Tùy chỉnh mô hình ngôn ngữ lớn (LLM) với dữ liệu của bạn
Trong bối cảnh các mô hình ngôn ngữ lớn (LLM) ngày càng được ứng dụng rộng rãi, việc tối ưu hóa và tùy chỉnh các mô hình này để phù hợp với các nhu cầu cụ thể của doanh nghiệp và người dùng trở nên vô cùng quan trọng. Bài viết này trình bày ba kỹ thuật chủ đạo để tùy chỉnh LLM: Few-Shot Prompting, Fine-Tuning, và Retrieval-Augmented Generation (RAG). Mỗi kỹ thuật đều có những ưu và nhược điểm riêng, từ việc cung cấp các ví dụ trong prompt để dạy mô hình thực hiện các tác vụ cụ thể, đến việc tối ưu hóa mô hình trên các tập dữ liệu nhỏ, và kết nối mô hình với cơ sở tri thức doanh nghiệp để cung cấp các phản hồi dựa trên dữ liệu mới nhất. Bằng cách kết hợp các kỹ thuật này, doanh nghiệp có thể xây dựng các hệ thống mạnh mẽ và hiệu quả hơn, tối ưu hóa hiệu suất của mô hình ngôn ngữ lớn, và đảm bảo rằng chúng đáp ứng được các yêu cầu cụ thể của từng ứng dụng.
Tại sao không huấn luyện LLM từ đầu?
1. Chi phí:
Huấn luyện một mô hình ngôn ngữ với 10 tỷ tham số có thể tốn khoảng một triệu đô la. Chi phí này bao gồm phần cứng cao cấp, điện năng tiêu thụ, và thời gian nhân lực để thiết lập và duy trì hệ thống. Đối với các tổ chức nhỏ và vừa, khoản chi phí này có thể không khả thi.
2. Yêu cầu về dữ liệu:
Cần một lượng dữ liệu khổng lồ để huấn luyện mô hình. Ví dụ, mô hình Llama-2 của Meta được huấn luyện trên 2 nghìn tỷ tokens. Thu thập và xử lý một lượng dữ liệu lớn như vậy là một thách thức lớn, đòi hỏi nguồn tài nguyên và công cụ chuyên dụng.
3. Chuyên môn:
Huấn luyện LLM đòi hỏi kiến thức sâu về hiệu suất mô hình, quản lý phần cứng, và hiểu rõ các giới hạn của mô hình. Điều này bao gồm hiểu biết về tối ưu hóa hyperparameter, quản lý bộ nhớ GPU, và các kỹ thuật tiên tiến khác trong lĩnh vực học máy.
4. Hallucination & thiếu hiệu quả
Có một paper mới toanh của Google từ hồi tháng 5/2024 chứng minh rằng việc fine-tuning một mô hình LLM không những thiếu hiệu quả trong việc học kiến thức mới mà còn có thể gây ra hallucination với các dữ liệu mà mô hình đã được train trước đó.
Các cách tùy chỉnh LLM
1. Few-Shot Prompting - In-context learning:
Định nghĩa:
Cung cấp các ví dụ trong prompt để dạy mô hình cách thực hiện các tác vụ cụ thể.
Ví dụ:
Yêu cầu mô hình dịch từ tiếng Anh sang tiếng Pháp bằng cách cung cấp một vài ví dụ trong prompt.
Dịch từ tiếng Anh sang tiếng Pháp:
1. Apple - Pomme
2. Orange - Orange
3. House - Maison
Hạn chế:
Giới hạn bởi cửa sổ ngữ cảnh của mô hình (ví dụ: một số mô hình chỉ nhận đến 4,096 tokens). Điều này có nghĩa là số lượng ví dụ và thông tin bạn có thể cung cấp trong một lần yêu cầu bị hạn chế.
2. Fine-Tuning:
Cái này mình xin phép skip vì bên trên vừa nói nó không hiệu quả rồi. Chắc phải túng quẫn lắm mới làm.
3. Retrieval-Augmented Generation (RAG):
Định nghĩa:
Kết nối mô hình ngôn ngữ với cơ sở tri thức của doanh nghiệp (ví dụ: cơ sở dữ liệu, wiki, cơ sở dữ liệu vector) để cung cấp các phản hồi dựa trên dữ liệu.
Ví dụ:
Một chatbot ảo truy cập cơ sở dữ liệu của công ty để trả lời các câu hỏi của khách hàng dựa trên dữ liệu mới nhất.
Ưu điểm:
- Truy cập vào dữ liệu mới nhất.
- Không cần tinh chỉnh.
Nhược điểm:
- Phức tạp hơn để thiết lập.
- Yêu cầu một nguồn dữ liệu tương thích.
So sánh các kỹ thuật
| Kỹ thuật | Khi nào sử dụng | Ưu điểm | Nhược điểm |
|---|---|---|---|
| Few-Shot Prompting | LLM hiểu chủ đề, thiết lập đơn giản | Không tốn chi phí huấn luyện, dễ triển khai | Giới hạn bởi cửa sổ ngữ cảnh, thêm độ trễ |
| Fine-Tuning | LLM hoạt động kém trên các tác vụ cụ thể | Cải thiện hiệu suất, không ảnh hưởng đến độ trễ | Yêu cầu dữ liệu đã gán nhãn, tốn công sức |
| RAG | Dữ liệu thay đổi nhanh chóng, giảm ảo tưởng | Truy cập dữ liệu mới nhất, phản hồi có cơ sở | Thiết lập phức tạp, yêu cầu nguồn dữ liệu tương thích |
1. Few-Shot Prompting:
- Ưu điểm: Không cần huấn luyện lại mô hình, có thể nhanh chóng điều chỉnh mô hình cho các tác vụ cụ thể.
