
Dữ liệu dạng cây (tree data structure) là dạng dữ liệu rất thường thấy ở các ứng dụng. Những chỗ bạn từng bắt gặp có dùng cấu trúc dạng cây có thể là:
- Cấu trúc sơ đồ các phòng ban, bộ phận của một doanh nghiệp
- Danh sách các chuyên mục của một trang báo mạng hay các diễn đàn
- Bình luận theo dạng thread-based mà có thể trả lời nhau vô hạn (tương tự Quora hay Reddit)
Điểm chung của cấu trúc dạng cây là mỗi node trên cây thường có một node cha và có thể có từ 0 đến rất nhiều các node con, và các node con kể trên cũng có thể có nhiều các node con khác. Các node ban đầu (root node) thì có thể không có node cha. Số các node con và độ sâu của cây có thể lên đến vô hạn.
Bạn sẽ lựa chọn lưu dạng dữ liệu này vào cơ sở dữ liệu quan hệ như thế nào? Trong bài viết này, mình xin được điểm qua một số cách để lưu cấu trúc dạng cây như trên vào cơ sở dữ liệu, và đi xem xét về các ưu điểm, yếu điểm của chúng.
Cách 1: Adjacency List
Giả sử bạn cần thực hiện tính năng bình luận theo dạng thread-based mà người dùng có thể trả lời lẫn nhau vô hạn. Lấy ví dụ về một nhóm các bình luận như sau:
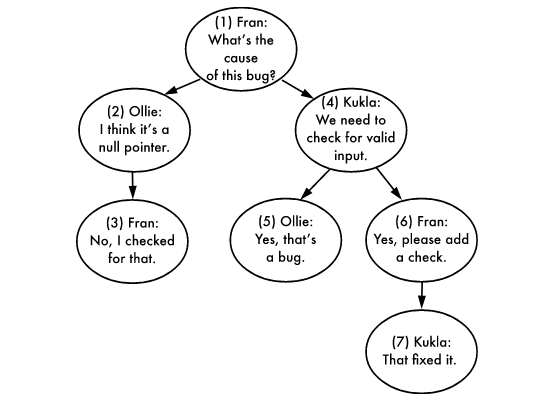
Ta có thể dễ thấy là dữ liệu này là các bình luận theo dạng thread-based, tức mỗi bình luận có thể được nhiều người trả lời bằng bình luận khác, tạo ra rất nhiều các phân lớp khác nhau. Mỗi bình luận (ngoại trừ bình luận gốc) sẽ có duy nhất một bình luận cha.
Hãy thú nhận thật với mình, có phải lần đầu thiết kế CSDL để lưu dữ liệu kiểu này, bạn có tạo bảng có thêm trường parent_id để tham chiếu đến chính bảng hiện tại như dưới đây không?
CREATE TABLE Comments ( comment_id SERIAL PRIMARY KEY, parent_id BIGINT UNSIGNED, bug_id BIGINT UNSIGNED NOT NULL, author BIGINT UNSIGNED NOT NULL, comment_date DATETIME NOT NULL, comment TEXT NOT NULL, FOREIGN KEY (parent_id) REFERENCES Comments(comment_id), FOREIGN KEY (bug_id) REFERENCES Bugs(bug_id), FOREIGN KEY (author) REFERENCES Accounts(account_id)
);
Nếu vậy, cách lưu dữ liệu bạn đang dùng chính là Adjacency List (tạm dịch là Danh Sách Kề), và có lẽ là giải pháp naive nhất mà hầu hết mọi người sẽ nghĩ đến sử dụng đầu tiên cho kiểu dữ liệu này. Theo cách Adjacency List, với mỗi bản ghi của một bình luận, người ta đơn giản sẽ lưu thêm một trường parent_id để trỏ đến bình luận cha của bình luận hiện tại. Nếu bình luận đã là bình luận gốc (không có cha) thì parent_id sẽ được đặt là null:
| comment | author | parent_id | comment_id |
|---|---|---|---|
| What’s the cause of this bug? | Fran | NULL | 1 |
| I think it’s a null pointer. | Ollie | 1 | 2 |
| No, I checked for that. | Fran | 2 | 3 |
| We need to check for invalid input. | Kukla | 1 | 4 |
| Yes, that’s a bug. | Ollie | 4 | 5 |
| Yes, please add a check. | Fran | 4 | 6 |
| That fixed it. | Kukla | 6 | 7 |
Với kiểu Adjacency List, việc query node cha trực tiếp hoặc các node con trực tiếp (tức các node cha và con ngay liền kề nó) khá đơn giản. Ví dụ, để lấy được một bình luận kèm theo các bình luận trả lời trực tiếp nó như với ví dụ phía trên thì:
SELECT c1.*, c2.*
FROM Comments c1 LEFT OUTER JOIN Comments c2
ON c2.parent_id = c1.comment_id;
Tuy nhiên, vấn đề mà bạn sẽ sớm nhận ra đó là không dễ để trong một query có thể lấy được hết mọi con cháu (hay các hậu duệ/descendant) của một node, hay lấy được hết mọi cha ông (hay các tổ tiên/ancestor) của một node. Tương tự, việc đếm COUNT() tổng số các node của một nhánh thread cũng không hề đơn giản.
