Công cụ AI chống lại ngôn ngữ thù hận trên không gian mạng.
Giới thiệu
Mạng xã hội giúp chúng ta kết nối với mọi người và chia sẻ suy nghĩ của mình. Nó có thể rất tuyệt vời để học hỏi những điều mới và gặp gỡ những người mới. Tuy nhiên, một số người sử dụng ngôn ngữ xấu trên mạng xã hội để làm tổn thương người khác. Họ có thể sử dụng những lời lẽ thù hận để khiến bản thân cảm thấy tốt hơn so với người khác. Điều này có thể khiến không gian mạng trở nên không an toàn và không thân thiện.

HateBERT chống lại ngôn ngữ thù hận trực tuyến bằng cách tận dụng AI để phát hiện ngôn ngữ xúc phạm. Được đào tạo trên bộ dữ liệu RAL-E rộng lớn, nó xác định chính xác nội dung gây hại, bảo vệ các nền tảng trực tuyến như Twitter khỏi lời nói độc hại.
Tóm tắt
HateBERT giải quyết vấn đề nội dung gây hại trực tuyến bằng cách sử dụng AI để phát hiện ngôn ngữ xúc phạm. Nó làm điều này bằng cách đào tạo lại mô hình BERT mạnh mẽ trên một bộ dữ liệu khổng lồ được gọi là RAL-E, chứa đầy các ví dụ về ngôn ngữ thù hận và lạm dụng. Việc đào tạo chuyên biệt này cho phép HateBERT xác định chính xác nội dung gây hại, biến nó thành một công cụ có giá trị để bảo vệ không gian trực tuyến, đặc biệt là trên các nền tảng như Twitter.
Tóm gọn, HateBERT cung cấp cho ta 3 điều:
- HateBERT sử dụng AI để phát hiện ngôn ngữ xúc phạm nhằm giải quyết vấn đề nội dung gây hại trực tuyến.
- HateBERT được đào tạo lại trên bộ dữ liệu RAL-E khổng lồ chứa đầy các ví dụ về ngôn ngữ thù hận và lạm dụng.
- Việc đào tạo chuyên biệt cho phép HateBERT xác định chính xác nội dung gây hại, biến nó thành một công cụ có giá trị để bảo vệ không gian trực tuyến.
Bộ dữ liệu RAL-E: Nguồn dữ liệu phong phú
Bộ dữ liệu RAL-E, là một bộ dữ liệu quy mô lớn các bình luận trên Reddit bằng tiếng Anh, có sẵn công khai và được thu thập trên 3 bộ dữ liệu khác:
- OffensEval 2019: Chứa 14.100 tweet được chú thích cho ngôn ngữ xúc phạm.
- AbusEval: Bản cập nhật của OffensEval, thêm chú thích ngôn ngữ lạm dụng.
- HatEval: Phần tiếng Anh của bộ dữ liệu chứa 13.000 tweet được chú thích cho ngôn ngữ thù hận chống lại người nhập cư và phụ nữ.
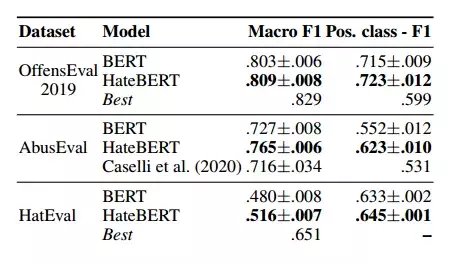
HateBERT vượt trội hơn mô hình BERT gốc trong việc xác định nội dung gây hại trên nhiều bộ dữ liệu. Điều đáng chú ý là dữ liệu đào tạo của HateBERT có thể được áp dụng hiệu quả trên nhiều nền tảng mạng xã hội khác nhau, cho thấy tính linh hoạt của nó.
Kết luận
Kết luận, HateBERT là một công cụ mạnh mẽ có thể giúp làm cho không gian trực tuyến an toàn hơn. Nó sử dụng AI để phát hiện ngôn ngữ gây hại, chính xác hơn các phương pháp cũ. Vì nó có thể được sử dụng trên nhiều nền tảng mạng xã hội khác nhau, HateBERT có tiềm năng tạo ra một internet thân thiện hơn cho mọi người.
Điều đáng sợ là có rất nhiều nội dung không phù hợp trên mạng xã hội. Hãy tưởng tượng con bạn nhìn thấy hình ảnh về ma túy, bạo lực hoặc bài đăng thù hận - điều đó có thể ảnh hưởng rất lớn đến cách chúng nhìn nhận thế giới. Chúng ta cần những công cụ như HateBERT để giúp bảo vệ trẻ em và làm cho không gian trực tuyến an toàn hơn.
Tài liệu tham khảo
-
Caselli et al. - HateBERT: Retraining BERT for Abusive Language Detection in English - URL:https://www.arxiv.org/abs/2010.12472
-
Devlin et al. - BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding - URL: https://arxiv.org/abs/1810.04805
Phụ lục
-
Xúc phạm: "chứa bất kỳ hình thức ngôn ngữ không thể chấp nhận nào (chửi thề) hoặc sự xúc phạm có mục tiêu, có thể là giấu kín hoặc trực tiếp."
-
Lạm dụng: một trường hợp cụ thể của ngôn ngữ xúc phạm, cụ thể là "ngôn ngữ gây tổn thương mà người nói sử dụng để xúc phạm hoặc làm tổn thương một cá nhân hoặc một nhóm cá nhân dựa trên phẩm chất cá nhân, ngoại hình, địa vị xã hội, ý kiến, tuyên bố hoặc hành động của họ."
-
Ngôn ngữ thù hận: "bất kỳ thông tin liên lạc nào miệt thị một người hoặc một nhóm dựa trên một số đặc điểm như chủng tộc, màu da, dân tộc, giới tính, khuynh hướng tình dục, quốc tịch, tôn giáo hoặc các đặc điểm khác."