Chào mọi người, lại là mình đây, ở phần trước mình đã giới thiệu với mọi người về Window Functions Phần I. Nếu chưa rõ nó là gì thì mọi người nên đọc lại trước nha, để nắm được định nghĩa và các key words, tránh mắt chữ O mồm chứ A vì phần này mình chủ yếu sẽ thực hành với các Window Functions.
I. ROW_NUMBER()
Tên hàm đã nói lên tất cả, đánh số thứ tự các bản ghi theo thứ tự order với từng partition.
Ví dụ: đánh số thứ tự học sinh theo từng lớp chẳng hạn, hãy cố thử nghĩ cách làm nếu không sử dụng Window Functions nhé, khá vất đấy =))
Còn khi sử dụng Row_number() thì ngắn gọn thôi
SELECT row_number() over(PARTITION BY s.class_id ORDER BY s.name) AS STT, c.name AS class_name, s.*
FROM students AS s
JOIN classes AS c ON s.class_id = c.id
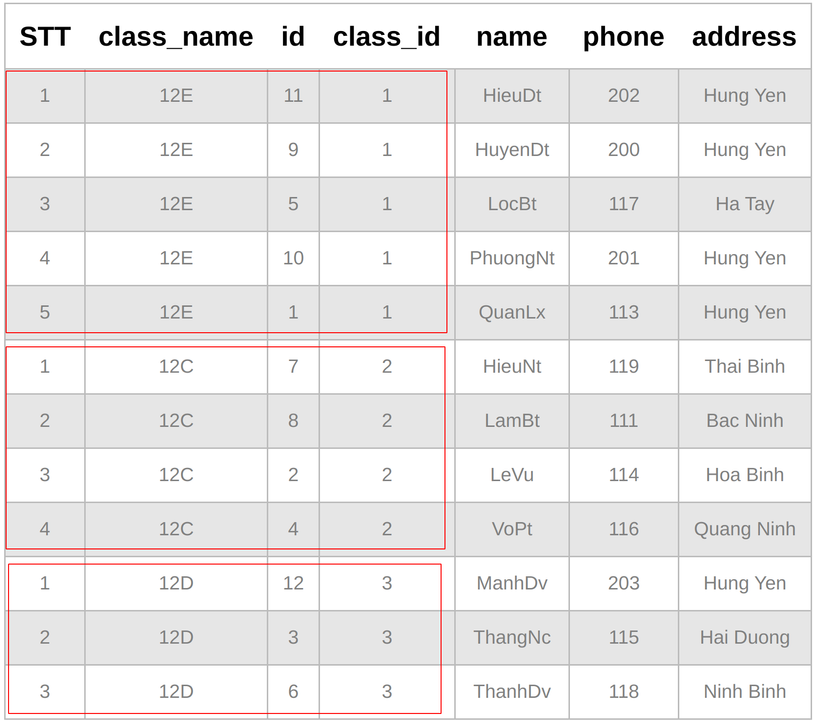
Bạn thấy không, "PARTITION BY s.class_id" chia table ra làm 3 khối dựa vào class_id và đếm thứ tự lần lượt các bản ghi tương ứng với khối - window của chính bản ghi đó.
Đơn giản nhỉ. 
II. RANK()
Xếp rank, vâng. Thật sự là trong quá trình làm việc, mình rất hay ĐƯỢC Khách hàng yêu cầu lấy data để điều tra, tracking, xếp rank trao thường, bla bla. . . Xếp rank ở đây không đơn giản là chỉ order nó ra là xong đâu, còn phải lấy vị trí xếp rank rồi xếp rank theo tiêu chí gì gì nữa cơ. Mệt.
Tiếp với ví dụ trên, mình thêm cột score_AVG điểm trung bình của học sinh r xếp rank chúng nhé.
