Khi số lượng người dùng ứng dụng của bạn ngày càng tăng lên, dữ liệu từ đó sẽ tăng trưởng ngày càng nhiều hơn mỗi ngày, database của dự án sẽ dần trở nên quá tải. Và đây chính là lúc chúng ta cần thực hiện scale database.
Hai chiến lược chính để scale database thường được sử dụng đó là: Mở rộng theo chiều dọc (Vertical Scaling) và Mở rộng theo chiều ngang (Horizontal Scaling)
Cùng mình tìm hiểu về chúng trong bài viết này nhé!
1. Mở rộng theo chiều dọc (Vertical Scaling)
Định nghĩa:
Vertical Scaling là cách tăng cường "sức mạnh" của một server duy nhất bằng cách nâng cấp phần cứng của server đó, chẳng hạn như tăng thêm CPU, RAM hoặc ổ cứng, ...
Trên thế giới hiện nay có một số database server vô cùng mạnh mẽ. Theo Amazon Relational Database Service (RDS), bạn hoàn toàn có thể sở hữu một database server lên tới 24 TB RAM.
Khi đó nó có thể lưu trữ và xử lý rất rất nhiều dữ liệu.
Ví dụ, StackOverflow vào năm 2013 đã có tới hơn 10 triệu visitor mỗi tháng, nhưng nó chỉ có duy nhất 1 master database.
Ưu điểm:
- Vertical Scaling sẽ giúp cho việc quản lý CÓ THỂ sẽ dễ dàng hơn, vì chỉ có một máy chủ cần được quan tâm (nói là CÓ THỂ bởi vì nó còn phụ thuộc vào nhiều yếu tố, ví dụ như cấu trúc các bảng trong database được xây dựng có tối ưu hay không, ...)
Nhược điểm:
Tuy nhiên, Vertical Scaling cũng đi kèm với một số nhược điểm nghiêm trọng, có thể kể đến như:
-
Giới hạn về mặt phần cứng: Bạn có thể thêm nhiều CPU, RAM, ổ cứng, ... vào database server, nhưng rồi sẽ đến một lúc nó gặp giới hạn, mà bạn không thể tăng thêm được nữa.
-
Chi phí: Nâng cấp phần cứng sẽ rất tốn kém. Các server càng mạnh lại càng đắt đỏ.
-
Nguy cơ gặp phải single point of failures lớn hơn: Bạn có duy nhất 1 database, và database này vì lý do nào đó gặp phải sự cố, vậy là toàn bộ ứng dụng của bị sẽ không thể tương tác với database được nữa. Trong khi dữ liệu lại là phần quan trọng nhất của một ứng dụng.
Vậy khi nào nên sử dụng Vertical Scaling???
Bạn nên sử dụng Vertical Scaling khi hệ thống hiện tại chỉ cần tăng thêm một chút khả năng xử lý, và không dự kiến tăng trưởng đột ngột về dữ liệu hoặc truy vấn.
2. Mở rộng theo chiều ngang (Horizontal Scaling)
Định nghĩa:
Horizontal Scaling hiểu đơn giản là tăng cường "sức mạnh" của hệ thống bằng cách bổ sung nhiều database server hơn.
Hình vẽ dưới đây sẽ giúp bạn dễ dàng hình dung ra sự khác nhau giữa Vertical Scaling và Horizontal Scaling.
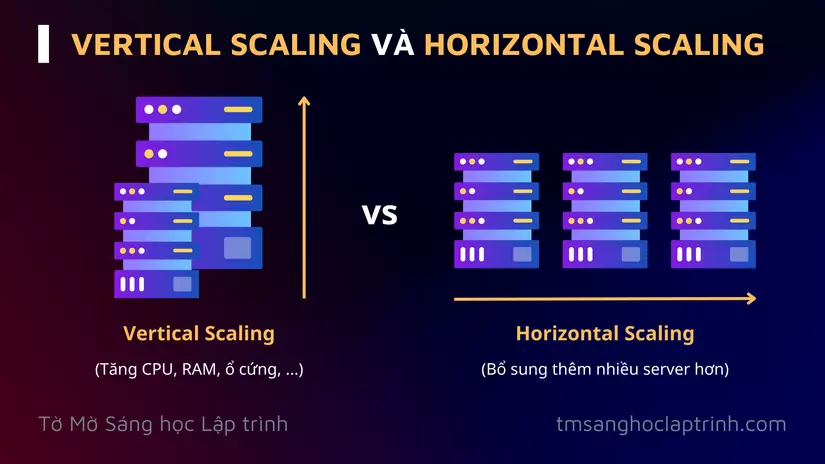
Ưu điểm:
-
Khả năng mở rộng cao: Có thể thêm nhiều server để đáp ứng nhu cầu dữ liệu ngày càng tăng.
