Các phần nội dung chính sẽ được đề cập trong bài blog lần này
- Object Detection task
- Giới thiệu về Zalo AI Hackathon
- Phân loại các thuật toán về Object Detection
- Faster-RCNN
- RPN (Region Proposal Network)
- Loss Function (RPN)
- RoI Pooling
- Detection model
- Loss Function (Faster-RCNN)
- Metric Evaluation
- Huấn luyện mô hình
- Kết quả đánh giá và thực nghiệm
- Kết luận
- Other
- Reference
"Hoàng Sa và Trường Sa là của Việt Nam" http://dangcongsan.vn/bien-dao-viet-nam/hoang-sa-va-truong-sa-la-cua-viet-nam-553850.html
Disclamer: Bài blog này mình mượn ý tưởng từ 1 bài blog khác trên medium https://towardsdatascience.com/125f62b9141a. Mình viết với mục đích ôn lại và diễn giải phần ý tưởng của thuật toán, cũng như tập trung vào phần xử lý dữ liệu mà mình đề cập bên dưới!

https://thanhnien.vn/van-hoa/phim-co-duong-luoi-bo-lot-vao-rap-chieu-viet-nam-1136643.html
Zalo AI Hackathon
-
Thông tin cuộc thi: https://hackathon.zalo.ai
-
Thời gian cuối năm 2019, team mình có tham gia 1 cuộc thi là Zalo AI Hackathon trong TPHCM với bài toán phát hiện đường lưỡi bò trong ảnh. Nhìn chung, đây là 1 đề bài khá bất ngờ nhưng thú vị. Về hướng áp dụng thì có thể triển khai ứng dụng này lên các trang mạng xã hội như zalo chẳng hạn, ngoài việc phải kiểm duyệt các nội dung ảnh nhạy cảm thì cũng phát hiện và ngăn chặn các bài viết với tư tưởng kích động trên nền tảng đó
 Vì thời gian cũng gấp nên hồi đó team mình lựa chọn sử dụng các public repo với các thuật toán điển hình về Object Detection và tập trung chủ yếu vào việc xử lý dữ liệu.
Vì thời gian cũng gấp nên hồi đó team mình lựa chọn sử dụng các public repo với các thuật toán điển hình về Object Detection và tập trung chủ yếu vào việc xử lý dữ liệu. -
Link dataset: https://drive.google.com/drive/folders/1_2-h5FMtXyuYcVXfDTxDc5XNWajaAA1f
Object Detection task
- Object Detection là 1 bài toán không mới và cũng đã đạt được rất nhiều các thành tựu trong những năm gần đây, cả phần ứng dụng và mô hình thuật toán. Điển hình là các phương pháp Object Detection sử dụng Deep Learning đã đạt được các bước cải thiện vượt trội so với các phương pháp xử lý ảnh thông thường khác
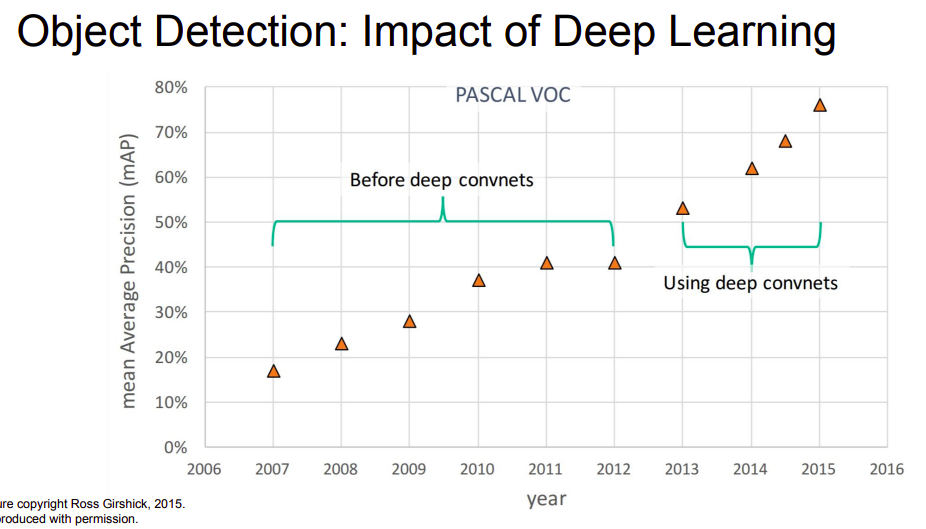
- Các bạn có thể tìm hiểu thêm về các thuật toán Object Detection qua các bài blog trên viblo sau:
- Tìm hiểu về YOLO trong bài toán real-time object detection - Trịnh Việt Hoàng
- Sử dụng Tensorflow API cho bài toán Object Detection - Phạm Thị Hồng Anh
- Faster RCNN for Object Detection with Keras - Nguyễn Văn Đạt
- A discussion of SSD Intuition - Nguyễn Minh Tâm
Phân loại các thuật toán Object Detection
- Về phần tiếp cận mô hình thì có thể phân loại Object Detection thành 1 số dạng chính như sau:
- One-stage vs Two-stage
- Region-proposal method vs Proposal-free method
- Anchor-base vs anchor-free method
One-stage vs two-stage
- Các thuật toán two-stage object detection điển hình như RCNN / Fast-RCNN / Faster-RCNN / Mask-RCNN (object detect + instance segmentation), ... Việc gọi là two-stage là do cách model xử lý để lấy ra được các vùng có khả năng chứa vật thể từ bức ảnh. Ví dụ, với Faster-RCNN thì trong stage-1, ảnh sẽ được đưa ra 1 sub-network gọi là RPN (Region Proposal Network) với nhiệm vụ extract các vùng trên ảnh có khả năng chứa đối tượng dựa vào các anchor (phần này mình sẽ đề cập kĩ hơn bên dưới). Sau khi đã thu được các vùng đặc trưng từ RPN, model Faster-RCNN sẽ thực hiện tiếp việc phân loại đối tượng và xác định vị trí nhờ vào việc chia làm 2 nhánh tại phần cuối của mô hình (Object classification & Bounding box regression)
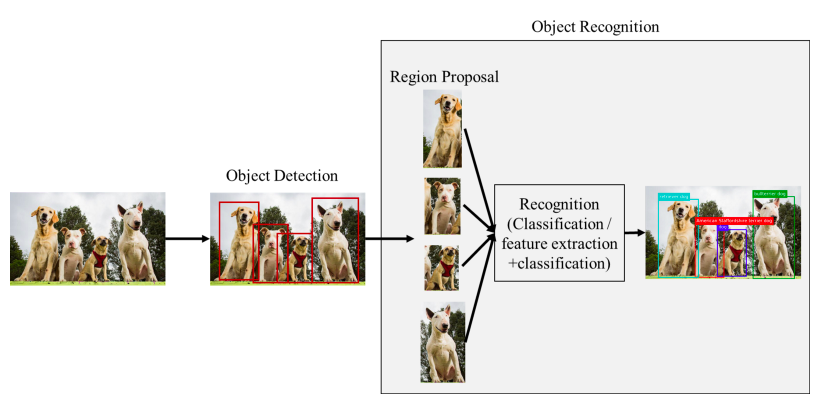
- 1 cách tiếp cận khác là One-stage Object Detection với 1 số model điển hình như: SSD, Yolo v2/3, RetinaNet. Gọi là one-stage vì trong việc thiết kế model hoàn toàn ko có phần trích chọn các vùng đặc trưng (các vùng có khả năng chứa đối tượng) như RPN của Faster-RCNN. Các mô hình one-stage OD coi phần việc phát hiện đối tượng (object localization) như 1 bài toán regression (với 4 tọa độ offset, ví dụ x, y, w, h) và cũng dựa trên các pre-define box gọi là anchor để làm việc đó. Các mô hình dạng này thường nhanh hơn tuy nhiên "độ chính xác" của model thường kém hơn so với two-stage object detection Tất nhiên, 1 số mô hình one-stage vẫn tỏ ra vượt trội hơn 1 chút so với two-stage như Retina-Net với việc việc thiết kế mạng theo FPN (Feature Pyramid Network) và Focal Loss

Region-proposal method vs Proposal-free method
- Đây chỉ là 1 cách phân loại khác
- Region-proposal: đề cập tới các phương pháp cần sử dụng 1 cơ chế để xác định các vùng có khả năng chứa đối tượng trước (region proposal), rồi sau đó tiếp tục thực hiện các bước về object classification và bounding box regression (RCNN / Fast-RCNN / Faster-RCNN, ...)
