I. Đặt vấn đề
Một vấn đề rất quan trọng trong Lý thuyết đồ thị là bài toán duyệt tất cả các đỉnh có thể đến được từ một đỉnh xuất phát nào đó, không duyệt lặp lại cũng như không bỏ sót đỉnh nào cả. Vì vậy, ta phải xây dựng được những phép duyệt các đỉnh của đồ thị theo một hệ thống nhất định, những phép duyệt đó gọi là các thuật toán tìm kiếm trên đồ thị.
Có hai giải thuật tìm kiếm trên đồ thị cơ bản: Tìm kiếm theo chiều sâu (Depth First Search - DFS) và Tìm kiếm theo chiều rộng (Breadth First Search - BFS). Hai giải thuật này có độ phức tạp thuật toán như nhau, nhưng sẽ có những ứng dụng khác nhau và cách cài đặt cũng khác nhau.
Xét bài toán sau: Cho đơn đồ thị vô hướng gồm đỉnh, cạnh, danh sách các cạnh được nhập vào theo dạng với và là các đỉnh thuộc đồ thị . Hãy đưa ra một đường đi từ đỉnh tới đỉnh cho trước.
Dưới đây ta sẽ cài đặt hai giải thuật và để giải quyết bài toán này. Các cài đặt đều sử dụng danh sách kề, nếu như đề bài thay đổi thành đa đồ thị hay đồ thị có hướng thì chỉ cần sửa đổi một chút trong quá trình nhập dữ liệu.
II. Giải thuật tìm kiếm theo chiều sâu (Depth First Search)
Tư tưởng thuật toán:
- Nhận thấy rằng, mọi đỉnh kề với đều có thể đến được từ . Với mỗi đỉnh kề với , thì tất nhiên các đỉnh kề với cũng sẽ đến được từ ,...Từ đây, ta có thể xây dựng một hàm tìm kiếm để duyệt các đỉnh kề với đỉnh , hàm này sẽ gọi tiếp tới hàm với là đỉnh kề với ,...Quá trình tìm kiếm sẽ bắt đầu với lời gọi .
- Để không đỉnh nào bị thăm lại, khi duyệt tới một đỉnh nào đó, ta sẽ đánh dấu lại nó đã được thăm rồi, bằng cách sử dụng một mảng là đỉnh liền trước trong quá trình gọi đệ quy (hay còn gọi là đỉnh cha của đỉnh ). Khi đó, điều kiện để một đỉnh chưa thăm sẽ là , và khi duyệt tới một đỉnh kề với đỉnh , ta sẽ gán , vừa để thể hiện đỉnh liền trước trên đường đi từ tới , vừa để đánh dấu đỉnh đã thăm rồi.
- Kết thúc giải thuật, đường đi từ tới sẽ là:
Cài đặt:
void dfs(int u) // Tìm kiếm theo chiều sâu từ u.
{ for (int v: adj[u]) { if (v == par[u]) // Kiểm tra v không được trùng với cha của u. continue; par[v] = u; // Đặt cha của v là u. dfs(v); // Tiếp tục tiến vào con của u. }
} void trace(int s, int f)
{ vector < int > path; // Lưu đường đi từ s tới f. while (f != 0) { path.push_back(f); f = trace[f]; } for (int i = path.size() - 1; i >= 0; --i) // In ngược lại để thu được thứ tự từ s -> f. cout << path[i] << "->";
} int main()
{ // Nhập dữ liệu đồ thị. cin >> n >> m >> s >> f; for (int i = 1; i <= m; ++i) { int u, v; cin >> u >> v; adj[u].push_back(v); adj[v].push_back(u); } dfs(s); // Tìm kiếm theo chiều sâu bắt đầu từ s. if (trace[f] == 0) // Đỉnh f chưa được thăm thì thông báo không tìm được đường đi. cout << "Can't find a path from s to f"; else trace(s, f); // Truy vết đường đi từ s tới f.
