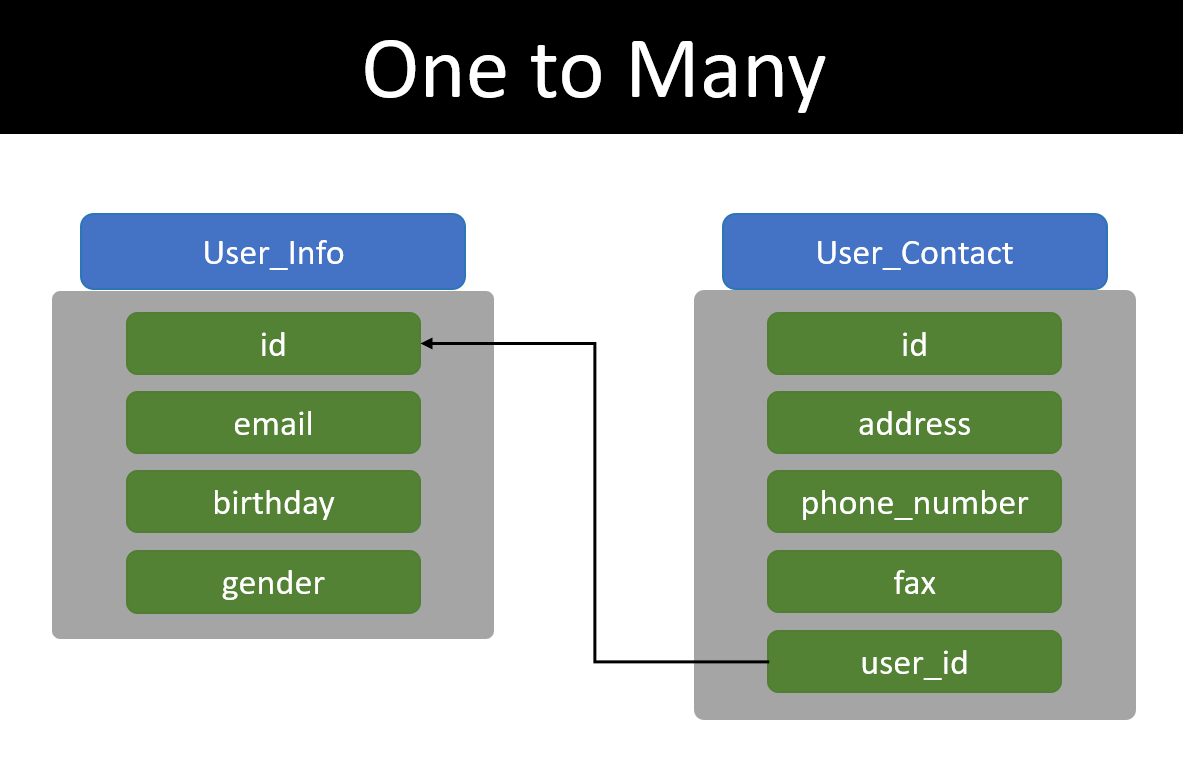
Một ngày đẹp trời user muốn thêm địa chỉ và số điện thoại mới nhưng không muốn bỏ địa chỉ cũ. Sử dụng 2 table như trên thì đúng là.. hơi khoai.
Nếu bạn là tín đồ của Shopee thì sẽ thấy khi order chúng ta có thể chọn địa chỉ giao hàng trong một danh sách các địa chỉ từ trước đó hoặc được tạo mới. Mà chẳng cần là tín đồ Shopee cũng biết khi design system là phải nghĩ đến điều này.
Có nghĩa là một user hoàn toàn có thể có một hoặc nhiều địa chỉ khác nhau. Đó là ví dụ của One to Many relation, trông nó dư lày:
1.4.3) Many to Many
Cuối cùng là Many to Many relation, rất phổ biến trong đời sống thực. Ví dụ một đơn hàng có thể có nhiều sản phẩm, và cùng mã sản phẩm đó cũng có thể nằm trong nhiều đơn hàng khác nhau.
Vậy thể hiện nó trên database với table như thế nào? Nếu chỉ có 2 table là Order và Product thì có 2 cách như sau:
- Mỗi table sẽ có thêm reference đến table kia thông qua id. Nếu có 3 orders và 3 products thì cần tổng cộng tới 9 records ở mỗi table (bao gồm cả duplicate data) để thể hiện quan hệ này...