- Proposal-free method: các phương pháp như SSD, Yolo v2/v3, RetinaNet, ... đã đề cập bên trên
Anchor-base vs anchor-free method
-
Các thuật toán kể trên (Faster-RCNN, SSD, Yolo v2/v3, RetinaNet, ...) đều dựa 1 cơ chế gọi là Anchor hay các pre-define boxes với mục đích dự đoán vị trí của các bounding box của vật thể dựa vào các anchor đó. Tuy nhiên, việc định nghĩa các anchor size + anchor ratio còn bị phụ thuộc rất nhiều về mặt dữ liệu.
-
1 cách tiếp cận khác là Anchor-Free, tức không sử dụng anchor. Các mô hình kiểu này thực ra cũng đã có từ khá lâu, điển hình là mô hình DenseBox, nhưng bị lãng quên 1 thời gian khá dài. Tuy nhiên, trong năm 2019, rất nhiều các paper về Anchor-Free ra đời và được đánh giá tốt hơn so với các phương pháp anchor-based hiện nay, cả về phần đánh giá (mAP) và performance của model (FPS & Flops). 1 vài paper điển hình như:
- DenseBox
- FCOS / FSAF
- CornetNet
- CenterNet (Object as Point)
- ...
RPN (Region Proposal Network)
-
Luồng xử lý của Faster-RCNN có thể tóm gọn lại như sau:
- Input image được đưa qua 1 backbone CNN, thu được feature map
- 1 mạng con RPN (khá đơn giản, chỉ gồm các conv layer) dùng để trích rút ra các vùng gọi là RoI (Region of Interest), hay các vùng có khả năng chứa đối tượng từ feature map của ảnh. Input của RPN là feature map, output của RPN bao gồm 2 phần: binary object classification (để phân biệt đối tượng với background, không quan tâm đối tượng là gì) và bounding box regression (để xác định vùng ảnh có khả năng chứa đối tượng), vậy nên RPN bao gồm 2 hàm loss và hoàn toàn có thể được huấn luyện riêng so với cả model.
- Faster-RCNN còn định nghĩa thêm khái niện anchor, tức các pre-defined boxes đã được định nghĩa trước lúc huấn luyện mô hình với mục đích như sau: thay vì mô hình phải dự đoán trực tiếp các tọa độ offset của bounding box sẽ rất khó khăn thì sẽ dự đoán gián tiếp qua các anchors
- Sau khi đi qua RPN, ta sẽ thu được vùng RoI với kích thước khác nhau (W & H) nên sử dụng RoI Pooling (đã có từ Fast-RCNN) để thu về cùng 1 kích thước cố định
- Thực hiện tách thành 2 nhánh ở phần cuối của model, 1 cho object classification với N + 1 (N là tổng số class, +1 là background) với bounding box regression. Vậy nên sẽ định nghĩa thêm 2 thành phần loss nữa (khá tương tự như RPN) và loss function của Faster-RCNN sẽ gồm 4 thành phần: 2 loss của RPN, 2 loss của Fast-RCNN!
-
Faster-RCNN sử dụng 1 mạng con gọi là RPN (Region Proposal Network) với mục đích trích xuất ra các vùng có khả năng chứa đối tượng từ ảnh (hay còn gọi là RoI - Region of Interest), khác hoàn toàn với cách xử lý của 2 mô hình anh em trước đó là RCNN và Fast-RCNN

- Với RCNN, việc trích xuất các vùng region proposal được thực hiện thông qua thuật toán Selective Search (ảnh minh họa bên trên) để trích chọn ra các vùng có khả năng chứa đối tượng (khoảng 2000 vùng). Sau đó, các vùng (ảnh) này được resize về 1 kích thước cố định và đưa qua 1 pretrained CNN model (imagenet), rồi từ đó tiến hành xác định offset và nhãn đối tượng. Tuy nhiên, việc đưa các vùng region proposal qua mạng CNN 2000 lần khiến tốc độ thực thi của model cực kì chậm!
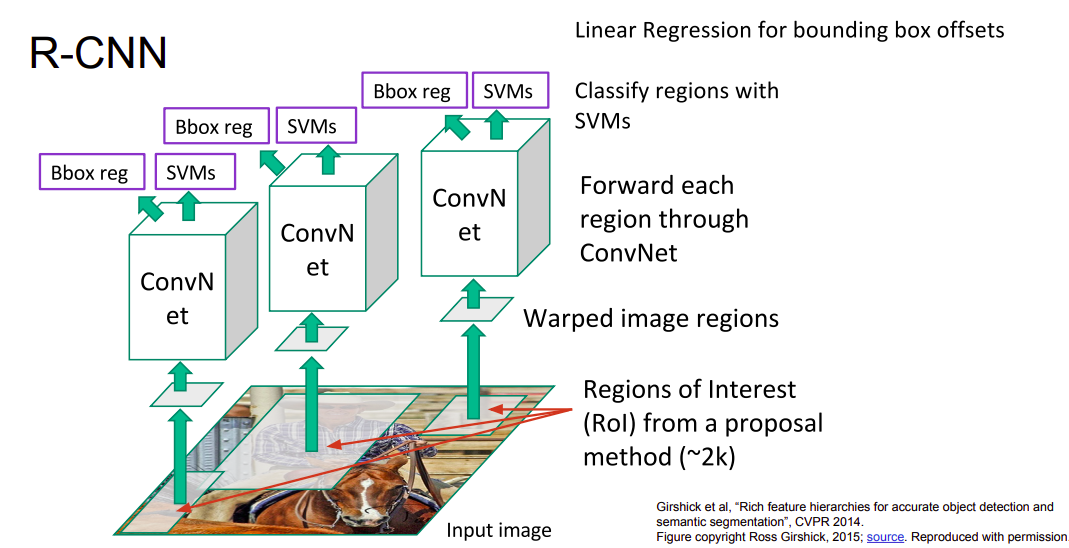
- Với Fast-RCNN, bằng việc sử dụng 1 mạng pretrained CNN để thu được feature map, rồi sử dụng Selective Search lên feature map, thay vì là ảnh gốc. Vậy nên tốc độ xử lý của model được cải thiện lên đáng kể vì chỉ phải đưa qua pretrained CNN model đúng 1 lần. Tuy nhiên, vì việc vẫn sử dụng Selective Search nên inference time của model vẫn khá lâu (khoảng 2s/image)
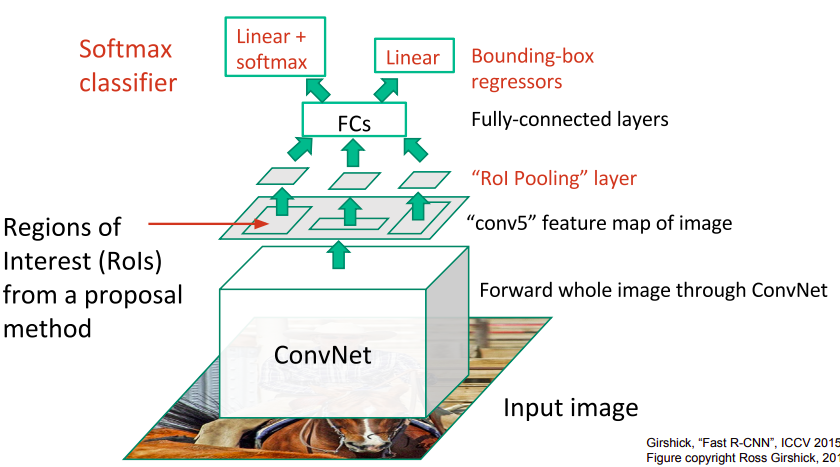
- Với Faster-RCNN, thay vì việc sử dụng Selective Search, mô hình được thiết kế thêm 1 mạng con gọi là RPN (Region Proposal Network) để trích rút các vùng có khả năng chứa đối tượng của ảnh. Nhìn chung, sau khi thực hiện RPN, các bước xử lý sau tương tự như Fast-RCNN nhưng nhanh hơn nhiều (vì không sử dụng Selective Search) và được thiết kế như 1 mạng end-to-end trainable network!

