Điểm cải tiến:
- Kiến trúc transformer cho phép thực hiện các phép tính song song -> giảm đáng kể thời gian train/inference, tận dụng được sức mạnh tính toán của multi-GPU.
- Học biểu diễn chuỗi tốt hơn nhờ cơ chế attention -> một chuỗi đơn được biểu diễn nhờ sự kết hợp thông tin của toàn bộ chuỗi, thông tin quan trọng từ những vị trí khác trong chuỗi được khuếch đại, ngược lại thông tin không quan trọng sẽ bị bỏ qua. Ví dụ với chuỗi là câu nói “Trời hôm nay trở lạnh vì gió mùa tràn về”, chuỗi đơn sẽ là các từ trong câu. Dễ thấy từ “lạnh” có sự liên quan với từ “gió mùa”, khi biểu diễn từ “lạnh” cơ chế attention từ sẽ khuếch đại thông tin của từ “gió mùa” và kết hợp với thông tin của chính từ đó để tạo thành một biểu diễn tốt hơn cho từng từ.
Kiến trúc transformer có thể áp dụng cho nhiều bài toán khác nhau, tuy nhiên chúng ta giả định rằng mình đang xử lý bài toán translation để dễ hình dung trong việc mô tả kiến trúc và cách hoạt động của transformer.
Kiến trúc của transformer gồm 2 phần chính là encoders(là 1 ngăn xếp gồm 6 khối encoder kiến trúc giống nhau) và decoders(là 1 ngăn xếp gồm 6 khối decoder giống nhau).
- Mỗi khối encoder có 2 layer chính: self-attention và feed forward.
- Mỗi khối decoder có 3 layer chính: sef-attention, encoder-decoder attention và feed forward.
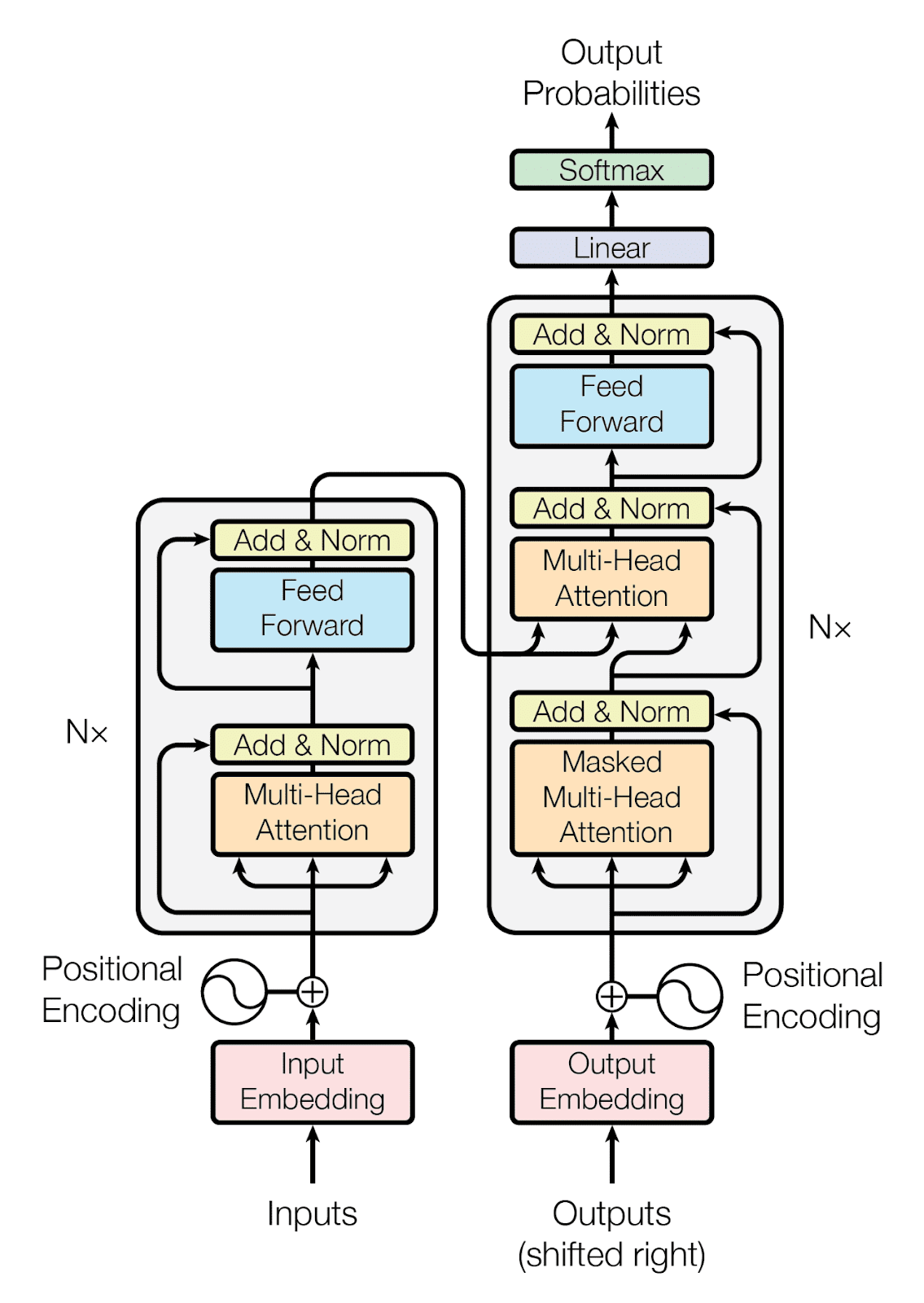
The Encoder-Decoder Structure of the Transformer Architecture Taken from “Attention Is All You Need“
I. Kiến trúc của mỗi khối Encoder:
1. Input embedding
Đầu vào của khối encoder đầu tiên là các vector embeddings của các từ trong câu. Đầu vào của các khối encoder còn lại là đầu ra của khối endcoder phía dưới. Các embeddings được tạo thành từ việc kết hợp vector word embedding + positional embedding.
- Vector word embedding là vector biểu diễn các từ được tạo ra từ các pre-model như word2vec, glove…