Select * from students
order by score_AVG DESC
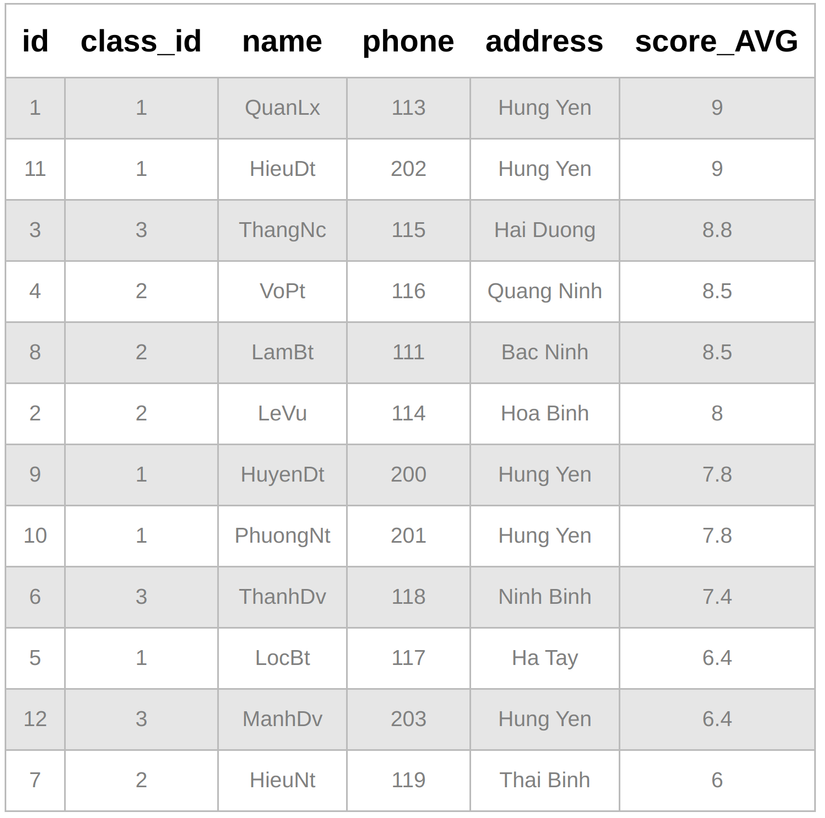
Đơn giản đúng không, nhưng query như này thì connit nó cũng làm đc, mình cần lấy cả vị trí ranking cơ. Đấy, thử đi...
Select *, rank() over(order by score_AVG DESC) as ranking from students
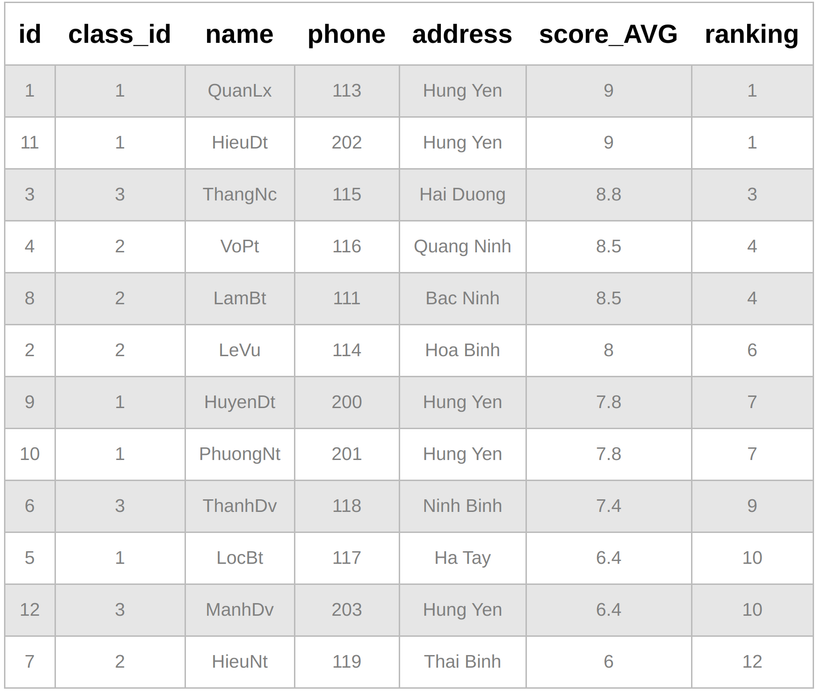
Quá nhanh, quá nguy hiểm đúng không? =))) Nhưng cùng một lớp xếp rank vơi nhau làm *éo gì. Xếp rank theo lớp đi... OK, có ngay