-
Về cơ bản, đầu tiên RPN sử dụng 1 conv layer với 512 channels, kernel_size = (3, 3) lên feature map. Sau đó được chia 2 nhánh, 1 cho binary object classification, 1 cho bounding box regression. Cả 2 sử dụng 1 conv layer với kernel_size = (1, 1) nhưng với số channel đầu ra khác nhau. Với binary object classification thì có 2k channel output, với k là tổng số lượng anchors nhằm xác định rằng 1 anchor có khả năng chứa đối tượng hay là background (không quan tâm đối tượng là gì). Thực chất, ở đây số channel có thể chuyển về chỉ còn k channel với việc sử dụng sigmoid activation. Với bounding box regression thì có 4k channel output, với 4 là biểu trưng cho 4 tọa độ offset (x, y, w, h)
-
Chú ý rằng, RPN hiện tại là 1 mạng fully convolution network nên không cần kích thước đầu vào phải cố định hay ảnh đầu vào của Faster-RCNN phải cố định. Tuy nhiên, nhìn chung ta thường tiến hành resize ảnh về 1 base_width / base_height nhất định mà image ratio vẫn giữ nguyên, hoặc set 2 khoảng giá trị min / max như repo của TF Object Detection API: https://github.com/tensorflow/models/blob/master/research/object_detection/samples/configs/faster_rcnn_inception_v2_coco.config#L13-L14
-
Vì đầu vào kích thước ảnh không cố định nên kích thước đầu ra của RPN cũng không cố định. Ví dụ với 1 ảnh đầu vào với kích thước WxHx3, với down sampling = 16 thì RPN_classify và RPN_bounding_box_regression lần lượt có kích thước là: 18 * (W / 16) * (H / 16) và 36 * (W / 16) * (H / 16). Mình sẽ đề cập kĩ hơn tại phần Roi-Pooling
Anchors
Anchors là gì và tại sao phải cần chúng
-
Anchor hay còn gọi là các pre-defined boxes, được định nghĩa trước lúc khi huấn luyện mô hình. Anchor trong Faster-RCNN được định nghĩa với 9 anchors ứng với mỗi điểm pixel trên feature map. Chú ý rằng, việc tính toán tổng số lượng anchor là dựa trên kích thước của feature map. Ví dụ feature map thu được sau khi đưa qua backbone cnn có kích thước là WxHxC (với C là số channel của feature map) thì tổng số lượng anchor là WxHx9 (9 là số lượng anchor ứng với 1 điểm pixel của feature map). Tuy nhiên, kích thước và ratio của anchor thì đều phải tham chiếu ngược lại kích thước của ảnh gốc ban đầu.
-
Các anchor được tạo ra là ứng với từng điểm pixel trên feature map và thông thường được định nghĩa với 3 anchor size và 3 anchor ratio khác nhau như hình dưới
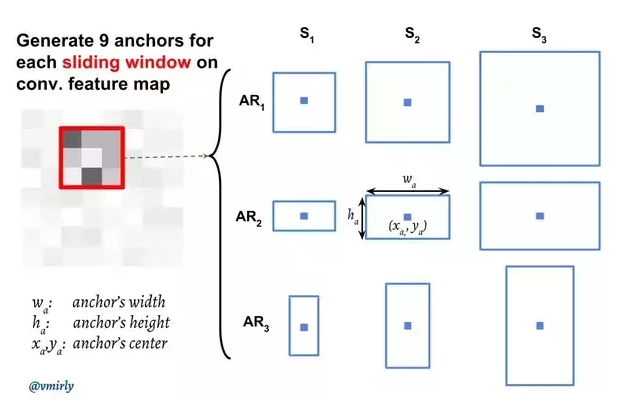
-
Các anchor này được assign là positive / negative (object / background) dựa vào diện tích trùng lặp hay IoU overlap với ground truth bounding box theo rule sau:
- Các anchor có tỉ lệ IoU lớn nhất với ground truth box sẽ được coi là positive
- Các anchor có tỉ lệ IoU >= 0.7 sẽ được coi là positive
- Các anchor có tỉ lệ IoU < 0.3 sẽ được coi là negative (background)
- Các anchor nằm trong khoảng 0.3 <= x < 0.7 sẽ được coi là neutral (trung tính) là sẽ không được sử dụng trong quá trình huấn luyện mô hình
-
Việc tạo ra các anchor nhằm mục đích như sau:
- Dựa vào IoU để phân biệt các positive và negative anchors
- Dựa vào vị trí của các pre-defined anchor và các ground-truth bounding box (thông qua tỉ lệ IoU), dự đoán vị trí của các region proposal đầu ra
-
Dễ thấy rằng, số lượng negative anchor là lớn hơn rất nhiều so với positive anchor, nên trong paper có đề cập tới 1 hướng xử lý để thực hiện training mô hình gọi là
image centric. Trong deep learning, các bạn đã nghe tới khái niệm batch_size, là số sample sẽ được xử lý trong 1 step. Trong Faster-RCNN, 1 batch-size sẽ chỉ ứng với 1 ảnh. Tuy nhiên, dữ liệu chính cần sử dụng ở đây là chính các pre-define anchor đã được định nghĩa. Vì tổng số lượng anchor là rất nhiều nên với 1 ảnh sẽ chỉ thực hiện lấy k=256 anchor là chia đều 2 phần (128 positive anchors + 128 negative anchors) -
Tuy nhiên, ko phải lúc nào cũng có đủ số lượng positive anchor trong 1 ảnh. Vậy nên, hướng xử lý trong paper là nếu không đủ positive anchor thì thay thế bằng các negative anchor khác.
Reference:
-
https://www.quora.com/How-does-the-region-proposal-network-RPN-in-Faster-R-CNN-work
-
Với các vùng RoI thu được sau RPN sẽ bị overlap lên nhau khá nhiều nên cần 1 cơ chế để filter-out các vùng đó. 1 phương pháp được đề xuất là NMS (Non-maximum suppresstion). Ý tưởng của NMS vô cùng đơn giản:
- Ta có 1 tập các vùng RoI thu được gọi là R kèm các confidence score S tương ứng và 1 giá trị overlap threshold N. Đồng thời, khởi tạo 1 list rỗng D
- Chọn vùng RoI với confidence score cao nhất và xóa khỏi R, thêm vào D
- So sánh vùng RoI mới được thêm vào D với tất cả các vùng RoI đang có trong R qua metric IoU. Nếu giá trị threshold lớn hơn giá trị overlap threshold N được khởi tạo ban đầu thì loại bỏ các vùng RoI đó ra khỏi R
- Tiếp tục chọn vùng RoI có confidence score cao nhất hiện tại có trong R và thêm vào D
- So sánh giá trị IoU của vùng vừa được thêm vào D với các vùng còn lại trong R, nếu > overlap threshold thì loại khỏi R
- Tiếp tục thực hiện như vậy đến khi không còn phần tử nào trong R.

-
Tuy nhiên, thuật toán NMS ban đầu cũng có những nhược điểm nhất định. Ví dụ như nếu ngưỡng overlap threshold là 0.5. Giả dụ có những vùng RoI có overlap IoU = 0.51 nhưng có confidence score rất cao nhưng lại bị loại khỏi tập R. Ngược lại, có những vùng RoI thỏa mãn overlap IoU < 0.5 nhưng confidence score không cao, nên không bị loại khỏi R và mô hình chung làm giảm "chất lượng" của model xuống.
-
1 thuật toán được đề xuất là Soft-NMS giúp cải thiện được việc dùng 1 giá trị overlap threshold fix cứng từ ban đầu. Ý tưởng vô cùng đơn giản: Thay vì loại bỏ các vùng RoI có overlap threshold cao mà confidence score lớn, ta thực hiện giảm confidence xuống tỉ lệ với giá trị IoU thu được.