}
Giả sử với Input là: và danh sách các cạnh là , giải thuật sẽ cho ra kết quả là:
1 -> 2 -> 3 -> 5
Hình vẽ dưới đây cho ta minh họa về quá trình duyệt :
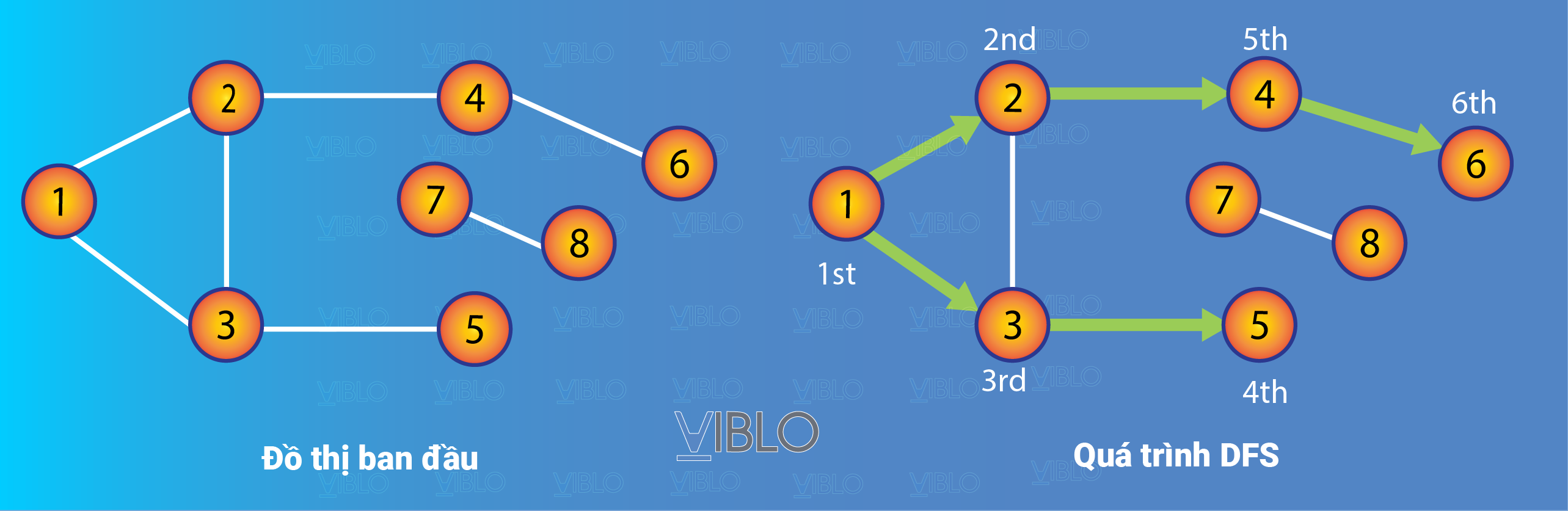
Nhận xét:
- Nhờ vào kĩ thuật đánh dấu đường đi, nên hàm chỉ được gọi không quá lần.
- Có thể tồn tại nhiều đường đi từ tới nhưng giải thuật luôn luôn trả về đường đi có thứ tự từ điển nhỏ nhất.
- Quá trình sẽ cho ta một cây gốc . Khi đó, tồn tại một quan hệ cha - con trên cây được định nghĩa là: Nếu từ đỉnh tới thăm đỉnh gọi thì là cha của .
III. Giải thuật tìm kiếm theo chiều rộng (Breadth First Search)
Tư tưởng thuật toán:
- Dựa trên tư tưởng lập ra một thứ tự duyệt các đỉnh, sao cho các đỉnh gần hơn sẽ luôn luôn được duyệt xong trước các đỉnh xa hơn. Ví dụ, từ đỉnh ta thăm các đỉnh kề với nó là . Khi thăm tới , sẽ phát sinh việc thăm các đỉnh kề với là . Dĩ nhiên các đỉnh này đều xa hơn so với , cho nên chúng sẽ chỉ được thăm sau khi toàn bộ các đỉnh đã được thăm hết.
- Quá trình thăm theo cách này sẽ tạo ra một cây rộng và hẹp, do đó gọi là tìm kiếm theo chiều rộng.