- Mỗi table có thêm một column để lưu list các reference_id đến table kia...
Cả 2 cách trên đều stupid nên các engineer đi trước có cách khác là tạo một table trung gian lưu quan hệ của order và product. Trông nó như này:
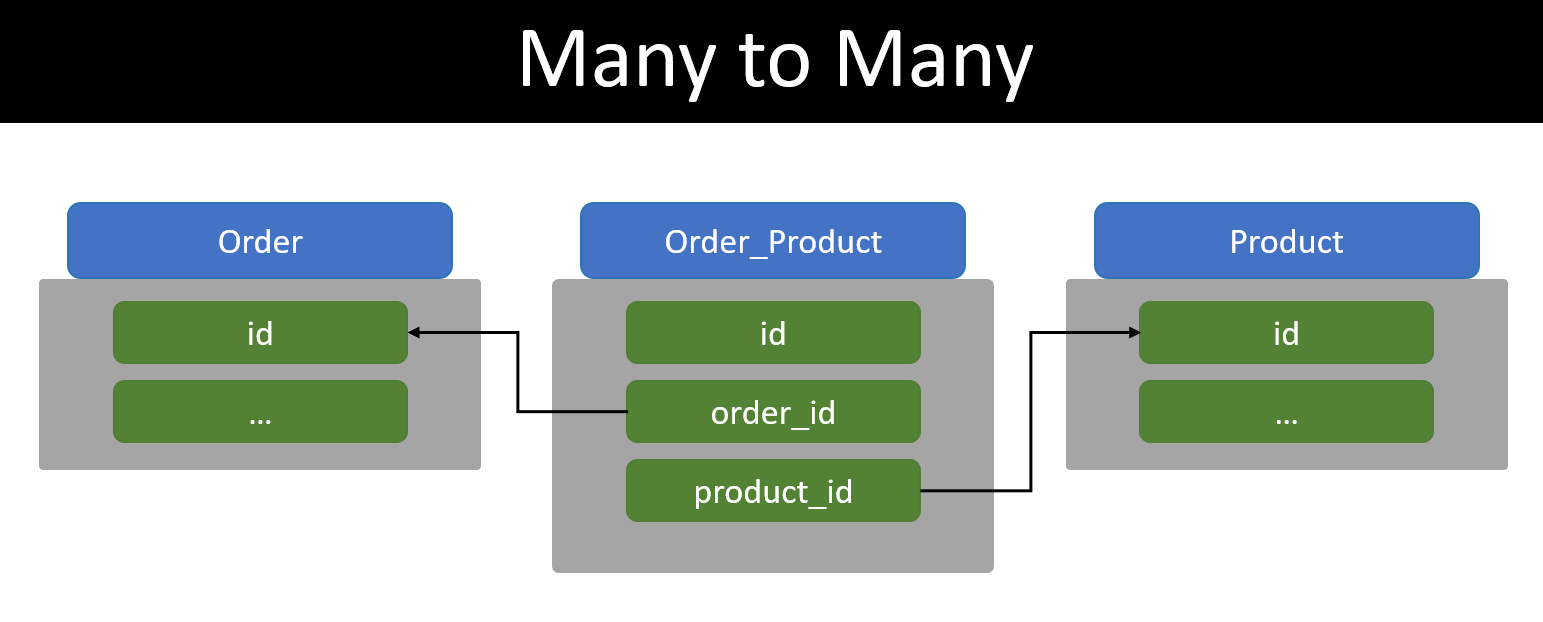
Thêm một bảng nhưng so với 2 cách trên thì.. perfect hơn nhiều. Không bị duplicate data, mỗi table vẫn chỉ có đúng 3 orders và 3 products, relation lúc này được chuyển sang table trung gian là OrderProduct.
1.5) Finalize
Chốt lại, SQL được sử dụng để tương tác với data của relation database và có 2 tính chất cực kì quan trọng:
- Strict schema: data được lưu trữ tại các table có tính chất cố định và cần được define từ trước.
- Relational data: data được lưu trữ phân tán trên nhiều table khác nhau và kết nối với nhau thông qua relation và SQL là thứ dùng để tương tác với relation đó (JOIN). Càng nhiều data phân tán trên nhiều table khác nhau thì SQL query càng dài, nhưng nó chính là điểm mạnh của SQL.
2) NoSQL
SQL thì học nhiều nghe nhiều lắm rồi, còn NoSQL thì sao? Thực ra nó cũng không phải quá là mới mẻ, nhưng nó vẫn là mới so với những người chưa nghe, chưa làm hoặc chưa thành thục về chúng.