- Vector positional embedding là vector biểu diễn thứ tự của các từ trong chuỗi, chúng mang thông tin về vị trí và khoảng cách của các từ. Nếu không có thông tin này việc học biểu diễn cho câu “Trời hôm nay trở lạnh vì gió mùa tràn về” và câu “về tràn gió mù trở lạnh vì hôm nay Trời” sẽ không có gì khác biệt. Rõ ràng vị trí của các từ mang ý nghĩa quan trọng, việc thay đổi vị trí của một từ cũng có thể làm thay đổi ý nghĩa của cả câu. Vector positional embedding(PE) được tính theo công thức:
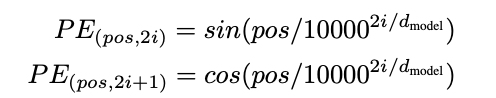
Trong đó dmodel là số chiều của vector, pos là số vị trí(0, 1, 2, 3….), i là chiều thứ i của vector(i ∈ 0, 1, 2...dmodel)
2. Layer self-attention
Phép tính đầu tiên trong sef-attention là nhân mỗi vector embedding đầu vào với 3 ma trận trọng số Wq, Wk, Wv để tạo ra 3 vector q, k v. Các ma trận trọng số này sẽ được cập nhật trong quá trình đào tạo. Vector q và k được dùng để tính trọng số khuếch đại thông tin cho các từ trong câu. Vector v là vector biểu diễn của các từ trong câu.
Ví dụ ta có 2 vector embeddings(tương ứng với 2 từ đầu vào “Trời”, “lạnh”) là x1, x2. Nhân 2 vector này với 3 ma trân Wq, Wk, Wv ta được tập các vector: {q1, q2}, {k1, k2}, {v1, v2}. Để tính toán vector biểu diễn cho từ “Trời”. Đầu tiên ta cần tính trọng số khuếch đại thông tin cho mỗi từ(gọi là Attention), Attention cho từ “Trời”(a1) và từ “lạnh”(a2) được tính theo công thức sau:
Trong đó d là số chiều của vector k. Cuối cùng vector biểu diễn cho từ “Trời” được tính theo công thức:
Tương tự việc tính toán vector biểu diễn cho các từ còn lại cũng được thực hiện như trên. Việc sử dụng multi-gpu để thực hiện các phép tính song song không được thực hiện ở bước này vì để tính được vector z của 1 từ ta cần có vector k và v của các từ khác.