Để có thể query được tình huống trên với Adjacency List, ta có thể sử dụng vài giải pháp như lấy mọi comment xuống để lưu vào bộ nhớ và xử lý ở tầng ứng dụng (rất tốn kém), hoặc sử dụng recursive với common table expression (không phải mọi CSDL đều hỗ trợ).
Cách 2: Path Enumeration
Path Enumeration giải quyết vấn đề bằng việc lưu thêm một trường gọi là path cho từng bình luận thay cho parent_id. path chính là dãy các id ancestor theo thứ tự của một bình luận, tương tự đường dẫn đến một thư mục trong Windows như bạn hay thấy:
CREATE TABLE Comments ( comment_id SERIAL PRIMARY KEY, path VARCHAR(1000), bug_id BIGINT UNSIGNED NOT NULL, author BIGINT UNSIGNED NOT NULL, comment_date DATETIME NOT NULL, comment TEXT NOT NULL, FOREIGN KEY (bug_id) REFERENCES Bugs(bug_id), FOREIGN KEY (author) REFERENCES Accounts(account_id)
);
| comment | author | path | comment_id |
|---|---|---|---|
| What’s the cause of this bug? | Fran | 1/ | 1 |
| I think it’s a null pointer. | Ollie | 1/2/ | 2 |
| No, I checked for that. | Fran | 1/2/3 | 3 |
| We need to check for invalid input. | Kukla | 1/4/ | 4 |
| Yes, that’s a bug. | Ollie | 1/4/5/ | 5 |
| Yes, please add a check. | Fran | 1/4/6/ | 6 |
| That fixed it. | Kukla | 1/4/6/7/ | 7 |
Bằng việc lưu kèm với path của bình luận, bạn đã có thể dễ dàng hơn trong việc query các ancestor hay descendant của một bình luận bất kỳ.
Ví dụ, nếu bạn muốn tìm mọi ancestor của bình luận có path là 1/4/6/7/:
SELECT *
FROM Comments AS c
WHERE '1/4/6/7/' LIKE c.path || '%';
Còn để tìm mọi descendant của bình luận có path là 1/4, bạn chỉ cần đảo ngược mệnh đề LIKE là được:
SELECT *
FROM Comments AS c
WHERE c.path LIKE '1/4/' || '%';
Một nhược điểm của giải pháp Path Enumeration là khó đảm bảo toàn vẹn dữ liệu ở cấp độ database, và bạn cần đảm bảo việc tạo ra các path chính xác ở phía tầng ứng dụng.
Cách 3: Nested Sets
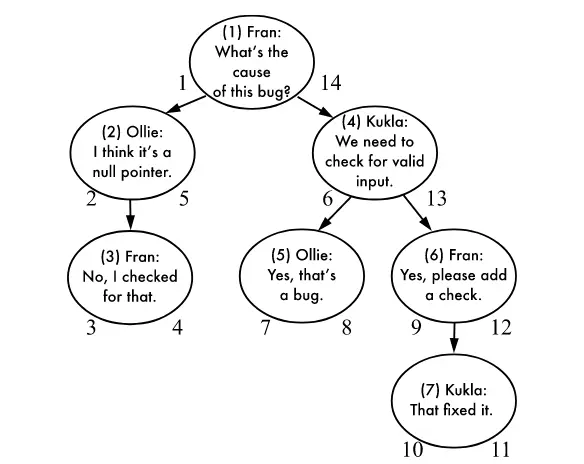
Trong tất cả những cách mà mình có giới thiệu trong bài này, thì Nested Sets có lẽ là cách thú vị và hay ho nhất. Nested Sets liên quan đến việc lưu thêm hai chỉ số kèm theo node là chỉ số trái và chỉ số phải sao cho:
- chỉ số trái của một node luôn nhỏ hơn chỉ số trái của tất cả các node descendant
- chỉ số phải của một node luôn lớn hơn chỉ số phải của tất cả các node descendant
Nghe thì rất nguy hiểm, nhưng bạn chỉ hãy nhìn vào hình minh họa ở đầu mục, bạn sẽ dễ thấy Nested Sets hoạt động thực chất cũng không quá phức tạp.