SELECT c.name, s.*, rank() over(PARTITION BY s.class_id ORDER BY s.score_AVG DESC) AS ranking
FROM students AS s
JOIN classes AS c ON s.class_id = c.id
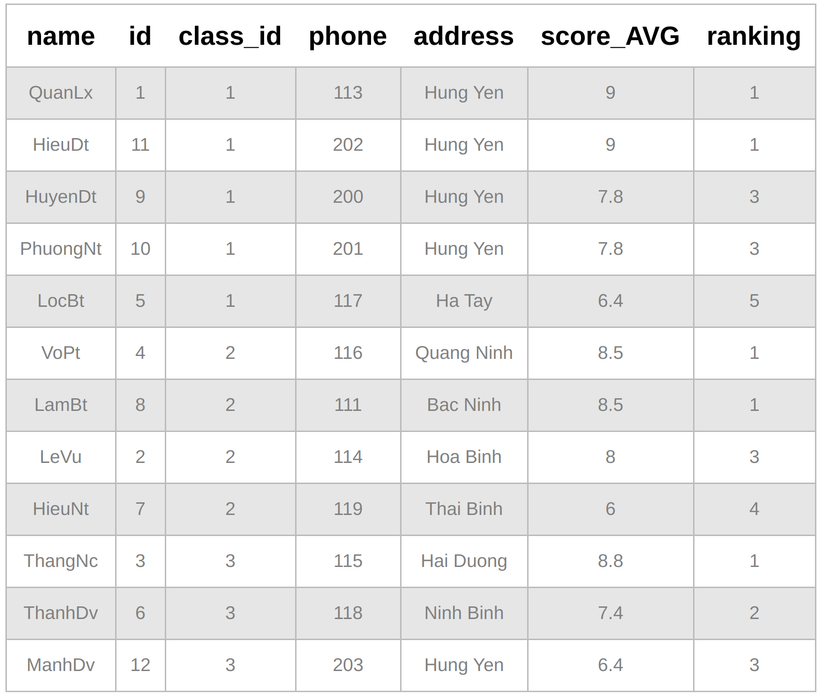
Tén ten, có vẻ ngon rồi đúng không, nhưng bạn có để ý kĩ là trường hợp nếu rank bằng nhau thì sẽ bị miss các rank sau không?
ví dụ vs class_id = 1, có 2 người xếp hạng 1 và 3 nhưng lại không có ai xếp hạng 2 và 4. Kì quặc!? Không hẳn nhé, nó sẽ có ích trong một số bài toán. Còn để đáp ứng từ A-Z thì xin mời đến function tiếp theo.