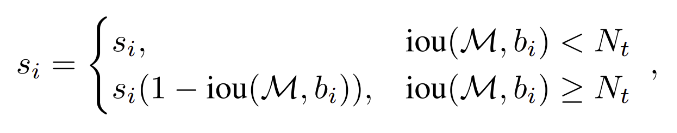
- Như công thức bên trên, với các RoI có IoU value >= N thì thực hiện giảm confidence score xuống bằng cách nhân với giá trị (1 - IoU), ngược lại giữ nguyên. Phương pháp cực kì đơn giản nhưng giúp làm tăng độ tự tin hay precision của model.
RoI Pooling
-
RoI Pooling đã được đề cập trong mô hình Fast-RCNN trước đó với mục đích cố định kích thước đầu ra của feature map sau khi thực hiện RoI Pooling. Việc thực hiện RoI Pooling là bắt buộc vì phần cuối của mạng gồm 2 nhánh fully connected layer nên yêu cầu input size phải cố định
-
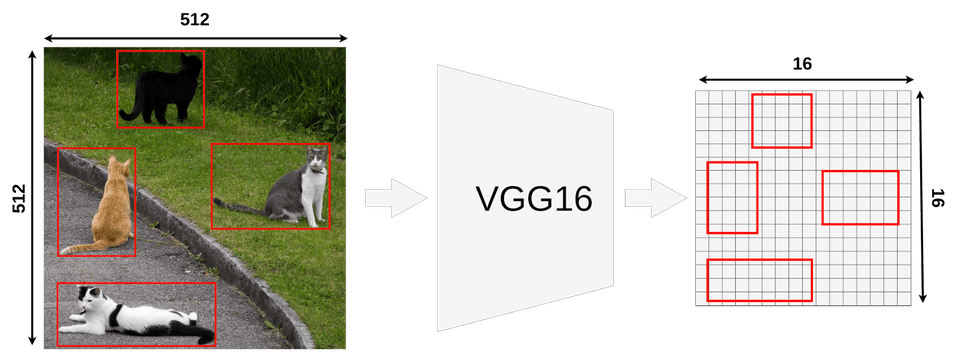
Hãy tưởng tượng ảnh minh họa 4 con mèo bên dưới gồm các vùng RoI (Region of Interest, thu được sau khi đi qua RPN) màu đỏ, thực tế số lượng vùng là lớn hơn rất nhiều và overlap nhau khá nhiều.

- Như đã nói ở phần trên, tọa độ offset của vùng RoI được xác định tham chiếu theo kích thước ảnh input nên ta cũng có thể trích rút các vùng RoI trên chính feature map. Có thể dễ thấy rằng kích thước của feature map nhỏ hơn 32 lần kích thước của ảnh đầu vào (từ 512 -> 16) nên tọa độ offset của các vùng RoI xét trên feature map (x, y, w, h) cũng sẽ bị giảm xuống 32 lần! Điều này là quan trọng và cần chú ý
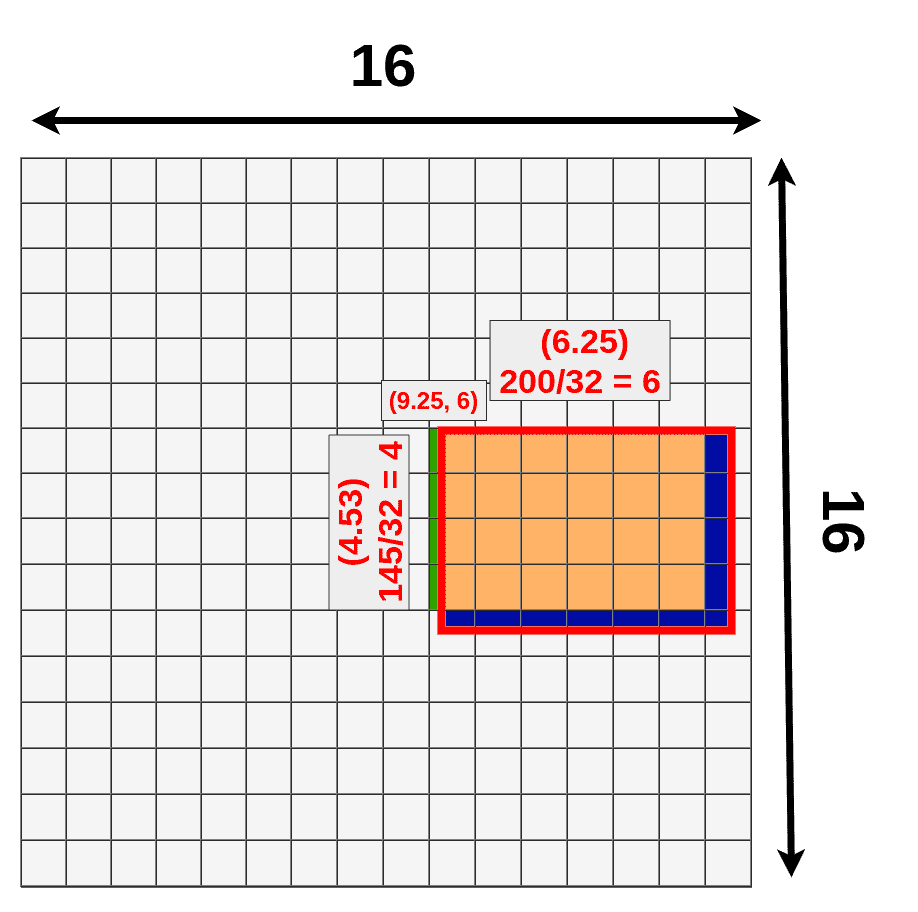
- Ta đơn giản hóa với 1 vùng RoI minh họa như hình dưới với x = 296, y = 192, w = 200, h = 145

- Sau khi downscale 32 lần, thu được các tọa độ mới (ứng với feature map) là
x_new = 296 / 32 = 9.25
y_new = 192 / 32 = 6.0
w_new = 200 / 32 = 6.25
h_new = 145 / 32 = 4.53
- Tuy nhiên, hiện tại feature map còn lại kích thước rất bé (16x16) và ta cần 1 cơ chế để có thể chuyển các tọa độ đó về dạng nguyên (int). Cách đơn giản nhất là làm tròn tới số tự nhiên gần nhất. Minh họa như bên dưới
-
Với vùng màu cam là vùng feature map không bị ảnh hưởng bởi downscale. Vùng xanh nước biển là phần thông tin bị mất đi và vùng xanh là cây là vùng thông tin nhận thêm do việc làm tròn số. Đây là cách xử lý đơn giản mà mô hình chấp nhận 1 phần sai số đó
-
Sau khi thu được vùng RoI ứng với feature map, việc cần làm tiếp theo là transform các vùng RoI đó về 1 kích thước cố định. 1 giải pháp gọi là RoI Pooling được sử dụng, thực chất vẫn là Max Pooling nhưng được xử lý để output feature map là cố định. Ví dụ với ảnh gif bên dưới
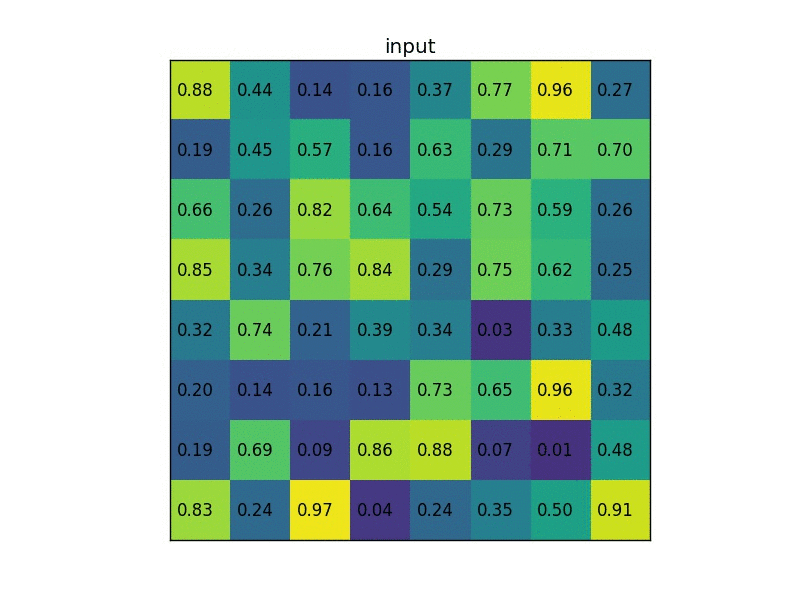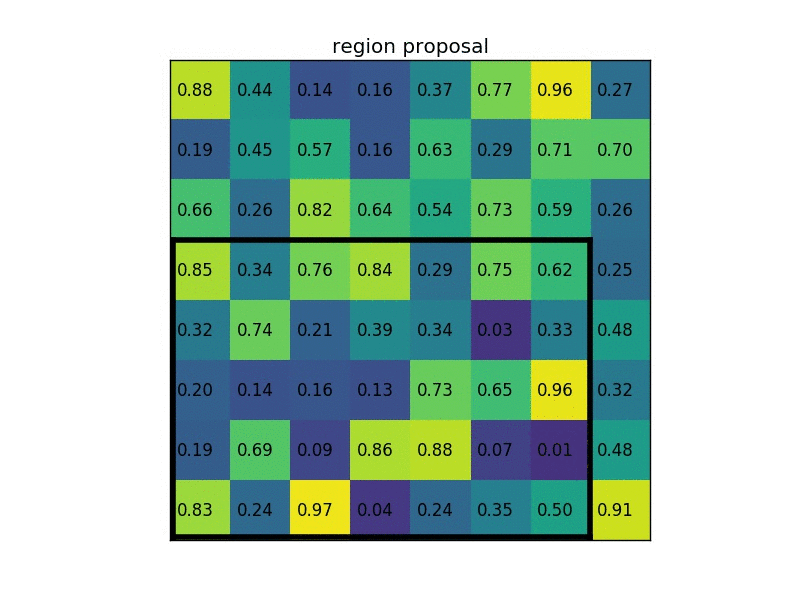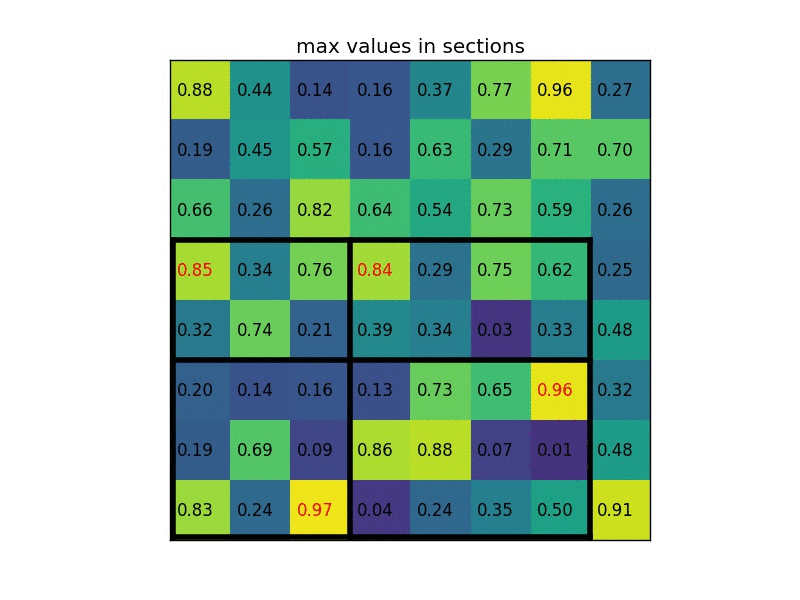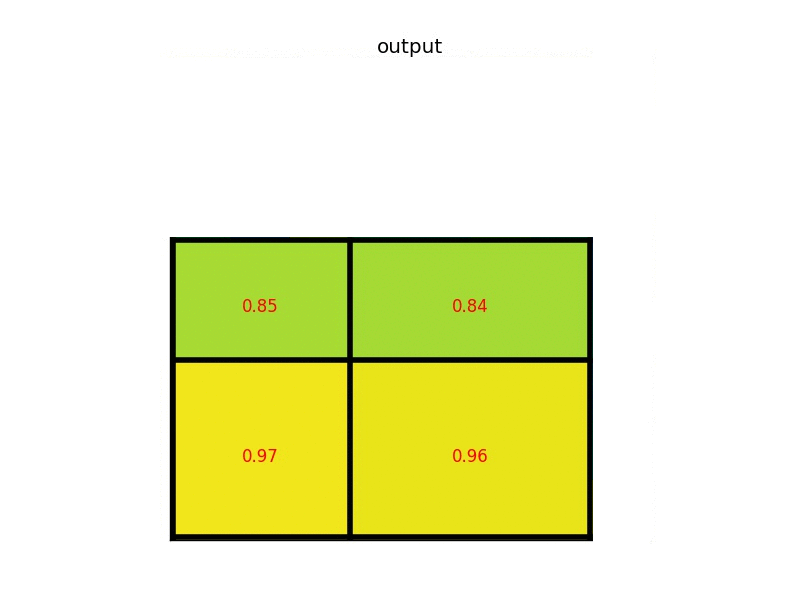
