APACHE BEAM LÀ GÌ?
Định nghĩa
- Là open-source
- Là một mô hình lập trình thống nhất để xác định và thực thi các luồng xử lý dữ liệu (data processing pipelines). Nghĩa là khi mình viết logic xử lý cho Batch processing, thì logic này có thể sử dụng cho Streaming , mình không cần phải học quá nhiều về chia SKD riêng lẻ cho batch và streaming data processing
Lịch sử phát triển
- Google's MapReduce (2004):
- Google giới thiệu MapReduce như một mô hình lập trình và một hệ thống thực thi để xử lý và tạo ra các tập dữ liệu lớn. Đây là một trong những nền tảng đầu tiên để xử lý dữ liệu hàng loạt phân tán.
- Google giới thiệu MapReduce như một mô hình lập trình và một hệ thống thực thi để xử lý và tạo ra các tập dữ liệu lớn. Đây là một trong những nền tảng đầu tiên để xử lý dữ liệu hàng loạt phân tán.
- FlumeJava (2010):
- Google phát triển FlumeJava, một thư viện Java cung cấp một API dễ sử dụng để phát triển các pipeline xử lý dữ liệu hàng loạt. FlumeJava đơn giản hóa việc tạo các pipeline bằng cách sử dụng các toán tử bậc cao (high-level operators) thay vì các hàm Map và Reduce truyền thống.
- Google phát triển FlumeJava, một thư viện Java cung cấp một API dễ sử dụng để phát triển các pipeline xử lý dữ liệu hàng loạt. FlumeJava đơn giản hóa việc tạo các pipeline bằng cách sử dụng các toán tử bậc cao (high-level operators) thay vì các hàm Map và Reduce truyền thống.
- MillWheel (2013):
- Google phát triển MillWheel, một hệ thống xử lý dữ liệu thời gian thực phân tán. MillWheel cung cấp khả năng xử lý các luồng dữ liệu với độ trễ thấp và độ tin cậy cao.
- Google phát triển MillWheel, một hệ thống xử lý dữ liệu thời gian thực phân tán. MillWheel cung cấp khả năng xử lý các luồng dữ liệu với độ trễ thấp và độ tin cậy cao.
- Google Cloud Dataflow (2014):
- Google hợp nhất các ý tưởng và công nghệ từ FlumeJava và MillWheel để tạo ra Google Cloud Dataflow. Đây là một dịch vụ quản lý hoàn toàn cho việc xử lý dữ liệu hàng loạt và dữ liệu thời gian thực trên Google Cloud Platform. Google Cloud Dataflow cung cấp một API thống nhất cho cả xử lý dữ liệu hàng loạt và thời gian thực.
- Google hợp nhất các ý tưởng và công nghệ từ FlumeJava và MillWheel để tạo ra Google Cloud Dataflow. Đây là một dịch vụ quản lý hoàn toàn cho việc xử lý dữ liệu hàng loạt và dữ liệu thời gian thực trên Google Cloud Platform. Google Cloud Dataflow cung cấp một API thống nhất cho cả xử lý dữ liệu hàng loạt và thời gian thực.
- Apache Beam (2016):
- Để mở rộng sự tiếp cận và đóng góp của cộng đồng mã nguồn mở, Google đóng góp SDK của Google Cloud Dataflow cho Apache Software Foundation, và từ đó Apache Beam ra đời. Apache Beam trở thành một dự án top-level của Apache vào năm 2017.
- Để mở rộng sự tiếp cận và đóng góp của cộng đồng mã nguồn mở, Google đóng góp SDK của Google Cloud Dataflow cho Apache Software Foundation, và từ đó Apache Beam ra đời. Apache Beam trở thành một dự án top-level của Apache vào năm 2017.
- Phát triển và tích hợp với các Runner khác:
- Apache Beam đã phát triển và hỗ trợ nhiều Runner khác nhau, cho phép thực thi pipelines trên nhiều nền tảng như Apache Flink, Apache Spark, Apache Samza, và Google Cloud Dataflow. Điều này làm cho Apache Beam trở thành một công cụ linh hoạt và mạnh mẽ cho xử lý dữ liệu phân tán.
- Apache Beam đã phát triển và hỗ trợ nhiều Runner khác nhau, cho phép thực thi pipelines trên nhiều nền tảng như Apache Flink, Apache Spark, Apache Samza, và Google Cloud Dataflow. Điều này làm cho Apache Beam trở thành một công cụ linh hoạt và mạnh mẽ cho xử lý dữ liệu phân tán.
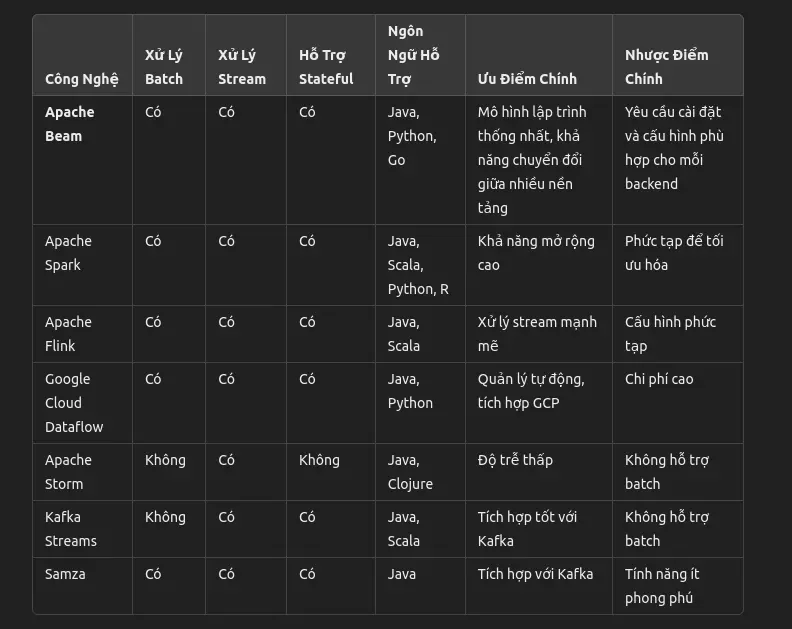
So sánh Apache Beam và một số công nghệ