III. dense_rank()
Ở bài trước chúng ta đã nói qua cộng với một chút Spoil ở function trên thì đại loại, nó tương tự như hàm Rank() nhưng thứ tự xếp rank sẽ theo thứ tự lần lượt chứ không có nhảy cóc từ 1 -> 3 như trên. Tiếp tục với ví dụ trên nhé
Xếp hạng điểm học sinh thoe từng lớp
SELECT c.name, s.*, dense_rank() over(PARTITION BY s.class_id ORDER BY s.score_AVG DESC) AS ranking
FROM students AS s
JOIN classes AS c ON s.class_id = c.id
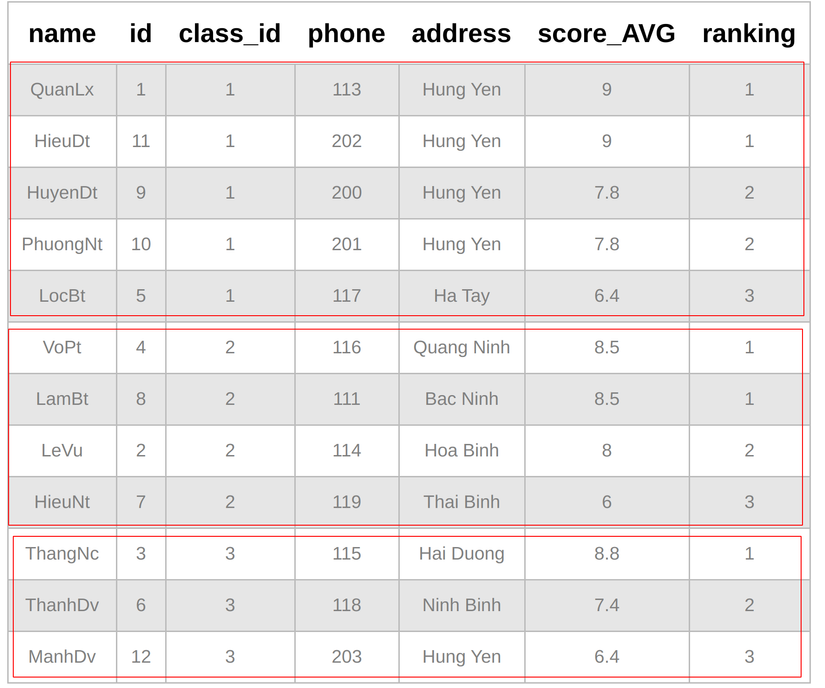
Ngon chưa!.
IV. LAG() và LEAD()
2 hàm này khá hữu ích cho việc tracking sự phát triển, doanh thu của một công ty theo tháng, hay tiến độ học tập của học sinh qua từng năm theo từng môn học. bằng cách so sánh row hiện tại với các row trước - LAG() hay các row sau - LEAD(). Cú pháp đầy đủ:
- LAG(expr [, N[, default]])
Hàm trả về giá trị của n hàng trước kể từ row hiện tại, nếu không tồn tại hàng đó thì trả về giá trị default. Trường hợp để trống N & default thì mặc định N = 1 và default = NULL.
- LEAD(expr [, N[, default]])
Tương tự như hàm LAG nhưng là trả về giá trị của hàng sau tính từ row hiện tại.
Cùng test về độ mọc sừng của mình theo từng năm nhé.
SELECT *, LAG(heighs) OVER(PARTITION BY name ORDER BY years ASC) AS LAG_heigh, (heighs - LAG(heighs) OVER(PARTITION BY name ORDER BY years ASC)) AS LAG_DIFF, LEAD(heighs) OVER(PARTITION BY name ORDER BY years ASC) AS LEAD_heigh, LAG(heighs, 2, -1) OVER(PARTITION BY name ORDER BY years ASC) AS LAG_heigh2
FROM heigh_infos
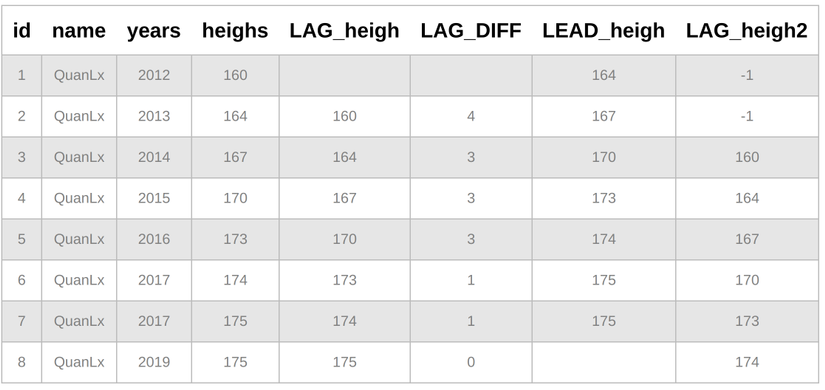
Từ bảng trên, dựa vào LAG_DIFF, năm nào mình cũng mọc sừng cho đến năm 2018 trở đi mình đã tìm được tinh yêu đích thực. =))
V FIRST_VALUE() & LAST_VALUE() & NTH_VALUE()
Nhìn chung thì 3 hàm này cũng same same 2 hàm trên, cũng để trả về giá trị của 1 hàng, khác nhau là vị trí của hàng đó thối.