- Nhược điểm: Bị giới hạn bởi dung lượng của cửa sổ ngữ cảnh, không thể giải quyết các tác vụ phức tạp yêu cầu thông tin lớn.
2. Fine-Tuning:
- Ưu điểm: Có thể cải thiện hiệu suất cho các tác vụ cụ thể, phù hợp cho các ứng dụng yêu cầu độ chính xác cao.
- Nhược điểm: Cần dữ liệu đã gán nhãn, tốn kém và mất thời gian để thực hiện.
3. Retrieval-Augmented Generation (RAG):
- Ưu điểm: Cung cấp thông tin mới nhất, không cần tinh chỉnh mô hình, linh hoạt cho các ứng dụng thực tế.
- Nhược điểm: Yêu cầu thiết lập hệ thống phức tạp, cần nguồn dữ liệu tương thích.
Kết hợp các kỹ thuật
Thường thì một sự kết hợp của các kỹ thuật trên được sử dụng dựa trên các yêu cầu cụ thể. Ví dụ, một mô hình có thể bắt đầu bằng cách sử dụng Prompt Engineering để thiết lập hiệu suất cơ bản, sau đó thêm ví dụ Few-Shot để cải thiện hiệu suất. Tiếp theo, có thể triển khai một hệ thống Retriever để kết nối mô hình với cơ sở tri thức doanh nghiệp. Cuối cùng, nếu cần thiết, mô hình có thể được tinh chỉnh để đảm bảo đầu ra có định dạng hoặc phong cách cụ thể.
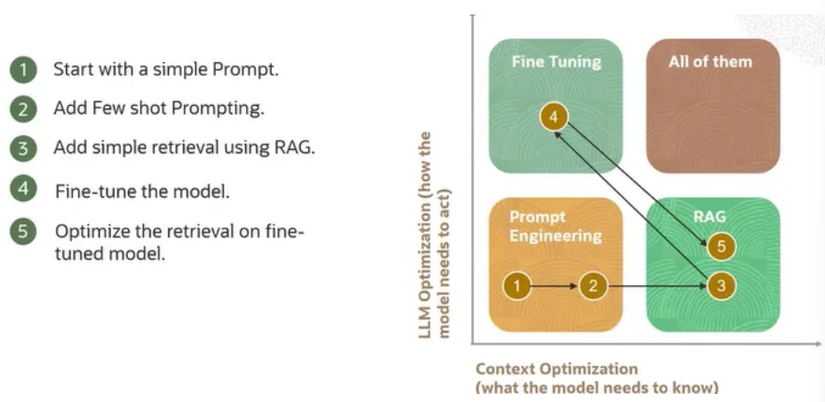
Quả trình tùy chỉnh LLM điển hình
1. Bắt đầu với Prompt Engineering:
Tạo một prompt đơn giản và đánh giá hiệu suất cơ bản. Điều này giúp xác định các điểm mạnh và điểm yếu ban đầu của mô hình.
2. Thêm ví dụ Few-Shot:
Nâng cao prompt bằng cách thêm một vài ví dụ để cải thiện hiệu suất. Điều này giúp mô hình học cách thực hiện các tác vụ cụ thể một cách tốt hơn.
3. Triển khai hệ thống Retriever:
Sử dụng RAG để liên kết mô hình với cơ sở tri thức doanh nghiệp. Điều này cung cấp thông tin chính xác và cập nhật cho mô hình, giúp nó đưa ra các phản hồi tốt hơn.
4. Fine-Tuning:
Tinh chỉnh mô hình nếu đầu ra cần phải có định dạng hoặc phong cách cụ thể. Điều này đảm bảo rằng mô hình đáp ứng được các yêu cầu cụ thể của ứng dụng.
5. Tối ưu hóa Retrieval:
Nâng cao hệ thống truy xuất để cải thiện hiệu suất. Điều này có thể bao gồm việc sử dụng các thuật toán xếp hạng tiên tiến hoặc kết hợp các nguồn dữ liệu khác nhau để đảm bảo thông tin truy xuất chính xác và đầy đủ nhất.
Kết luận
Tùy chỉnh mô hình ngôn ngữ lớn (LLM) đòi hỏi sự kết hợp của nhiều kỹ thuật và phương pháp. Bằng cách hiểu rõ các ưu điểm và nhược điểm của mỗi phương pháp, chúng ta có thể xây dựng các hệ thống mạnh mẽ và hiệu quả hơn. Từ việc sử dụng các prompt đơn giản đến tinh chỉnh mô hình và triển khai các hệ thống truy xuất phức tạp, mỗi bước đều đóng một vai trò quan trọng trong việc tối ưu hóa hiệu suất của mô hình. Bằng cách này, chúng ta không chỉ tận dụng được sức mạnh của các mô hình ngôn ngữ lớn mà còn đảm bảo rằng chúng được tùy chỉnh phù hợp với các nhu cầu cụ thể của doanh nghiệp và người dùng.