Để áp dụng vào ví dụ là các bình luận như ở 2 cách phía trên, bảng Comments của mình sẽ được tạo với câu lệnh SQL như sau. nsleft và nsright chính là hai chỉ số trái/phải như mình đã nói ở phía trên:
CREATE TABLE Comments ( comment_id SERIAL PRIMARY KEY, nsleft INTEGER NOT NULL, nsright INTEGER NOT NULL, bug_id BIGINT UNSIGNED NOT NULL, author BIGINT UNSIGNED NOT NULL, comment_date DATETIME NOT NULL, comment TEXT NOT NULL, FOREIGN KEY (bug_id) REFERENCES Bugs (bug_id), FOREIGN KEY (author) REFERENCES Accounts(account_id)
);
| comment | author | nsleft | nsright | comment_id |
|---|---|---|---|---|
| What’s the cause of this bug? | Fran | 1 | 14 | 1 |
| I think it’s a null pointer. | Ollie | 2 | 5 | 2 |
| No, I checked for that. | Fran | 3 | 4 | 3 |
| We need to check for invalid input. | Kukla | 6 | 13 | 4 |
| Yes, that’s a bug. | Ollie | 7 | 8 | 5 |
| Yes, please add a check. | Fran | 9 | 12 | 6 |
| That fixed it. | Kukla | 10 | 11 | 7 |
Tương tự với cách Path Enumeration, thì với Nested Sets, bạn cũng dễ dàng tìm mọi ancestor và descendant của một node bất kỳ, nhờ sự tiện lợi của hai chỉ số nsleft và nsright:
SELECT c2.*
FROM Comments AS c1
JOIN Comment AS c2
ON c1.nsleft BETWEEN c2.nsleft AND c2.nsright
WHERE c1.comment_id = 6;
SELECT c2.*
FROM Comments AS c1
JOIN Comments as c2
ON c2.nsleft BETWEEN c1.nsleft AND c1.nsright
WHERE c1.comment_id = 4;
Tuy nhiên, Nested Sets lại gây khó khăn nếu bạn muốn truy xuất node cha hay con trực tiếp (liền kề) của một node bất kỳ. Bạn có thể lưu kèm theo parent_id như với cách Adjacency List để khắc phục vấn đề này.
Ngoài ra, việc thêm mới (INSERT) phần tử mới vào cây lại khá tốn kém, do bạn cần hiệu chỉnh lại chỉ số nsleft và nsright của các node nếu hai chỉ số đó lớn hơn nsleft của node được thêm vào. Tức nghĩa là khi bạn chèn thêm node mới vào giữa cây, thì các node ngang hàng phía bên phải, các node ancestor của nó, và các node ngang hàng phía bên phải của các ancestor đó cũng đều phải sửa theo. Vì lý do trên, Nested Sets chỉ thích hợp nếu như dữ liệu dạng cây của bạn có được truy xuất thường xuyên nhưng ít bị thêm vào hay thay đổi.
Cách 4: Closure Table
Closure Table là cách sử dụng thêm một bảng phụ làm bảng tham chiếu mối quan hệ ancestor-descendant giữa các node ở trong cây. Điểm mấu chốt là Closure Table sẽ lưu lại mọi mối quan hệ ancestor-descendant có thể (tức cha-cha, cha-con, cha-cháu, cha-chắt,...), chứ không phải chỉ lưu mỗi mối quan hệ cha con trực tiếp (liền kề nhau).