2.1) NoSQL là gì?
Cái tên nói lên tất cả, No trong NoSQL có thể hiểu theo 2 cách sau:
- Không sử dụng SQL.
- No relation.
Như vậy NoSQL nói đến những loại non-relational database lưu trữ data KHÔNG theo dạng table - column - row, các data KHÔNG thể hiện quan hệ với nhau, và cũng KHÔNG sử dụng SQL để tương tác với data.
Vậy nếu muốn tương tác với data trong non-relational database thì làm cách nào? Mỗi database khác nhau sẽ có những cách thức khác nhau để làm điều này. Ví dụ với Elasticsearch là các REST APIs, Redis là các command line...
Trong thế giới NoSQL - non-relational database, tính đến thời điểm hiện tại có 4 mô hình lưu trữ data là:
- Document database: MongoDB, CouchDB...
- Key - value store: Redis, LevelDB, RocksDB...
- Wide column: Cassandra, Bigtable, HBase...
- Graph database: JanusGraph, Neo4j, TigerGraph...
Nếu đi sâu vào từng model thì dài quá, mình sẽ đề cập trong bài viết khác. Về cơ bản cả 4 loại đều có những phần chung về cơ chế lưu trữ và tổ chức data để phân biệt với relation database, do vậy mình sẽ chọn một loại phổ biến và tiêu biểu nhất là MongoDB để lấy ví dụ về NoSQL.
2.2) MongoDB tổ chức data thế nào?
Với SQL, ta có database Shop bao gồm các table User, Product, Order với mỗi table bao gồm các row (record) có nhiều column đại diện cho thông tin của một loại data.
Sang đến NoSQL sẽ không còn khái niệm table, column, record nữa mà thay vào đó cụ thể với MongoDB là collection, document, key, value. Trông nó sẽ như này:
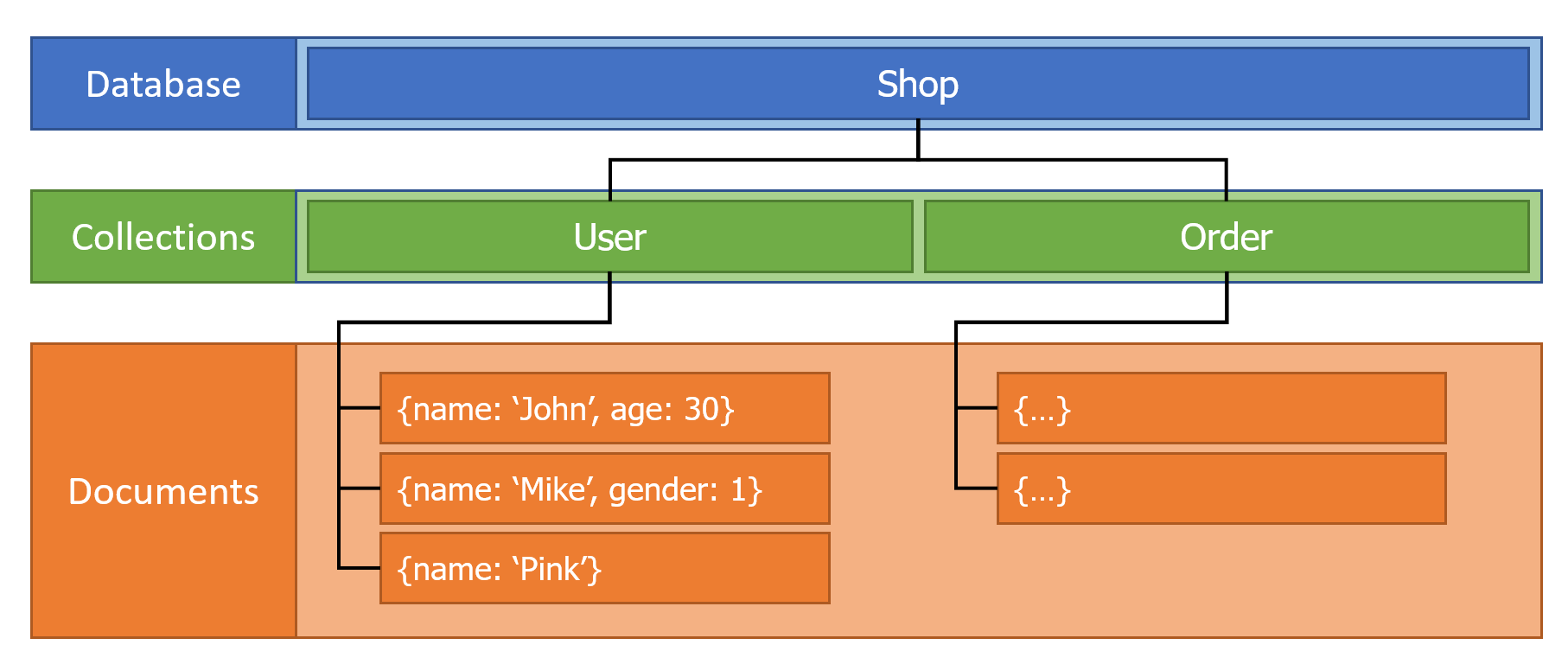
Dễ dàng nhận thấy collection tương đương với table, document tương đương với record (row), JSON key tương đương với column trong mối tương quan giữa SQL và NoSQL.