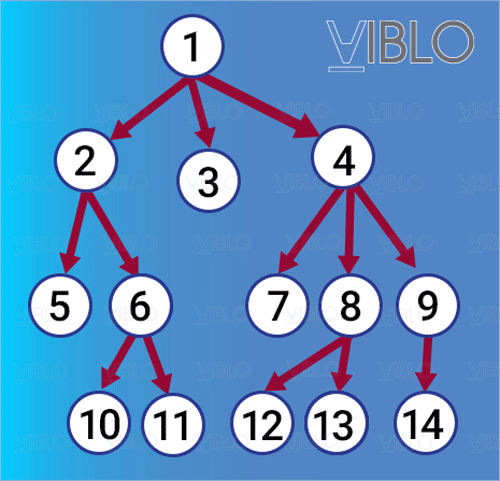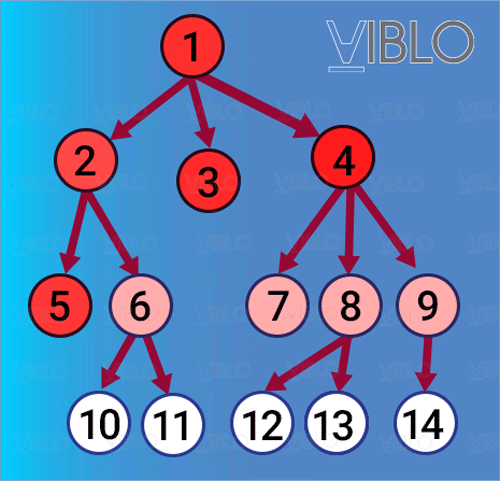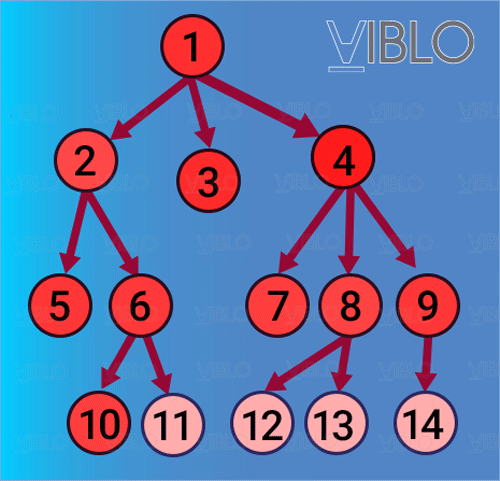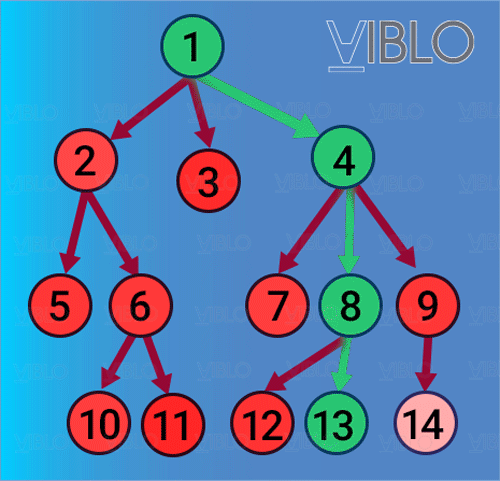
Thứ tự thăm các đỉnh bằng BFS
- Để xây dựng một thứ tự như vậy, ta sẽ tạo ra một danh sách gồm các đỉnh đang được "chờ" thăm. Tại mỗi bước, thăm đỉnh ở đầu danh sách và thêm toàn bộ các đỉnh kề với đỉnh đó (mà chưa được thăm) vào cuối danh sách, như vậy danh sách sẽ được xây dựng thành các lớp liền nhau, mỗi lớp bao gồm các đỉnh cùng kề với một đỉnh nào đó. Cấu trúc dữ liệu phù hợp nhất để xây dựng danh sách này là hàng đợi (queue).
- Việc truy vết cũng diễn ra tương tự như giải thuật , ta dùng một mảng để lưu lại đỉnh liền trước với đỉnh trong quá trình duyệt, và kiêm luôn chức năng đánh dấu đỉnh đã được thăm hay chưa.