- Ví dụ với 1 vùng RoI 5x7 thu được trên feature map (sau khi thực hiện "làm tròn" số như trên), ta muốn output feature map có kích thước cố định là 2x2 chẳng hạn, ta thực hiện tính toán size của 1 vùng bằng cách lấy phần nguyên của RoI chia cho kích thước của output feature map. Ví dụ 5 // 2 = 2, 7 // 2 = 3 --> nên các vùng sẽ có độ bao phủ 2x3, với các vùng ngoài cùng sẽ được mở rộng thêm 1 đơn vị tùy vào hàng hay cột nên các vùng có độ bao phủ lần lượt là: 2x4, 3x3 và 3x4 như hình trên. Cuối cùng thực hiện lấy giá trị lớn nhất trên từng vùng (Max Pooling), thu được output feature map với đầu ra cố định là 2x2
Việc sử dụng RoI Pooling cũng có những hạn chế nhất định, ví dụ như việc "làm tròn" số bên trên gây mất mát 1 phần thông tin. 1 số phương pháp được đề xuất như RoIWarp và RoIAlign (sử dụng bilinear interpolation) được sử dụng trong Mask-RCNN giúp giải quyết được vấn đề này tốt hơn!
Reference:
- https://stackoverflow.com/questions/43430056/
- https://lilianweng.github.io/lil-log/2017/12/31/object-recognition-for-dummies-part-3.html
Detection model
- Sau khi thực hiện RoI Pooling, ta thu được các output feature map với kích thước cố định, các feature map này sẽ được flatten và đưa qua 2 nhánh fully connected layer nhằm thực hiện:
- Object classification với N + 1 class (N là tổng số class, +1 là background)
- Bounding box regression để tuning các tọa độ thu được của các vùng RoI với ground truth bounding box, gồm 4N node output, biểu trưng cho 4 tọa độ offset (x, y, w, h)
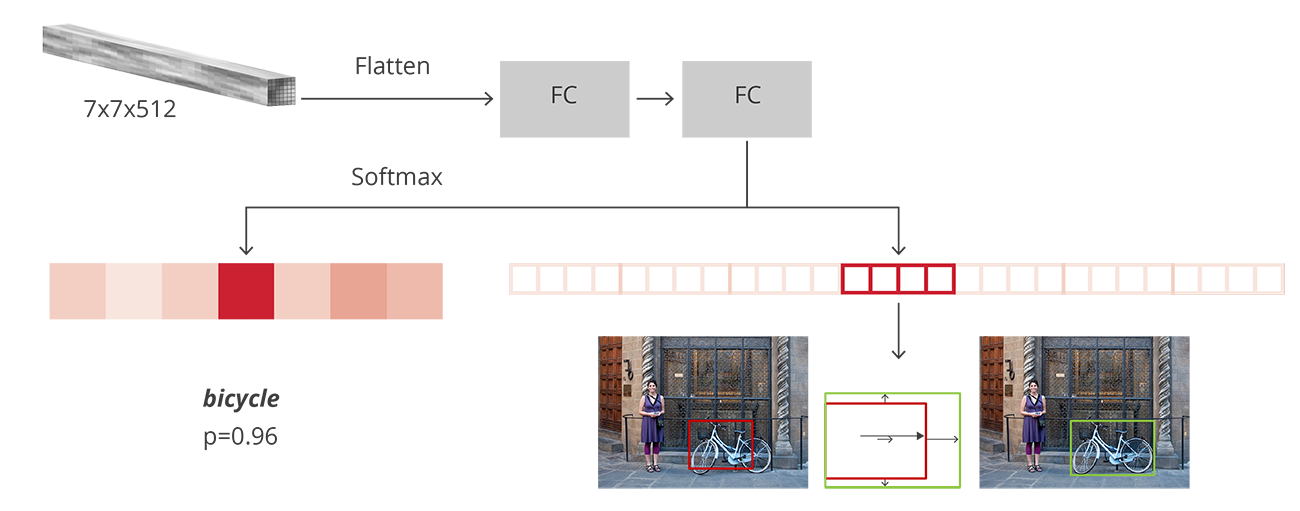
- Bước NMS cũng thực hiện tương tự như RPN bên trên
Loss function (Faster-RCNN model)
-
Như đã đề cập bên trên, multi-task loss function của model Faster-RCNN gồm 4 thành phần:
- RPN classification (binary classification, object or background)
- RPN regression (anchor -> region proposal)
- Fast-RCNN classification (over N+1 classes)
- Fast-RCNN bounding box regression (region proposal -> ground truth bounding box)
-
Loss function sẽ được định nghĩa với công thức như bên dưới
-
Trong đó, là index của anchor trong 1 mini-batch và là xác suất dự đoán cho anchor tại index thứ là 1 đối tượng. Chú ý, loss cho bounding box regression chỉ được tính khi anchor là positive (cách xác định anchor là positive / negative / neural theo rule như đã đề cập bên trên)
-
với RPN là binary crossentropy để xác định anchor có chứa đối tượng (object) hay không. với FastRCNN tại phần cuối của mô hình là Multi-class cross-entropy loss với (N + 1) classes.