Ngoài ra một điều đặc biệt khác là document tổ chức data dưới dạng JSON và KHÔNG cần tuân theo một schema cố định. Điều đó nghĩa là có thể có nhiều documents khác schema, khác structure, khác field trong cùng một collection.
Như vậy có thể hiểu rằng trong cùng collection User hoàn toàn có thể có document của Order. Nhưng không ai làm như thế cả! Việc các document khác schema là trong trường hợp có các extra field như ví dụ trên với SQL thì việc tổ chức data sẽ gọn nhẹ hơn nhiều. Trông nó như này:
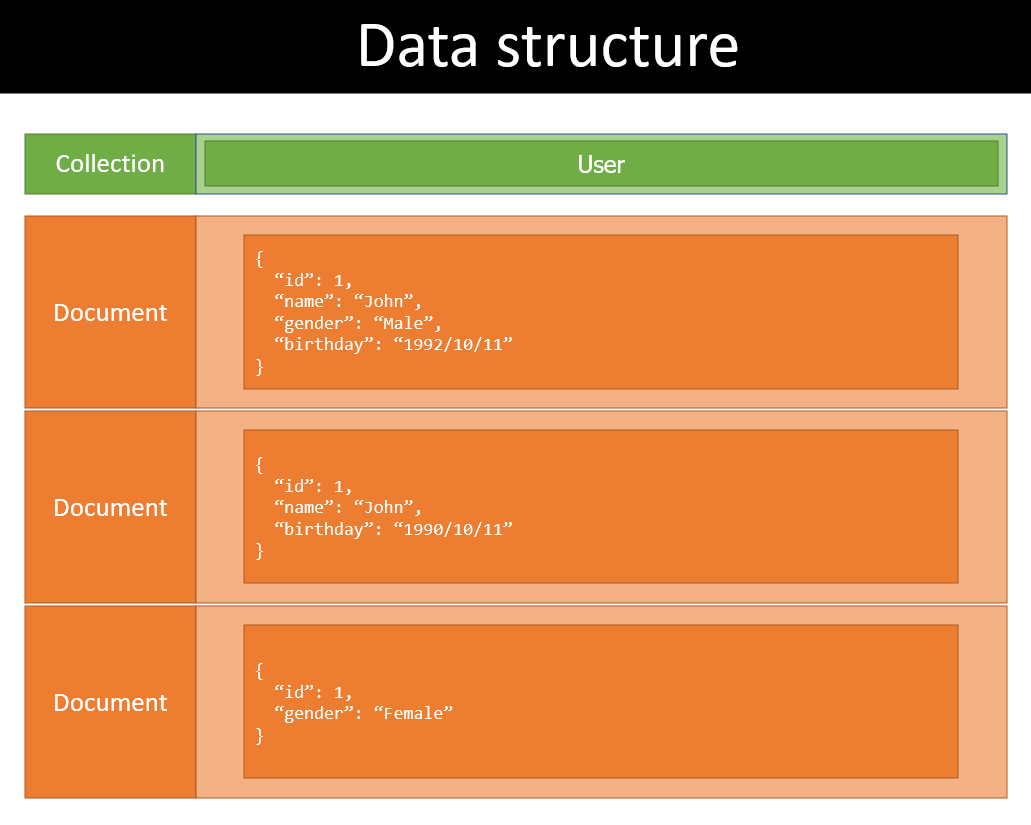
Mặc dù nó giúp tiết kiệm không gian và làm cho data structure linh động hơn, không cần phải sửa schema khi bỗng dưng có một document đặc biệt có vài extra field (vì làm gì có schema mà sửa), nhưng chính nó cũng là nhược điểm, vì không có schema nên khó khăn trong việc dự đoán format của data.