-
Độ tin cậy cao hơn: Giảm nguy cơ gặp phải single point of failures, do đã có nhiều server giúp phân tải công việc.
Nhược điểm:
-
Quản lý phức tạp hơn: Cần phải quản lý nhiều database server, cũng như cơ chế phân chia dữ liệu cho phù hợp.
-
Nếu ứng dụng của bạn ban đầu không được triển khai theo hướng Horizontal Scaling, thì bạn sẽ phải thực hiện khá nhiều thay đổi để có thể hỗ trợ phân tán dữ liệu.
Khi nào nên sử dụng Horizontal Scaling???
-
Khi hệ thống cần xử lý lượng dữ liệu rất lớn và số lượng truy vấn cao mà một server duy nhất không thể xử lý được.
-
Khi yêu cầu hệ thống có khả năng mở rộng và khả năng chịu lỗi cao.
Có 2 phương pháp để triển khai Horizontal Scaling, đó là: Sharding (Phân mảnh dữ liệu) và Replication (Sao chép dữ liệu)
2.1. Sharding (Phân mảnh dữ liệu)
Sharding sẽ phân chia các database lớn thành các phần nhỏ hơn, được gọi là các shard (trong tiếng Việt "shard" có nghĩa là "mảnh vỡ").
Các shard sẽ có schema giống nhau, mặc dù dữ liệu thực tế trên mỗi shard là duy nhất cho shard đó.
Hình vẽ dưới đây minh hoạt về một database được phân mảnh.
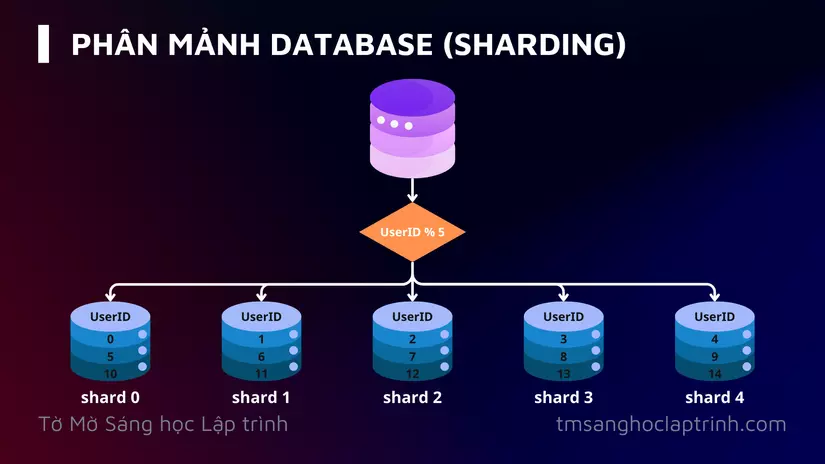
Dữ liệu người dùng được phân bổ cho các database server khác nhau dựa trên UserID.
Bất cứ khi nào bạn truy cập dữ liệu, một hàm băm được sử dụng để tìm shard tương ứng với user đó.
Ví dụ, chúng ta lấy UserID % 5 làm hàm băm.
-
Khi này, nếu kết quả
UserID % 5 == 0, shard 0 được sử dụng để lưu trữ, thêm, sửa, xóa, truy vấn dữ liệu của user đó. -
Tương tự như vậy, nếu
UserID % 5 == 1, shard 1 sẽ được sử dụng. -
...
Yếu tố quan trọng nhất cần xem xét khi thực hiện chiến lược phân vùng (sharing) là sự lựa chọn sharding key.
Sharding key (hay một số tài liệu khác còn gọi là partition key) bao gồm một hoặc nhiều cột, dùng để xác định cách phân phối dữ liệu.
Như trong ví dụ ở trên, UserID đã được chọn là sharding key.
Sharding key cho phép bạn truy xuất và sửa đổi dữ liệu một cách hiệu quả, bằng cách định tuyến các truy vấn đến chính xác database tương ứng.
Ưu điểm:
-
Cải thiện hiệu suất: Giảm tải công việc trên mỗi server.
-
Khả năng mở rộng: Dễ dàng thêm nhiều shard khi cần.
Nhược điểm:
Sharding là một kỹ thuật rất hay để scale database, nhưng nó cũng không phải là một giải pháp hoàn hảo và cần thiết cho mọi trường hợp.
Nó có thể gây ra sự phức tạp và những thách thức mới cho hệ thống:
Thách thức 1 - Resharding data:
-
Tức là việc tái cấu trúc lại việc phân phối dữ liệu vào các shard. Việc này thường xảy ra trong trường hợp phân phối dữ liệu không đồng đều, một số shard bị quá tải do các user trong shard này tăng trưởng dữ liệu quá nhanh.
-
Khi ấy, bạn sẽ cần phải update lại sharding function và phối phối dữ liệu sang các shard khác.