-
là loss tính cho bounding box regression. Có thể dùng L2 hoặc L1 loss, tuy nhiên trong paper có đề cập sử dụng hàm loss Smooth L1 Loss. Smooth L1 Loss có thể được xem như sự kết hợp của L1 và L2 loss, với gradient tăng ổn định khi x lớn với L1 loss và gradient ít dao động khi x nhỏ (L2 loss). Công thức của Smooth L1 loss dạng đơn giản:
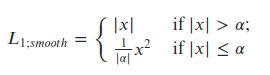
- 1 dạng khác của Smooth L1 loss hay còn gọi là Huber-loss được định nghĩa như sau:
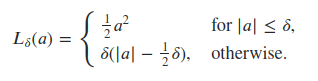
Reference:
- https://deepmlml.com/rpn-explained.html
- https://stats.stackexchange.com/questions/351874/how-to-interpret-smooth-l1-loss
Metric đánh giá
Precision vs Recall
- Trước khi đi sâu vào tìm hiểu về mAP, hãy cùng bàn lại 2 metric thông dụng khác là Precision và Recall. Với Precision được mô tả theo công thức sau
và recall
-
Hãy cùng định nghĩa rõ hơn các thông số TP / FP / TN / FN trong công thức của precision và recall. Đầu tiên, cần phải hiểu rõ True / False và Positive / Negative ở đây là biểu thị cho điều gì?
-
Ví dụ bạn làm 1 bài toán về phân loại mail spam thì việc mail là spam sẽ được coi là Positive, mail ko phải spam là Negative. True / False ở đây sẽ biểu thị rằng việc chẩn đoán của mô hình là đúng hay sai. Ví dụ:
- True Positive: mail được mô hình dự đoán là spam (Positive) và thực tế thì mail đó đúng là spam (True)
- False Positive: mail được mô hình dự đoán là spam (Positive) nhưng thực tế thì mail đó không phải spam (False), nghĩa là dự đoán nhầm 1 mail không phải spam là spam
- True Negative: mail được dự đoán không phải spam (Negative) và đúng là như vậy (True)
- False Negative: mail được dự đoán không phải spam (Negative) nhưng thực tế điều đó là sai (False), nghĩa là dự đoán nhầm 1 mail spam là không spam!
-
Mở rộng hơn ra các bài toán khác, ví dụ với bài toán chẩn đoán bệnh ung thư cũng tương tự như vậy. Vậy nên, trong trường hợp này, người ta thường sẽ để ý đến thông số FN (False Negative) hơn là thông số (FP) False Positive, tức việc dự đoán nhầm người có bệnh thành không có bệnh sẽ nguy hiểm hơn chiều ngược lại (FN > FP)
-
Để dễ hiểu hơn, các bạn có thể xem kĩ hơn ảnh minh họa như bên dưới
)

- Trong bài toán Object Detection, việc định nghĩa thế nào là TP / FP / TN / FN sẽ phức tạp hơn 1 chút, mình sẽ đề cập kĩ hơn tại phần bên dưới.
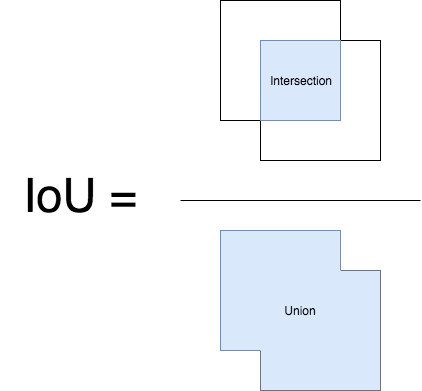
IoU
- IoU hay Intersection over Union hoặc Jaccard Index là độ đo để biểu diễn độ tương đồng giữa ground truth bounding box với predicted bounding box của mô hình, giá trị trong đoạn từ 0 đến 1, 2 box càng khớp nhau thì giá trị càng gần 1 và ngược lại

mAP (mean Average Precision)
-
mAP là 1 metric đánh giá được sử dụng phổ biến trong các bài toán về Information Retrieval và Object Detection. Tuy nhiên, cùng 1 tên gọi là mAP nhưng cách tính trong 2 bài toán là không giống nhau. Về mAP metric trong bài toán Information Retrieval, các bạn có thể đọc thêm phần giải thích tại link sau, ví dụ với 1 bài toán tìm kiếm ảnh tương đồng:
-
Đầu tiên là việc định nghĩa TP / FP / FN / TN cho bài toán Object Detection, với 1 class
- TP (True Positive): là các predicted box với IoU lớn hơn hoặc bằng 1 giá trị IoU cố định (thường là 0.5)
- FP (False Positive): là các predicted box với IoU nhỏ hơn 0.5
- FN (False Negative): mô hình không bắt được đối tượng trong ảnh (ứng với ground truth tương ứng)
- TN (True Negative): ta không cần quan tâm đến thông số này. Có thể hiểu là những phần của ảnh không chứa đối tượng và thực tế thì đúng là như vậy.
-
Theo đúng định nghĩa, Precision là thông số thể hiện tỉ lệ các dự đoán là đúng (so với ground truth) so với tổng số các dự đoán của model. Recall, hay độ nhạy cảm là thông số thể hiện tỉ lệ dự đoán đúng trên tổng số ground truth. Hay trong bài toán Object Detection, precision và recall còn được biểu hiện theo 2 cách sau
và recall
-
Dễ nhận thấy rằng, với 1 class:
- Ví dự với Precision = 0.8 tức việc khi 1 đối tượng được phát hiện thì khả năng 80% đối tượng đó được phát hiện là chính xác
- Ví dụ với recall = 0.6 tức việc mô hình dự đoán đúng được 60% đối tượng so với toàn bộ ground truth bounding box ban đầu
- Precision thấp, recall cao ứng với việc đa số các đối tượng đều được phát hiện nhưng rất nhiều trong số đó được dự đoán lệch khá nhiều so với gt bbox, tức diện tích trùng lặp IoU thấp (nhiều False Positive)
- Precision cao, recall thấp ứng với việc khá nhiều predicted boxes được dự đoán khá chuẩn xác, khớp với gt bbox, tức diện tích trùng lặp cao. Tuy nhiên, mô hình lại không bắt được nhiều đối tượng, bị miss nhiều gt bbox khác (nhiều False Negative)
-
Nếu để ý kĩ rằng, thực tế, ta chỉ cần tính toán 2 thông số là TP và FP dựa vào IoU giữa ground truth bbox với predicted bbox, kết hợp với giả thiết có M ground truth bbox của class A trên tập dữ liệu (chính là phần mẫu số trong công thức của recall) là có thể tính toán ra 2 metric tương ứng là Precision và Recall. Không cần tính toán số lượng FN (False Negative) và không cần quan tâm tới thông số TN (True Negative). Để hiểu rõ hơn thì các bạn xem thêm phần ví dụ bên dưới.