Bên cạnh bảng Comments, với cách này mình cần tạo thêm một bảng phụ là TreePath với các trường là ancestor và descendant và lưu lại ở đó các cặp quan hệ:
CREATE TABLE Comments ( comment_id SERIAL PRIMARY KEY, bug_id BIGINT UNSIGNED NOT NULL, author BIGINT UNSIGNED NOT NULL, comment_date DATETIME NOT NULL, comment TEXT NOT NULL, FOREIGN KEY (bug_id) REFERENCES Bugs(bug_id), FOREIGN KEY (author) REFERENCES Accounts(account_id)
); CREATE TABLE TreePaths ( ancestor BIGINT UNSIGNED NOT NULL, descendant BIGINT UNSIGNED NOT NULL, PRIMARY KEY(ancestor, descendant), FOREIGN KEY (ancestor) REFERENCES Comments(comment_id), FOREIGN KEY (descendant) REFERENCES Comments(comment_id)
);
Tương ứng với mỗi node, thì ở bảng TreePaths sẽ có một bản ghi chỉ mối quan hệ lên chính node hiện tại, và nhiều bản ghi chỉ mối quan hệ đến mọi descendant của node hiện tại đó:
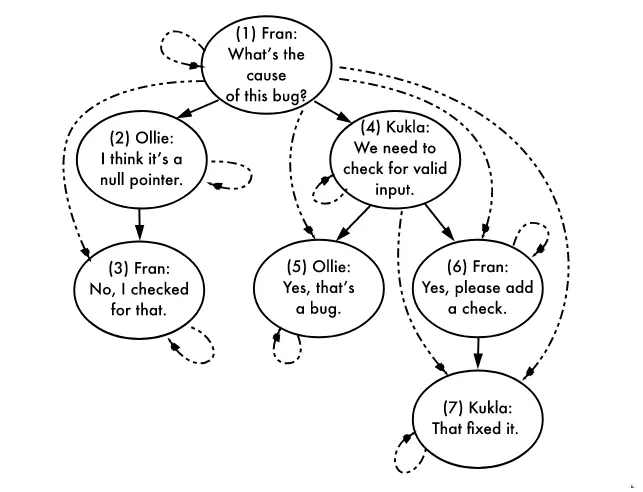
| ancestor | descendant |
|---|---|
| 1 | 1 |
| 1 | 2 |
| 1 | 3 |
| 1 | 4 |
| 1 | 5 |
| 1 | 6 |
| 1 | 7 |
| 2 | 2 |
| 2 | 3 |
| 3 | 3 |
| 4 | 4 |
| 4 | 5 |
| 4 | 6 |
| 4 | 7 |
| 5 | 5 |
| 5 | 6 |
| 6 | 7 |
| 7 | 7 |
Nhờ có một bảng phụ lưu rõ mọi mối quan hệ ancestor-descendant, việc truy xuất các ancestor hay descendant của một node rất đơn giản, có lẽ là đơn giản nhất trong mọi cách mình kể trên. Ví dụ, để tìm các ancestor của comment có comment_id là 6 thì bạn cần query như sau:
SELECT c.*
FROM Comments AS c
JOIN TreePaths AS t ON c.comment_id = t.ancestor
WHERE t.descendant = 6;
Và để tìm các descendant của comment có comment_id là 4:
SELECT c.*
FROM Comments AS c
JOIN TreePaths AS t ON c.comment_id = t.descendant
WHERE t.ancestor = 4;
Khác với Nested Sets, việc thêm và xóa row khi sử dụng cùng bảng Closure Table cũng đơn giản hơn nhiều. Chỉ có một điều bạn phải lưu ý là khi dữ liệu cây của bạn nhiều và sâu hơn thì số lượng bản ghi ở bảng TreePaths cũng tăng lên rất nhanh, đánh đổi lại cho việc dễ dàng hơn trong truy xuất dữ liệu.
Tổng kết
Dưới đây là tổng hợp và so sánh về các giải pháp ở trong bài, trong đó Recursive Query là cách lưu dữ liệu dạng Adjacency List nhưng sử dụng CTE để truy vấn đệ quy, nếu như CSDL của bạn có hỗ trợ.
| Design | Query Child | Query Tree | Insert | Delete | Ref. Integ. |
|---|---|---|---|---|---|
| Adjacency List | Easy | Hard | Easy | Easy | Yes |
| Recursive Query | Easy | Easy | Easy | Easy | Yes |
| Path Enumeration | Easy | Easy | Easy | Easy | No |
| Nested Sets | Hard | Hard | Hard | Hard | No |
| Closure Table | Easy | Easy | Easy | Easy | Yes |
Sau cùng, quyết định cuối cùng là ở bạn, hãy chọn giải pháp lưu dữ liệu sao cho phù hợp với mục đích sử dụng nhất.
Tìm hiểu thêm ở đâu?
Những kiến thức cũng như các hình ảnh trong bài viết này của mình chỉ là một phần nhỏ trong số rất nhiều kiến thức hay về SQL từ cuốn sách SQL Antipatterns: Avoiding the Pitfalls of Database Programming (GoodReads) mà mình đang đọc.
Nếu bạn chưa có thời gian đọc sách ngay bây giờ, thì có thể xem qua slide ngắn gọn Sql Antipatterns Strike Back của cùng tác giả của cuốn sách, vốn tổng hợp khá nhiều kiến thức một cách ngắn gọn và chỉ mất khoảng 15 phút để xem.