3. Multi-Head Attention
Kiến trúc transformer được thiết kế với 8 lớp self-attention kiến trúc giống hệt nhau nhưng trọng số của 3 ma trận Q, K, V khác nhau. Việc tính toán của 8 layer này được thực hiện song song. Các vector biểu diễn qua mỗi lớp self-attention sẽ được nối lại với nhau sau đó được nhân với một ma trận trọng số Wo để nén thông tin từ 8 vector(8 vector này cùng biểu diễn cho 1 từ) thành một vector duy nhất. Vector này sau đó đi qua một bước gọi là Add & Normalize nữa trước khi đưa vào layer Feed Forward.
Ý nghĩa của cơ chế multi-head này là để tăng thêm phần chắc chắn trong việc quyết định thông tin nào cần khuếch đại, thông tin nào cần bỏ qua. Vì rằng 8 cái đầu sẽ cùng vote và đưa ra lựa chọn khách quan, đáng tin cậy hơn 1 cái đầu.
4. Position-wise Feed-Forward Networks(FFN)
Các vector sau khi đi qua bước Add & Normalize(sẽ được nói ở mục sau) sẽ được gửi tới FFN. Lớp này bao gồm 2 tầng biến đổi thông tin và 1 hàm ReLU(các giá trị < 0 được gán lại = 0) ở giữa. Dropout với tỉ lệ 0.1 cũng được áp dụng ở lần biến đổi thứ nhất sau khi các vector qua hàm ReLU.
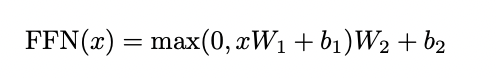
Sau khi qua layer FFN các vector cũng phải qua bước Add & Normalize trước khi đi vào khối encoder kế tiếp.
Ý nghĩa của layer FFN này là để học mối quan hệ tiềm ẩn giữa các vector độc lập mà chưa được mô tả rõ ràng. Khác với mối quan hệ giữa các từ được khuếch đại qua lớp self-attention, vẫn còn những mối quan hệ tiềm ẩn khác không thể diễn giải bằng công thức toán học sẽ được học thông qua lớp này.
5. Add & Normalize
Ở bước này, Các vector đầu ra từ lớp con (multi-head self-attention và feed forward) sau đó qua bước dropout với tỉ lệ 0.1, rồi cộng thêm vector đầu vào(vector trước khi bị biến đổi), cuối cùng được normalized theo một công thức nào đó rồi chuyển vào layer kế tiếp. Ý nghĩa của bước này là để bổ sung thêm thông tin nguyên bản, tránh bị mất mát quá nhiều thông tin sau khi qua các phép biến đổi ở các layer multi-head self-attention và feed forward.
6. Đầu ra của khối encoder cuối cùng
Các vector sau khi qua lớp FFN của khối encoder cuối cùng sẽ được nhân với 2 ma trận trọng số K và V để tạo thành các cặp vector {(k1, v1), (k2, v2),...(kn, vn)} ứng với câu có n từ. Các vector này sẽ được dùng để tính vector biểu diễn z trong lớp encoder-decoder attention.
II. Kiến trúc của mỗi khối decoder
Các layer trong khối decoder được thiết kế tương tự khối encoder tuy nhiên có 1 số điểm khác biệt sau:
- Đầu vào của lớp sef-attention ở lần đầu tiên được là vector được tạo thành bởi embedding của 1 ký tự [start] + vector positonal embedding. Vector đầu vào ở các lần kế tiếp được tạo thành bởi vector output của layer FFN của khối decoder cuối cùng + vector positonal embedding.
- Lớp self-attention chỉ kết hợp thông tin từ các từ trước nó.
- Lớp encoder-decoder attention chỉ tính toán vector q dựa trên đầu ra của self-attention, vector k và v được lấy từ output của khối encoder.
- Việc tính toán được thực hiện cho đến khi decoder dự đoán được ký tự kết thúc [end]
- Đầu ra của lớp FFN cuối cùng sẽ được đi qua lớp Linear để biến đổi các vector này thành một vector có số chiều bằng số từ trong bộ vocabulary. Mỗi giá trị của 1 phần tử trong vector thể hiện điểm số cho 1 từ trong bộ từ vựng. Vector này sau đó được cho qua 1 hàm softmax để biến chúng thành một phân phối xác suất(tất cả phần tử >0 và tổng =1). Từ mà có xác suất cao nhất sẽ là từ được chọn.