- 2 hàm trước (LAG - LEAD) thì trả về giá trị của n hàng trước/sau kể từ row hiện tại
- 3 hàm này thì trả về vị trí đầu, cuối hoặc bất kì của partition - window dựa vào thứ tự ORDER BY
Cú pháp đơn giản:
- FIRST_VALUE(expr)
- LAST_VALUE(expr)
- NTH_VALUE(exp, n)
SELECT *, FIRST_VALUE(heighs) OVER( PARTITION BY name ORDER BY heighs ASC ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) AS min_heigh, LAST_VALUE(heighs) OVER( PARTITION BY name ORDER BY heighs ASC ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) AS max_heigh, NTH_VALUE(heighs, 3) OVER( PARTITION BY name ORDER BY heighs ASC ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) AS random_heigh
FROM heigh_infos
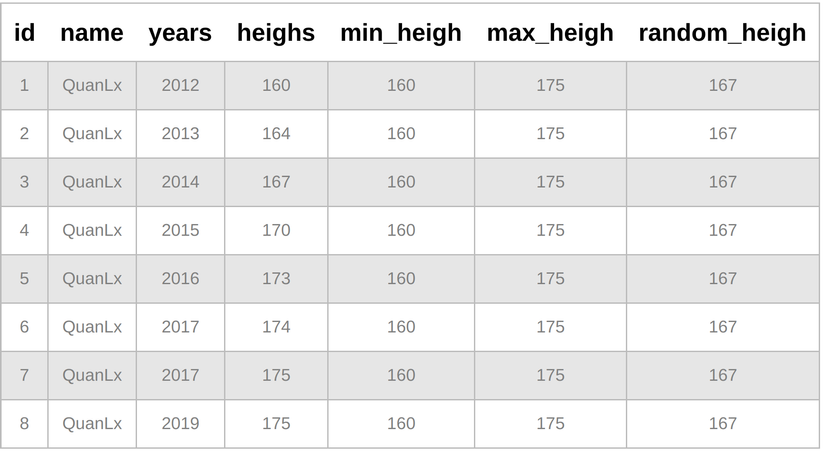
Các hàm còn lại mình thấy khá ít dùng, nếu mọi người muốn tìm hiểu thì có thể đọc doc ở đây nha.
Bài toán x10 lương
Nói đùa mọi người vậy thôi, tuy không đc x10 lương nhưng bạn sẽ được đánh giá cao nếu giải quyết đc bài toán này (Cá nhân mình nghĩ vậy - có thể vẫn dễ đối với mọi người thì mn đừng cười mình nha) Bài toán này chính xác là xảy ra đối với dự án mình: (mình sẽ biến tấu bài toán đi nhưng vẫn giữ được ý chính nhằm đảm bảo tính bảo mật dự án nha) Tóm tắt: 1 bảng ví của users có khoảng hơn 60tr bản ghi. mỗi user có rất nhiều account (có thể lên đến mấy trăm nghìn bản ghi 1 user) với số tiền khác nhau, các account có sự ưu tiên, tức là phải tiêu hết account này mới được sử dụng đến account khác. Mỗi 1 lần giao dịch bạn phải trừ tiền lần lượt ở các account (đã đảm bảo check đủ tiền). Và 1 giờ 1 user giao dịch rất rất nhiều lần. Hãy giải quyết, tối ưu query để giải bài toán trên.