Cài đặt:
void trace(int s, int f)
{ vector < int > path; // Lưu đường đi từ s tới f. while (f != 0) { path.push_back(f); f = trace[f]; } for (int i = path.size() - 1; i >= 0; --i) // In ngược lại để thu được thứ tự từ s -> f. cout << path[i] << "->";
} void bfs(int s, int f)
{ queue < int > vertexes; vertexes.push(s); while (!vertexes.empty()) { int u = vertexes.front(); vertexes.pop(); Thăm xong đỉnh ở đầu queue, pop nó ra. if (u == f) // Nếu đã tới được f thì truy vết và dừng luôn BFS. { trace(s, f); return; } for (int v: adj[u]) // Duyệt các đỉnh kề với u. if (trace[v] == 0) // Nếu đỉnh đó chưa thăm. { trace[v] = u; // Lưu vết đường đi tới v. vertexes.push(v); // Đẩy vào queue. } } cout << "Can't find a path from s to f";
}
Nhận xét:
- Có thể có nhiều cách di chuyển từ tới , nhưng giải thuật luôn luôn trả về đường đi ngắn nhất (đi qua ít cạnh nhất). Ví dụ trên hình dưới đây thì đường đi từ tới sẽ là .
- Quá trình cho ta một cây gốc , với quan hệ cha con được định nghĩa: Nếu từ đỉnh tới thăm đỉnh thì là cha của .
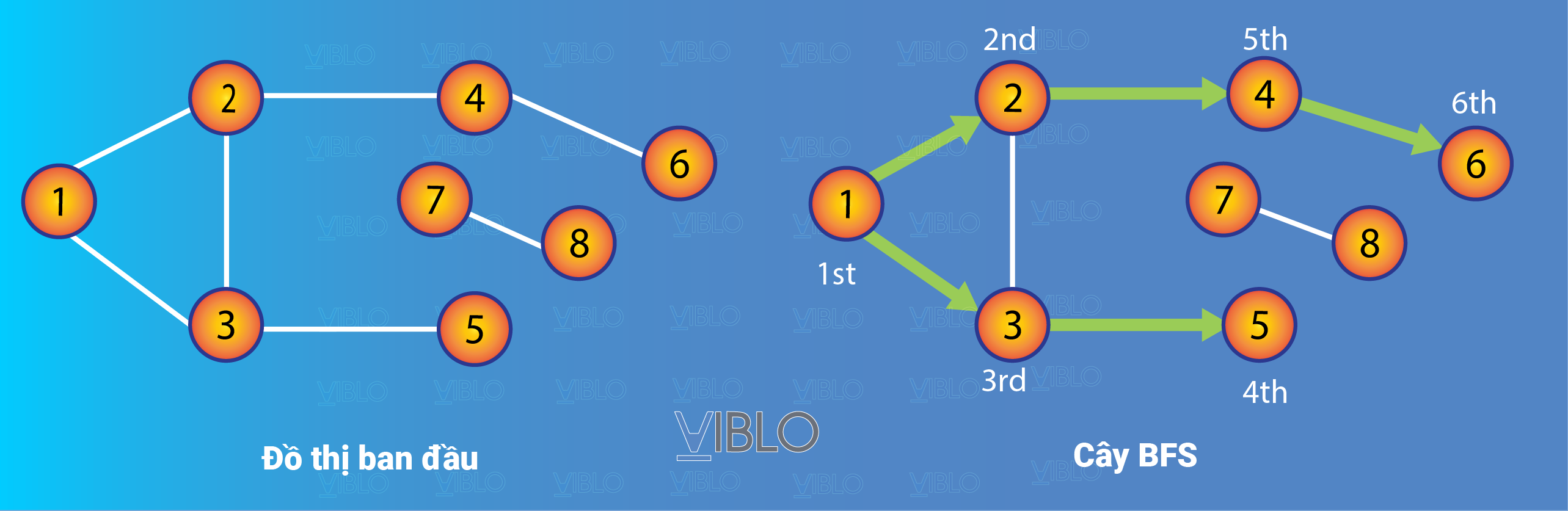
Ví dụ: Giải cứu công chúa:
IV. Một số bài toán điển hình của hai giải thuật DFS và BFS
1. Đếm thành phần liên thông
Đề bài: Cho đơn đồ thị vô hướng gồm đỉnh, cạnh .
Yêu cầu: Hãy xác định xem đồ thị có bao nhiêu thành phần liên thông?
Input:
- Dòng đầu tiên chứa hai số nguyên dương .