Tính toán precision và recall của Object Detection
- Hãy cùng tính toán 2 giá trị precision và recall với ảnh ví dụ bên dưới
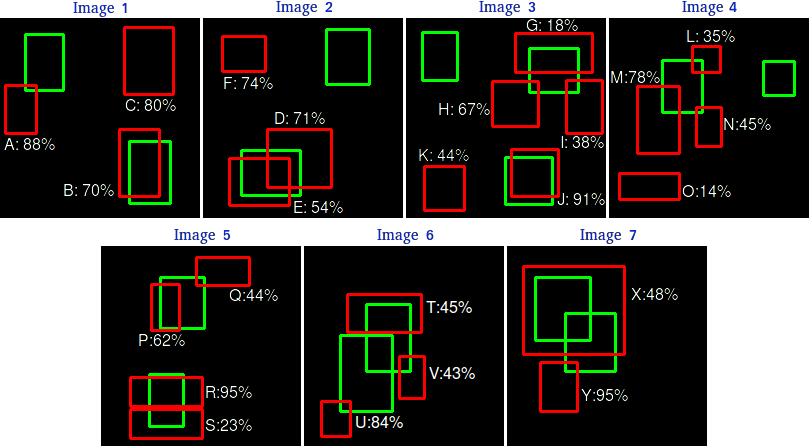
-
Như trên hình với 7 bức ảnh, 15 ground truth bounding box (màu xanh lá) và 24 predicted bounding box (màu đỏ). Các con số cạnh các chữ cái (A-Z) biểu thị confidence score output của mô hình!
-
Việc đầu tiên cần làm là xác định tất cả các TP và FP trên tất cả các hình, ngưỡng IoU để xác định TP / FP được lấy = 0.3, hay diện tích trùng lặp giữa predicted bbox và ground truth bbox >= 0.3 thì được coi là TP, ngược lại là FP. Ta có bảng thống kê như bên dưới, ta chưa cần quan tâm tới chỉ số confidence score vội:
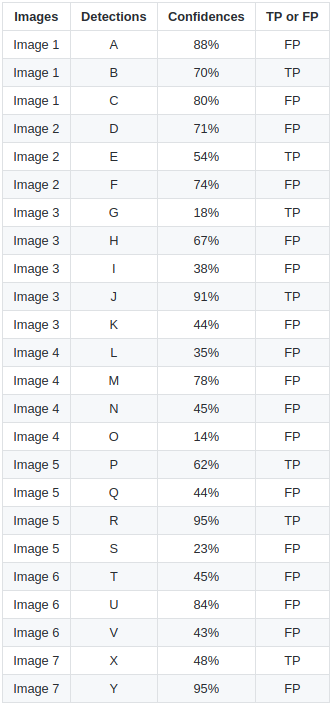
- Chú ý rằng, với những ground truth bbox bị trùng lặp với nhiều predicted bbox thì predicted bbox có IoU cao nhất sẽ được coi là True Positive (TP), các predicted bbox còn lại sẽ được coi là FP (False Positive). Vậy nên, giả dụ với image2, 2 predicted bbox D, E đều có IoU >= 0.3 nhưng bbox E có IoU cao hơn nên được coi là TP, D được xem là FP. Tương tự với các ảnh khác cũng vậy!
Precision / Recall với confidence score - PR-curve
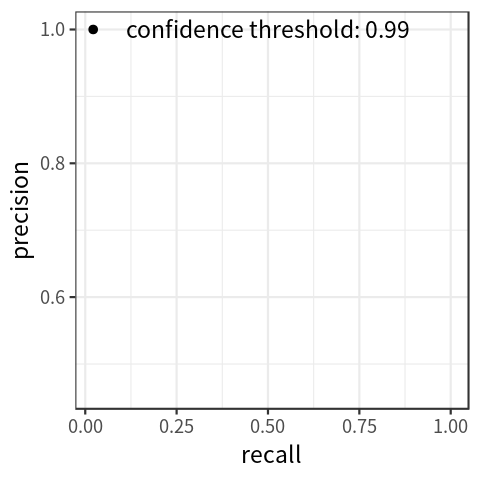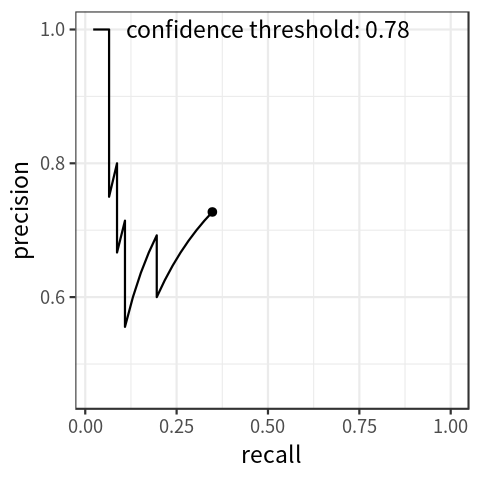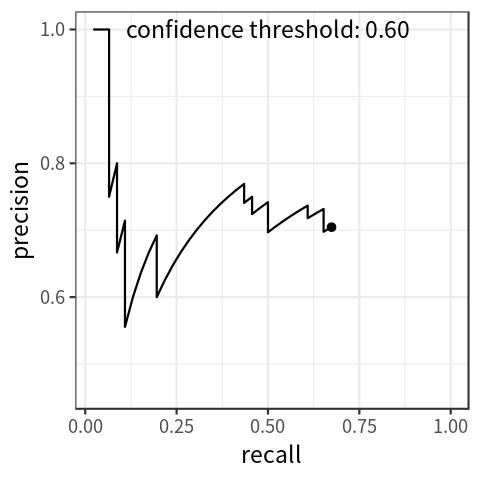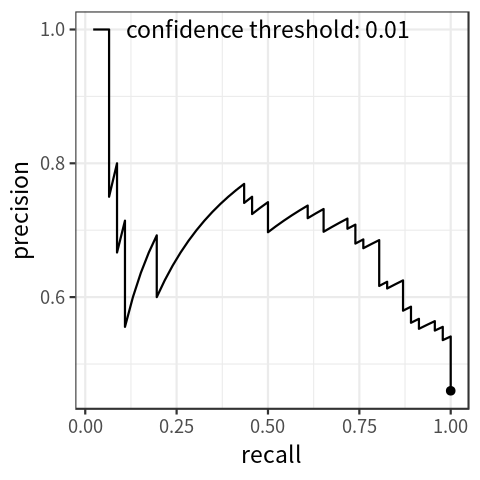
-
PR-curve thể hiện mối liên hệ giữa 2 giá trị Precision và Recall khi điều chỉnh ngưỡng confidence score. Ta quy định thêm 2 thông số là AccTP và AccFP, lần lượt là TP tích lũy và FP tích lũy, sẽ được cộng dồn từ TP / FP với bảng giá trị đã được sắp xếp theo confidence score giảm dần như bên dưới
-
Có 1 chú ý nữa rằng, trong công thức của Recall, phần mẫu chính là tổng tất cả các ground truth bbox, vậy nên ta cũng ko cần thiết phải tính toán thông số FN!