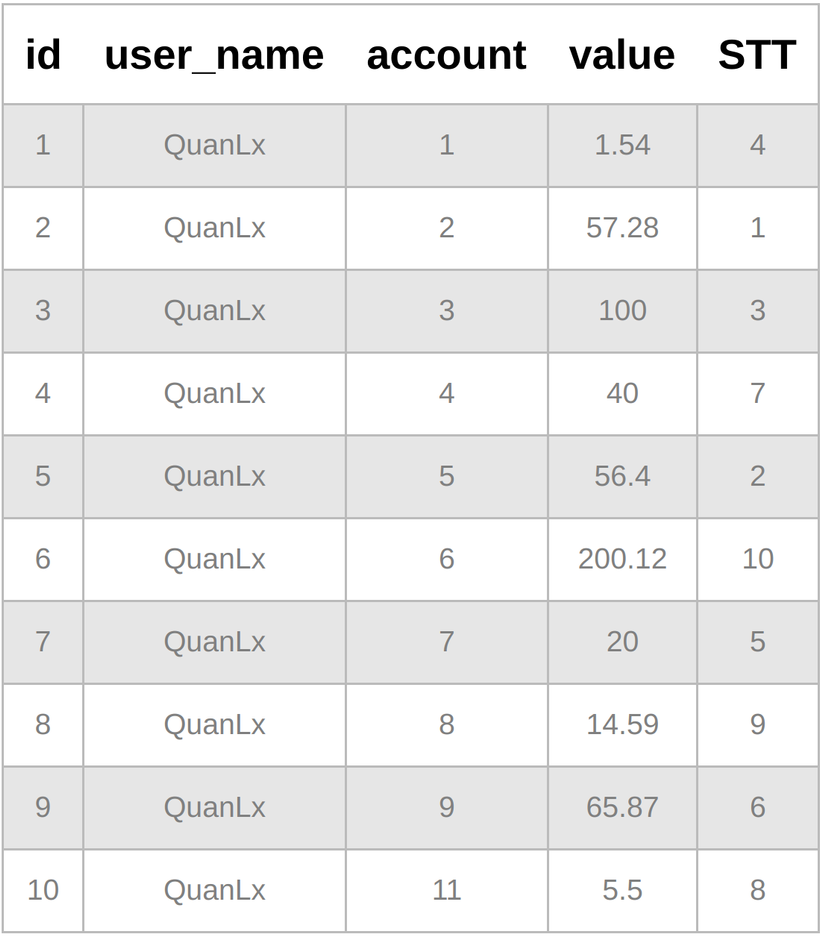
*Ví dụ data cho mọi người hình dung:
- user
QuanLxcó 10 bản ghi, tổng 561.3$ - Trong 1 giao dịch cần 250$
- -> Lấy ra ít nhất số bản ghi
walletsđể hoàn thành giao dịch trên, lưu ý trừ tiền theoSTTcủa account đối với mỗi users.
Hãy suy nghĩ thử xem trước khi kéo xuống xem gợi ý nha.

Solution: Thoạt nhìn thì thấy có vẻ đơn gián đúng không? cứ query lấy ra hết các ví tiền của user theo thứ tự ra rồi For trừ tiền dần thôi, bao giờ đủ thì break. Nhìn có vẻ ok, nhưng nên nhớ, table có đến 60tr bản ghi, mỗi user có thể lên đên hơn 100k bản ghi. chẳng hạn giao dịch chỉ cần đến 1 bản ghi thì cũng lôi hết bản ghi ra thì khác nào vác Dao mổ trâu để chặt gà à. Không ổn rồi: Cần lấy ra đủ bản ghi để xử lý thôi!!