- dòng tiếp theo, mỗi dòng chứa hai số nguyên dương mô tả một cạnh của đồ thị.
Output:
- Số nguyên duy nhất là số thành phần liên thông của đồ thị.
Ví dụ:

Ý tưởng:
- Đầu tiên xây dựng một danh sách kề để biểu diễn đồ thị. Sử dụng một mảng các
vector,vectorsẽ lưu các đỉnh kề với đỉnh . - Nhận xét rằng, nếu một tập các đỉnh thuộc cùng một thành phần liên thông thì chắc chắn chúng sẽ đi tới được nhau trong quá trình từ bất kỳ đỉnh nào trong số đó. Vậy ý tưởng là duyệt qua tất cả các đỉnh, đỉnh nào chưa được thăm (chưa thuộc một thành phần liên thông nào đó) thì sẽ tiến hành từ đỉnh đó, tìm tất cả các đỉnh tới được từ nó và đánh dấu các đỉnh này đã đi qua. Mỗi lượt xây dựng xong một cây sẽ xác định một thành phần liên thông. Dưới đây sử dụng một mảng để đánh dấu đỉnh đã được thăm hay chưa.
Cài đặt:
#include <bits/stdc++.h> using namespace std; int n, m;
bool visited[100001];
vector < int > adj[100001]; void dfs(int u)
{ visited[u] = true; for (int v: par[u]) if (!visited[v]) dfs(v);
} int count_ccp()
{ int ccp_amount = 0; // Số thành phần liên thông. // Duyệt từng đỉnh, đỉnh nào chưa thăm thì thăm DFS từ đỉnh đó. for (int u = 1; u <= n; ++u) if (!visited[u]) { dfs(u); ++ccp_amount; } return ccp_amount;
} int main()
{ cin >> n >> m; // Xây dựng danh sách kề của đồ thị. for (int i = 1; i <= m; ++i) { int u, v; cin >> u >> v; // Do đồ thị là vô hướng nên u thuộc danh sách kề của v và ngược lại. adj[u].push_back(v); adj[v].push_back(u); } cout << count_cpp();
}
2. Tìm đường đi ngắn nhất
Đề bài: Một mê cung được biểu diễn dưới dạng ma trận gồm hàng, cột, các hàng được đánh số từ từ trên xuống, các cột được đánh số từ từ trái sang, ô nằm trên giao của hàng cột có chứa số nguyên thể hiện một căn phòng của mê cung. Nếu thì phòng đó bị khóa, ngược lại thì phòng đó có thể đi qua.
Bạn bị nhốt trong căn phòng ở vị trí của mê cung, mỗi lần bạn chỉ có thể thử đi vào một trong bốn căn phòng bên trái, bên phải, bên trên và bên dưới. Nếu căn phòng đó bị khóa, bạn không thể đi vào được. Nếu như theo một cách nào đó mà bạn tới được một căn phòng không bị khóa nằm trên biên của mê cung, thì khi đó bạn sẽ thoát khỏi mê cung.
Yêu cầu: Tìm số bước đi ngắn nhất để thoát khỏi mê cung (chỉ cần đếm số bước đi để tới được một phòng không khóa bất kỳ trên biên của mê cung)?
Input:
- Dòng đầu tiên chứa hai số nguyên dương - kích thước mê cung.
- Dòng thứ hai chứa hai số nguyên
- dòng tiếp theo, mỗi dòng chứa số nguyên có giá trị hoặc biểu diễn mê cung.
Output:
- Số nguyên duy nhất là số bước đi ngắn nhất để bạn thoát khỏi mê cung.
Ví dụ:

Ý tưởng:
- Bài toán này thuộc dạng Loang trên ma trận - một dạng toán kinh điển áp dụng giải thuật . Ma trận có thể coi như một đồ thị, mỗi ô ứng với một đỉnh của đồ thị, mỗi đỉnh sẽ có cạnh nối tới ô kề cạnh với nó. Nhiệm vụ của chúng ta là dùng giải thuật để tìm đường đi từ ô tới một ô bất kỳ nằm trên biên, sao cho đường đi đó đi qua ít ô nhất trong ma trận.