Nhưng nếu chọn NoSQL ngay từ đầu thì không cần quan tâm lắm đến vấn đề này vì nó đã có ưu điểm quá to là super flexible data structure.
Ví dụ khi build software sử dụng SQL chạy rất ổn định, mượt mà. Nhưng đến một lúc nào đó muốn hiển thị nhiều thông tin hơn, hay cụ thể là muốn lưu trữ và query nhiều data hơn cho một vài user trong User table, nếu sử dụng SQL thì chỉ có nước thêm column, sửa entity. Như vậy toàn bộ user trong User table đều được thêm column. Nhưng nếu sử dụng NoSQL thì... tuyệt vời rồi. User nào cần specific field nào thì cứ thêm thôi, những user khác không bị ảnh hưởng.
2.3) Relation
Chúng ta thường nghe và hiểu NoSQL hay no-relational database nghĩa là nói về việc các collections (Document database) không có mối quan hệ nào với nhau (phi quan hệ), ngược lại với SQL. Vậy nếu mối quan hệ User - Order - Product như ví dụ trên với SQL thì thể hiện trong NoSQL như thế nào vì trong thực tế cả 3 vẫn có mối liên quan đến nhau?
Trên lí thuyết, ta vẫn có thể set up relation giữa các document giống như SQL bằng cách thêm foreign key. Nhưng vấn đề là không thể sử dụng SQL để join và query data được nên việc tạo FK như vậy làm sai lệch đi bản chất của NoSQL là no-relation.
Idea để giải quyết vấn đề này của NoSQL là gom nhóm các data có liên quan với nhau vào cùng một chỗ và chấp nhận việc duplicate data.
Ví dụ, bạn muốn hiển thị order cùng với một vài thông tin cơ bản của user và product. Lúc này collection Order không chỉ chứa thông tin về order mà còn chứa thêm các thông tin cần thiết của user (id, name, email) và của product (id, price). Trông sẽ như này:
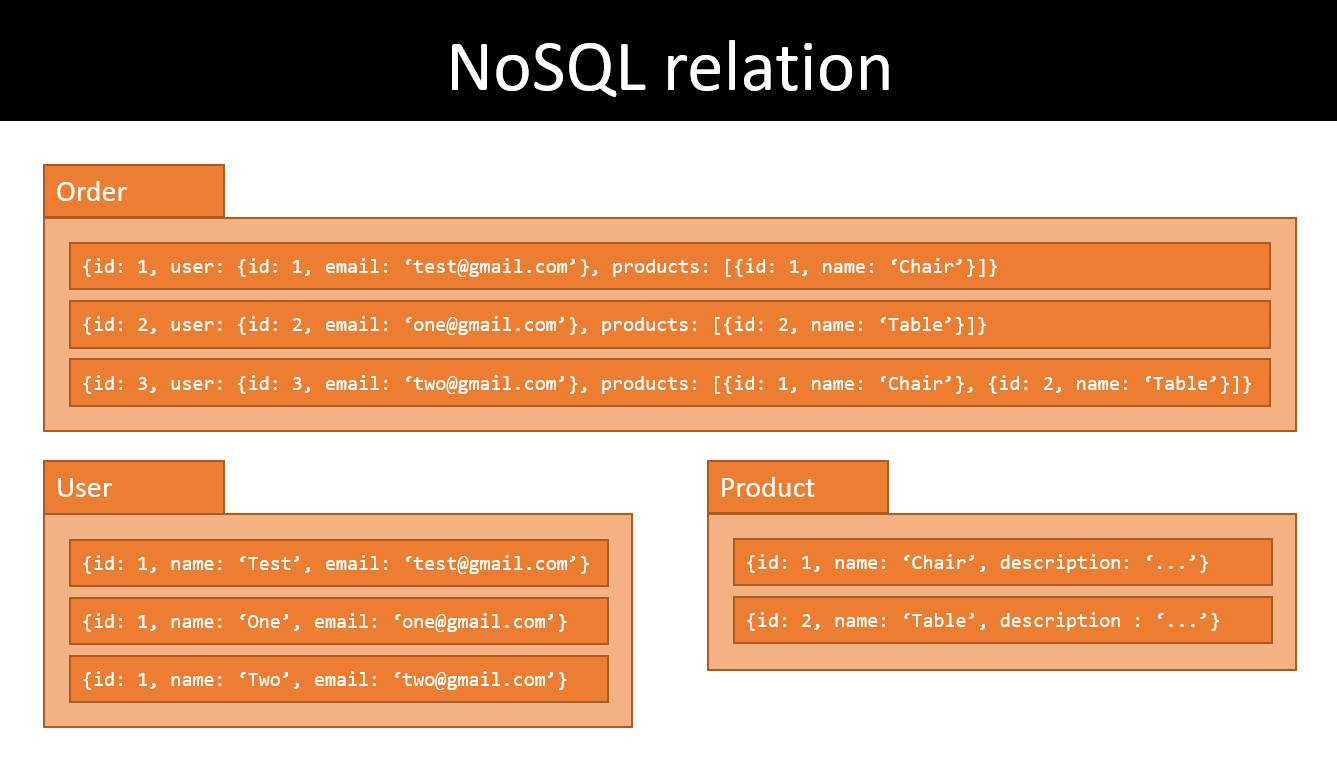
Như vậy vẫn collection User, Product với các thông tin chi tiết, nhưng chúng ta không cần query relation đó vì nó đã được duplicate những field cần thiết sang collection Order. Và đây chính là idea của NoSQL, càng ít các quan hệ thì tốc độ và hiệu quả query càng nhanh (không cần join).
No silver bullet, chẳng có gì là hoàn hảo, và cũng chính ưu điểm trên là nhược điểm của NoSQL, phải chấp nhận data bị duplicate ở nhiều nơi. Update product data ở Product8 cũng kéo theo việc update product ở Order.