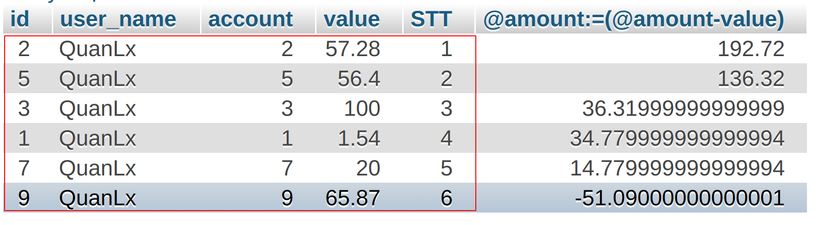
Cách 1: Cách này mình làm trước khi biết đến Window Functions
SET @amount = 250.0; SELECT *, @amount:=(@amount-value)
FROM (SELECT * FROM wallets ORDER BY STT ASC) AS tmp
WHERE @amount >= 0;
kết quả:
Cách 2: Sử dụng Window Functions
SET @amount = 0.0; SELECT *, @amount:=amount from (SELECT *, SUM(value) over(PARTITION BY user_name ORDER BY STT ASC) AS amount FROM wallets) AS tmp
WHERE @amount < 250
Kết quả:
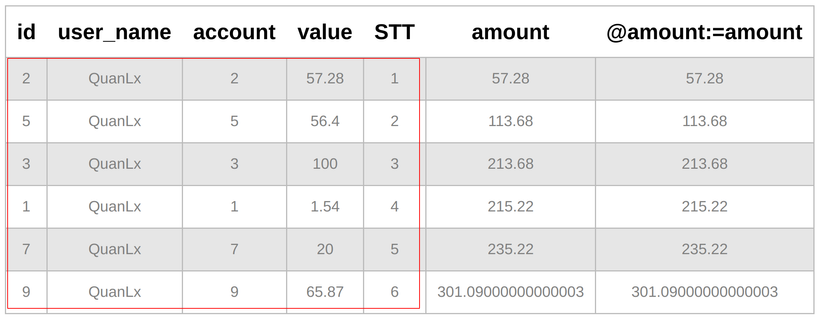
Cả 2 cách trên đều trùng khớp kết quả, đừng thấy query ngắn mà đơn giản nhé, chứ thực tế bài toán của mình phải join 3-4 bảng mới ra đc cái bảng original cho mọi người đó, chứ không có ăn sẵn như kia đâu, là mình demo ý chính thôi.
Bài toán số 2: (ngoài lề) Bài này mình đang làm trong dự án luôn. Tóm tắt qua thì, khi chơi bài Baracat (đặt cược) 1 user có thể thắng-thua-hòa (có 3 cửa: Player-Banker-Tie, luật thì mọi người có thể tìm hiểu trên GG nha), bây giờ Khách Hàng muốn tạo event dạng: trao thưởng cho TOP những người chơi thắng liên tiếp cao nhất, TOP những người chơi thua liên tiếp nhỏ nhất... (Còn nhiều chỉ tiêu để 1 user đc xếp rank lắm, nào là chơi tối thiếu bao nhiêu ván, phải cược vào cửa nào... Nếu nói hết tiêu chí ra để xếp rank thì chắc choáng luôn). Để tiện dễ hình dung thì mình sẽ convert sang 1 dạng bài mà chúng ta vẫn hay làm giải thuật.