- Hình dung bạn đang đứng tại ô thì các ô bạn có thể tới được là: . Tuy nhiên, những ô này phải thỏa mãn ba điều kiện sau thì mới được đưa vào hành trình: một là ô đó nằm trong ma trận, hai là ô đó mang số (căn phòng không bị khóa), ba là ô đó chưa bị thăm trong cây . Để tiện xử lý, ta xây dựng hai thứ:
- Mảng biểu thị cho các bước đi có thể từ một ô .
- Mảng : Xác định ô đã bị thăm hay chưa.
- Hàm : Xác định một ô có phù hợp để đưa vào hàng đợi chờ duyệt hay không.
- Việc cuối cùng là xây dựng giải thuật để bắt đầu "loang" từ ô xuất phát ra xung quanh, nếu như tới một bước nào đó, ta gặp được ô nằm trên biên của ma trận ở đầu hàng đợi thì dừng luôn quá trình duyệt vì đã tới đích. Để kiểm soát số bước đi ngắn nhất, gọi mảng là số bước ngắn nhất để đi từ ô xuất phát tới ô .
Cài đặt:
#include <bits/stdc++.h>
#define inf 1e9 + 7 using namespace std;
const int maxn = 101;
const int step[4][2] = {{-1, 0}, {0, 1}, {1, 0}, {0, -1}};
int m, n, a[maxn][maxn], visited[maxn][maxn], cnt_step[maxn][maxn];
pair < int, int > start; void enter()
{ ios_base::sync_with_stdio(false); cin.tie(0); cout.tie(0); // Nhập ma trận và điểm xuất phát start. cin >> m >> n; cin >> start.first >> start.second; for (int i = 1; i <= m; ++i) for (int j = 1; j <= n; ++j) cin >> a[i][j];
} // Kiểm tra một ô có hợp lệ để đưa vào hàng đợi hay không.
// Sử dụng luôn kiểu pair để tiện thao tác.
bool is_valid(pair < int, int > next_pos)
{ return (next_pos.first > 0 && next_pos.first <= m && next_pos.second > 0 && next_pos.second <= n && mark[next_pos.first][next_pos.first] == 0 && a[next_pos.first][next_pos.first] == 0);
} void find_road(pair < int, int > start)
{ queue < pair < int, int > > pos; pos.push(start); visited[start.first][start.second] = 1; cnt_step[start.first][start.second] = 0; while (!pos.empty()) { pair < int, int > cur_pos = pos.front(); pos.pop(); // Nếu đã tới được một ô trên biên của ma trận thì dừng BFS. if (cur_pos.first == m || cur_pos.first == 1 || cur_pos.second == n || cur_pos.second == 1) { cout << cntStep[curPos.x][curPos.y]; return; } // Duyệt các ô kề với ô hiện tại bằng mảng step. for (int i = 0; i < 4; ++i) { pair < int, int > next_pos = {cur_pos.first + step[i][0], cur_pos.second + step[i][1]}; // Nếu ô kề này hợp lệ thì đưa nó vào hàng đợi và cập nhật số bước đi tới nó. if (check(next_pos)) { pos.push(next_pos); visited[next_pos.x][next_pos.y] = 1; // Đánh dấu đã thăm. // Số bước đi tới ô này tăng thêm một bước so với ô liền trước. int t = cnt_step[cur_pos.first][cur_pos.second] + 1; cnt_step[nextPos.first][next_pos.second] = t; } } } cout << -1;
} int main()
{ enter(); find_road(start); return 0;
}
V. Độ phức tạp tính toán của DFS và BFS
Tùy vào cách cài đặt đồ thị mà ta sẽ thu được các giải thuật với độ phức tạp khác nhau:
- Nếu đồ thị biểu diễn bằng danh sách kề, cả hai giải thuật và đều có độ phức tạp là . Cách cài đặt này là tốt nhất.
- Nếu đồ thị biểu diễn bằng ma trận kề, độ phức tạp tính toán sẽ là .
- Nếu đồ thị biểu diễn bằng danh sách cạnh, thao tác duyệt mọi đỉnh kề với đỉnh sẽ buộc phải duyệt qua toàn bộ danh sách cạnh, dẫn đến độ phức tạp tính toán là . Đây là cách cài đặt tệ nhất.