-
Một trong những kỹ thuật để xử lý việc này đó là Consistent hashing, nếu các bạn quan tâm có thể comment bên dưới bài viết để mình sắp xếp chia sẻ về kỹ thuật này trong một bài viết khác nhé.
Thách thức 2 - Celebrity problem hay Hotspot key problem:
- Lấy một ví dụ dễ hiểu liên quan đến cái tên của vấn đề này - Celebrity (tiếng Việt nghĩa là Người nổi tiếng, kiểu ngôi sao đồ đó)
Thử tưởng tượng bạn đang quản lý ứng dụng mạng xã hội, mà dữ liệu của Sếp Sơn Tùng MTP, couple Ninh Dương, anh Lý Hải, Lee Min Hô Đồng Nai, Tộc trưởng Độ Mixi xếp vào chung 1 shard xem.
Chắc hẳn sẽ rất nhanh chóng, lượng truy cập vào shard này sẽ gây ra tình trạng quá tải. Và đương nhiên các fan và antifan sẽ không thể đọc dữ liệu trên trang cá nhân của những người nổi tiếng này được nữa.
Một giải pháp để có thể giải quyết vấn đề này, đó là phân phối mỗi người nổi tiếng này vào một shard riêng.
Thách thức 3 - Join và Denormalization:
Khi một database đã được phân mảnh thành nhiều shard, sẽ rất khó để thực hiện các thao tác JOIN dữ liệu trên các shard.
Một cách giải quyết phổ biến là denormalize database. Hiểu đơn giản thì đây là cách lưu dữ liệu dư thừa vào các bảng, để các truy vấn có thể được thực hiện trong một bảng duy nhất, thay vì phải JOIN nhiều bảng với nhau.
Nhưng đương nhiên việc thực hiện denormalize database sẽ không hề dễ dàng (Nhiều bạn cứ nghĩ là đơn giản, cho đến khi dữ liệu ngày càng phát sinh lên nhiều).
-
Vì nó có thể gây ra sự không nhất quán giữa dữ liệu trong bảng gốc và dữ liệu được lưu dư thừa trong các bảng khác.
-
Ngoài ra, mỗi khi
INSERT,UPDATE,DELETEdữ liệu trong bảng gốc, chúng ta lại phải cân nhắc tới việcUPDATEdữ liệu vào bảng lưu dư thừa kia. -
Và đương nhiên, lưu dư thừa dữ liệu đồng nghĩa với việc bạn sẽ phải tốn nhiều dung lượng database hơn.
2.2. Replication (Sao chép dữ liệu)
Định nghĩa:
Database Replication có thể được sử dụng trong nhiều hệ quản trị cơ sở dữ liệu, thường có mối quan hệ Master - Slave (Chủ nhân - Nô lệ)
-
Master database thường chỉ hỗ trợ các thao tác ghi dữ liệu. Tức là, tất cả các câu lệnh như
INSERT,UPDATE,DELETEsẽ thực hiện trên master database. -
Còn các Slave database sẽ copy dữ liệu từ master database và chỉ hỗ trợ các thao tác đọc dữ liệu.
Mình đã có một bài viết trình bày về kỹ thuật này trên blog, các bạn có thể đọc lại nhé: "Database Replication - Chìa khóa giúp các hệ thống vận hành trơn tru"
Lời nhắn
Trên đây là nội dung liên quan đến các kỹ thuật Scale Database.
Đây là một trong những nội dung rất quan trọng trong "System Design - Thiết kế Hệ thống", và thường xuyên được triển khai trong các dự án lớn.
Hi vọng bài viết này đã giúp bạn dễ dàng hình dung thông qua các ví dụ minh họa dễ hiểu mà mình đưa ra.
Follow mình trên Facebook "CLB Lập trình - THPT Ngọc Tảo" hoặc kênh Youtube "Tờ Mờ Sáng học Lập trình" để cùng nhau học tập, chia sẻ những kiến thức công nghệ và lập trình hoàn toàn miễn phí nhé!
Facebook CLB Lập trình - THPT Ngọc Tảo: https://www.facebook.com/clb.it.ngoctao/
Youtube Tờ Mờ Sáng học Lập trình: https://www.youtube.com/@tmsangdev
Hẹn gặp lại 👋
BẠN CÓ THỂ ĐỌC THÊM
Clean Architecture: A Craftsman’s Guide to Software Structure and Design - Robert C. Martin
Designing Data – Insensitive applications - Martin Kleppmann
System Analysis and Design - Alan Dennis, Barbara Haley Wixom, Roberta M. Roth
System Design Interview - Alex Xu
Modern Systems Analysis and Design - Joseph Valacich, Joey George
Head First Design Patterns - Eric Freeman, Elisabeth Robson