Tìm dãy số dương liên tiếp dài nhất (0 thì skip), nhưng thay vì là array thì đây lại là database, và không phải là 1 dãy, mà là rất nhiều dãy tương ứng với nhiếu users. Nhưng, cứ phát triển từ base trc đã
Lại là data mẫu cho mọi người dễ tưởng tượng (cho 1 user)
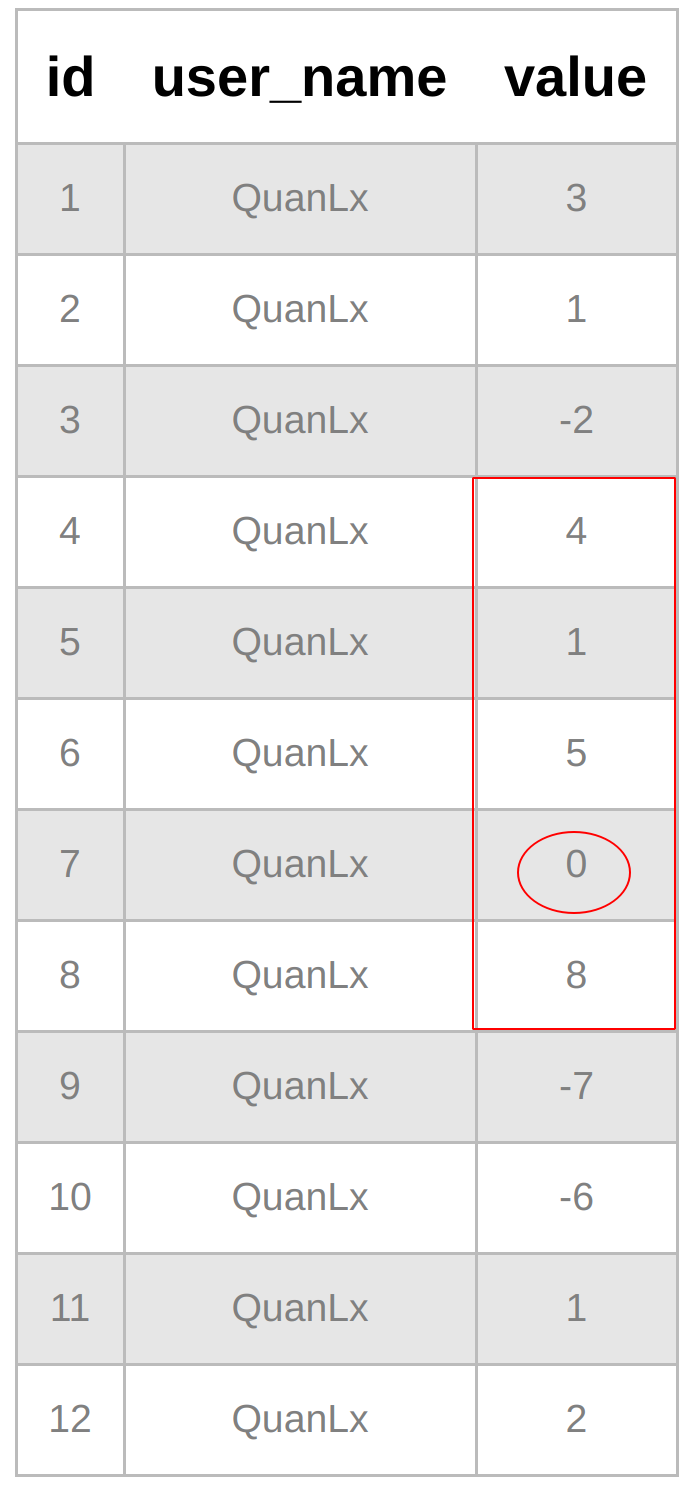
Đáp án là 4, mọi người thử làm xem có ra k nhé =)) Nếu có gì thắc mắc thì comment nha. mình cùng nhau trao đổi.
Lời giải chi tiết mình sẽ upload sau nha (Hoặc mọi người có thể ping mình )
Cám ơn mọi người đã theo dõi bài viết của mình! Chúc mọi người một ngày làm việc vui vẻ!.
Tài liệu liên quan
https://dev.mysql.com/doc/refman/8.0/en/window-function-descriptions.html.
https://dev.mysql.com/doc/refman/8.0/en/window-functions-usage.html.
https://dev.mysql.com/doc/refman/8.0/en/window-functions-frames.html.