Nhưng nếu việc update hiếm khi xảy ra, và là read heavy (read nhiều hơn write) thì nó vẫn là một điều tuyệt vời ông mặt zời.
Một lưu ý nữa không phải là hoàn toàn không có relation, sẽ có những trường hợp vẫn cần relation nhưng cần hạn chế nhất có thể (no relation or less relation as possible).
3) SQL vs NoSQL
Cuối cùng là so sánh giữa SQL và NoSQL để... hiểu điểm mạnh, điểm yếu của từng loại mà áp dụng cho phù hợp. Trên thực tế với những super big application / business đều áp dụng cả 2 loại SQL và NoSQL cho những data khác nhau với mục đích khác nhau.
Đừng so sánh để dìm hàng mà hãy so sánh để biết cách phát huy ưu điểm và hạn chế nhược điểm. Không chỉ trong lĩnh vực này mà còn thực tế ngoài đời sống nữa nhé các tài năng trẻ.

3.1) Data schema
Đầu tiên là về data schema, không cần bàn luận nhiều nữa vì 2 phần trên nói hết cả rồi.
Với SQL, cấu trúc của table, column sẽ được define trước và phụ thuộc vào schema. Ưu điểm là chúng ta biết trước được data format, đồng thời nhược điểm là data không flexible.
Khó để flexible thôi chứ không phải không thể. Bằng cách áp dụng EAV model chúng ta có thể dễ dàng biến Relational database strict schema sang dynamic & flexible data struct và cái giá phải trả đó là tốc độ query và sự tường minh trong design.
Lại thuật ngữ mới, EAV model là gì? Chờ bài sau nhé hoặc bạn có thể tìm đọc thêm về nó.
Ngược lại, nhược điểm và ưu điểm với data schema của SQL chính là ưu điểm và nhược điểm của NoSQL. NoSQL là schema-less, không tuân thủ theo một chuẩn data nào nên nó rất linh động trong việc mở rộng các record.
3.2) Relation and data structure
Tiếp theo, relation là một ưu điểm rất mạnh của relational database vì nó sinh ra với mục đích đó. Data trước khi lưu trữ sẽ được chuẩn hoá (normalize) và chia vào nhiều table khác nhau. Các data relation đến nhau thông qua FK. Việc update data chỉ cần diễn ra ở một table và các table còn lại không cần thay đổi gì cả.
Với NoSQL và non-relational database, relation là thứ vô cùng xa xỉ, gần như không có hoặc nếu có thì là rất rất ít. Do đó, sử dụng NoSQL phải chấp nhận duplicate data và khi update data có thể phải thực hiện ở nhiều collections nhưng đổi lại là tốc độ read data nhanh hơn so với relational database vì không có join.
3.3) Scaling
Để nói về scaling và replicate data chắc phải dành riêng một bài khác mới đủ, mình sẽ trình bày ngắn gọn nhất để chúng ta nắm được mấu chốt phần này.
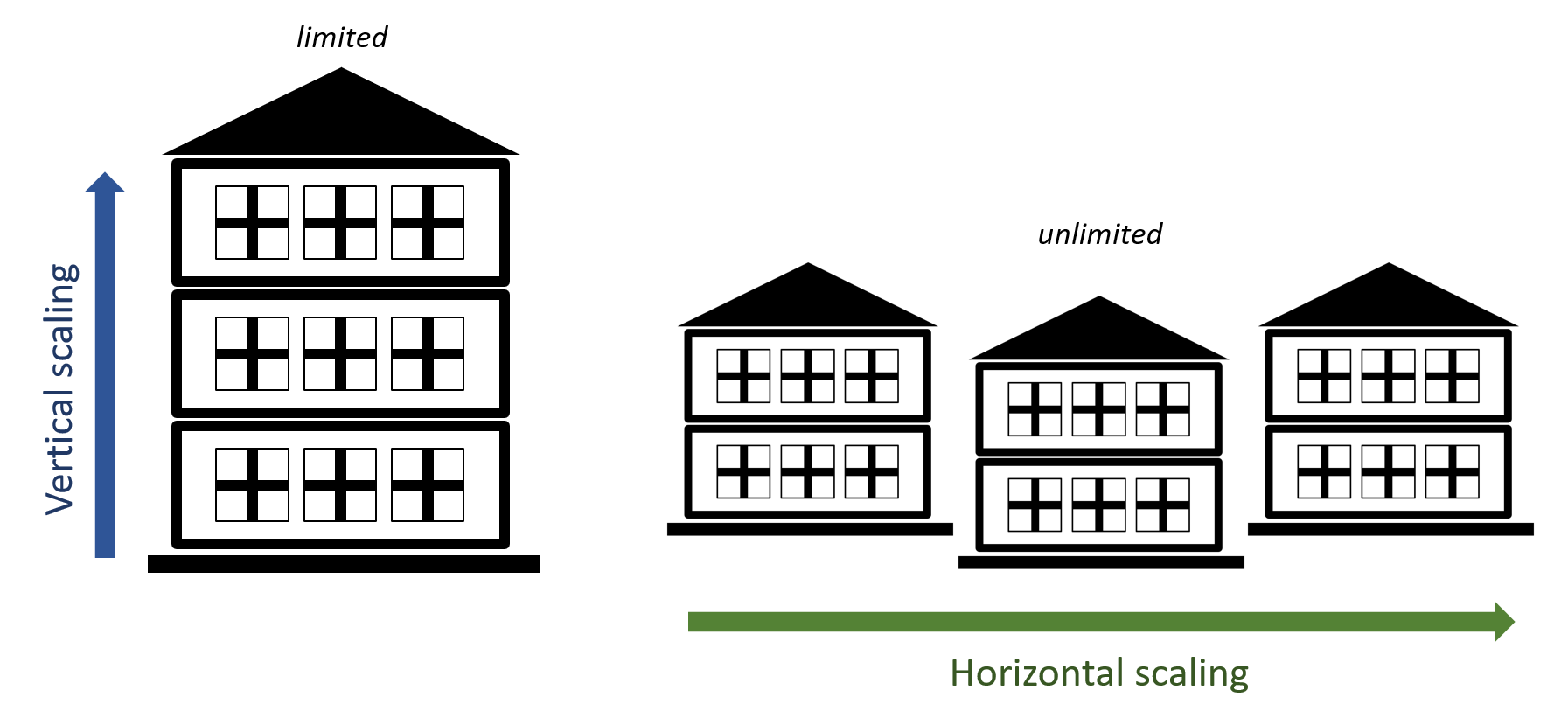
Có 2 loại scaling là vertical scaling (scale theo chiều dọc) và horizontal scaling (scale theo chiều ngang).
Ví dụ thế này, gia đình A có 3 nhân khẩu, ở căn biệt thự 300m2 cũng gọi là rộng rãi vch rồi. Thế rồi thời gian thấm thoát thôi qua, gia đình A tăng số lượng người từ 3 lên 5, lên 10, lên 20, lên 50 rồi đến cả trăm người. Thế là một căn biệt thự không đủ. Bây giờ có 2 phương án thế này:
-
Một là xây thêm tầng: nhưng xây bao nhiêu cho đủ. Mà xây thêm thì cũng chỉ có giới hạn, cùng lắm như toà Lanmark 81 là khủng lắm rồi.
Đây là ví dụ của vertical scaling. Với software, điều này tương tự với việc vẫn là con server đó nhưng ta tăng cấu hình lên bằng cách tăng RAM, tăng SSD, tăng CPU.
-
Hai là mua thêm nhà: về cơ bản thì đất đai có giới hạn thật, nhưng chỉ sợ thiếu tiền thôi chứ không sợ thiếu đất. Nếu không lo về tài chính thì cách này có vẻ ổn hơn cách đầu, gần như không giới hạn.
Và đây là ví dụ của horizontal scaling: phân tán dữ liệu trên nhiều server khác nhau thay vì chỉ dùng một server.
Vậy thì nó có liên quan gì đến SQL và NoSQL?
Ta cần hiểu rõ hơn về tính chất đặc thù của từng loại. Kim chỉ nam của relational database là relation, nhờ đó mà mới có thể sử dụng SQL để query data. Như vậy, nếu data được phân tán trên nhiều server khác nhau thì việc join data gần như là bất khả thi hoặc cần áp dụng những kĩ thuật phức tạp mới có thể làm được. Vậy nên SQL và relational database chỉ phù hợp với vertical scaling.
Với NoSQL và non-relational database thì việc horizontal scaling trở nên dễ dàng hơn vì nó đã loại bỏ relation. Mỗi record trong NoSQL đã có đủ thông tin cho chính nó và không cần join nên việc phân tán data (documents) ra nhiều server không gặp bất lợi gì. Ngoài ra hoàn toàn có thể phân tán cả các records thuộc cùng một document ra nhiều nơi khác nhau (partition/sharding). Vì vậy NoSQL scale đơn giản hơn rất nhiều cả vertical scale và horizontal scale.
Vẫn là câu nói quen thuộc chẳng có gì hoàn hảo 100%. Nếu NoSQL distributed data ra nhiều server khác nhau thì lúc query data biết data nằm ở server nào để query? Ngoài ra, trong trường hợp tăng số lượng server thì data có được re-balance giữa các server không? Hoặc toàn bộ query chỉ tập trung vào một vài server thì xử lí thế nào? Vô vàn những câu hỏi hóc búa hiện lên, nhưng bài dài lắm rồi, để dành cho bài viết sau nhé. Tạm thời ta chỉ cần hiểu rằng việc horizontal scale với NoSQL đơn giản hơn SQL nhiều.
3.4) Query speed
Phần mà ai cũng quan tâm đó là tốc độ query data.
Rất khó để nói rằng SQL hay NoSQL query nhanh hơn. Phải phụ thuộc vào từng hoàn cảnh và lượng data cũng như data structure ta mới có thể trả lời rõ ràng được.
Nếu fetch data phức tạp với nhiều relation và có hàng nghìn queries 1 lúc thì SQL có tốc độ không tốt bằng NoSQL.
Nhưng nếu data được update thường xuyên và write > read thì việc sử dụng NoSQL chưa chắc đã cho tốc độ tốt hơn so với SQL.
Cuối cùng, theo mình nghĩ việc quyết định lựa chọn SQL hay NoSQL hay cả 2 sẽ phụ thuộc vào 3 yếu tố sau:
- Business của dự án.
- Dung lượng dữ liệu.
- Kĩ năng của team.
Còn rất rất nhiều yếu tố khác và đã có vô vàn các bài viết về nó rồi nên mình không đề cập ở đây. Chốt lại, SQL cũng được mà NoSQL cũng được, điều quan trọng là bạn cần nắm rõ, hiểu kĩ và có thể xử lí mọi vấn đề liên quan đến nó là ok.
After credit
Tên MongoDB bắt nguồn từ humongous nghĩa là to lớn, khổng lồ với ý nghĩa nó có thể chứa được một lượng rất rất lớn data.
Cho những ai chưa biết ngoài SQL, NoSQL còn có một loại khác là NewSQL. Và nó cũng đã xuất hiện cách đây 7-8 năm về trước rồi. Cụ thể nó có khác gì so với SQL và NoSQL thì hẹn gặp trong bài viết khác nhé.
Happy new year!
© Dat Bui