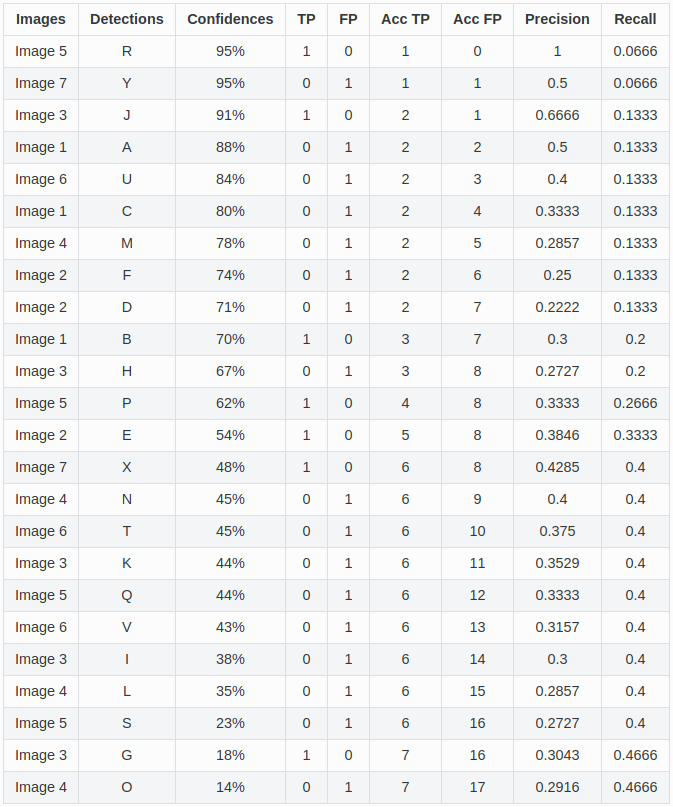
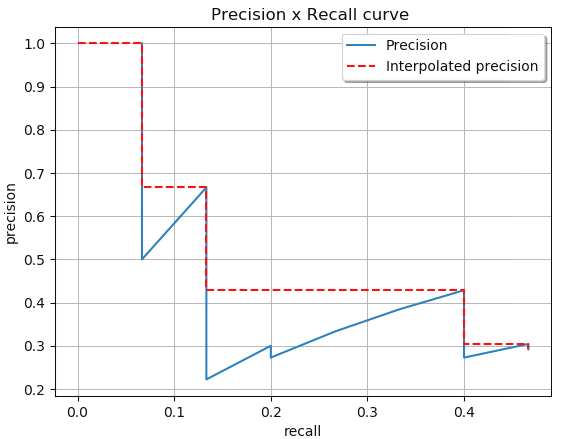
- Lấy ví dụ cách tính toán Precision và Recall ứng với từng dòng
>>> Dòng 1 - image5 - predicted box R - confidence score = 0.95
- R có IoU cao hơn so với S nên R là TP, AccTP = 1, AccFP = 0
- Precision = 1 / (1 + 0) = 1
- Recall = 1 / (all ground truths) = 1 / 15 = 0.0666 >>> Dòng 2 - image7 - predicted box Y - conf score = 0.95
- Y có conf score cao nhưng IoU thấp < 0.3 nên Y là FP, AccTP vẫn = 1, AccFP = 1
- Precision = 1 / (1 + 1) = 0.5
- Recall = 1 / (all gts) = 1 / 15 = 0.0666 >>> Dòng 3 - image3 - predicted box J - conf score = 0.91
- J có IoU > 0.3 nên J là TP. Chú ý, vì là tích lũy nên AccTP = 1 + 1 = 2, AccFP = 1
- Precision = 2 / (2 + 1) = 2 / 3 = 0.666
- Recall = 2 / (all gts) = 2 / 15 = 0.1333 >>> Dòng 4 - image1 - predicted box A - conf score = 0.88
- A có IoU < 0.3 nên A là FP ==> AccTP = 2, AccFP = 1 + 1 = 2
- Precision = 2 / (2 + 2) = 2 / 4 = 0.5
- Recall = 2 / 15 = 0.1333 >>> Dòng 5 - image6 - predicted box U - conf score = 0.84
- U có IoU < 0.3 nên U là FP ==> AccTP = 2, AccFP = 2 + 1 = 3
- Precision = 2 / (2 + 3) = 2 / 5 = 0.4
- Recall = 2 / 15 = 0.1333 ... >>> Dòng 9 - image 2 - predicted box D - conf score = 0.71
- D có IoU > 0.3, tuy nhiên E lại có IoU lớn nhất so với gt box lân cận (gt box màu xanh ở dưới bên trái của hình 2) nên E là TP, còn D là FP ==> AccTP = 2, AccFP = 6 + 1 = 7
- Precision = 2 / (2 + 7) = 2 / 9 = 0.2222
- Recall = 2 / 15 = 0.1333 ...
>>> Dòng 23 - image 3 - predicted box G - conf score = 0.18
- G có IoU > 0.3 và cũng là lớn nhất trong 3 predicted box (G, H, I) với gt box màu xanh trên cùng bên phải của hình 3 ==> G là TP ==> AccTP = 6 + 1 = 7, AccFP = 16
- Precision = 7 / (7 + 16) = 7 / 23 = 0.3043
- Recall = 7 / 15 = 0.46666 >>> Dòng 24
- O có IoU = 0 < 0.3 nên O là FP ==> AccTP = 7, AccFP = 16 + 1 = 17
- Precision = 7 / (7 + 17) = 7 / 24 = 0.2917
- Recall = 7 / 15 = 0.46666
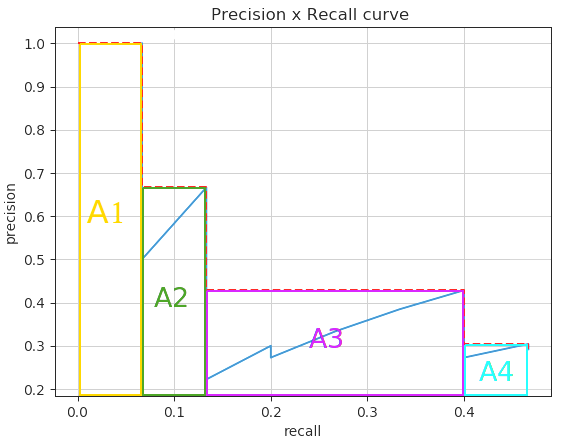
- Xong khi tính toán xong 2 giá trị Precision và Recall cho các predicted box, ta thu được đồ thị PR-curve như hình dưới
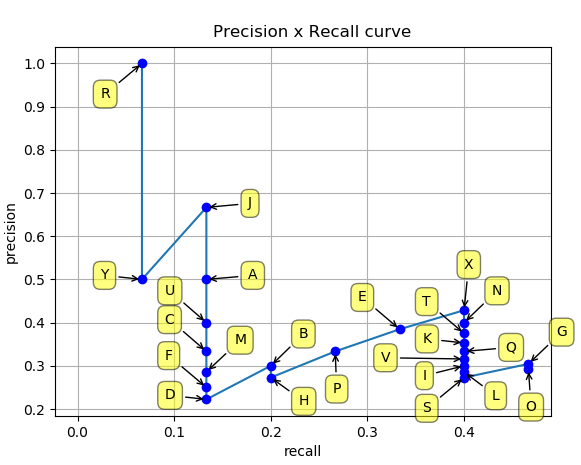
- Dễ nhận thấy rằng, với việc giảm confidence score, recall tăng dần, precision thì lúc xuống lúc lên nhưng nhìn chung là có xu hướng giảm khi confidence score giảm. AP (Average Precision) là thông số trung bình precision ứng với các mốc recall tương ứng, trong đoạn từ 0 đến 1, có 2 cách tính toán là 11-points-interpolated và all-points-interpolated
11-points-interpolated
- Với cách tính này, recall sẽ được chia đều thành 11 giá trị từ 0 -> 1 (0, 0.1, 0.2, ..., 1). Theo công thức
với
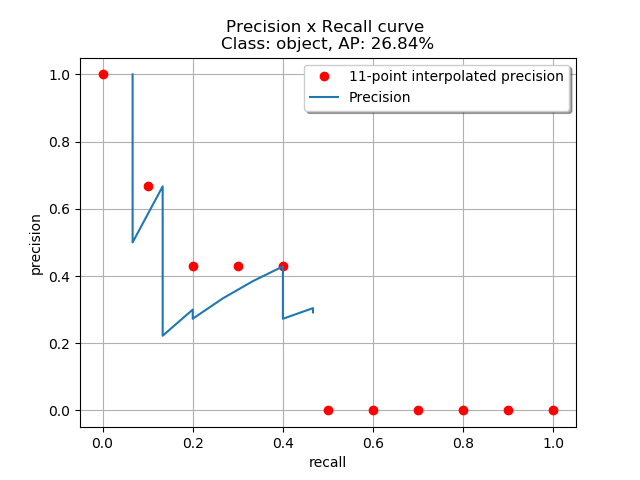
- Theo đúng công thức
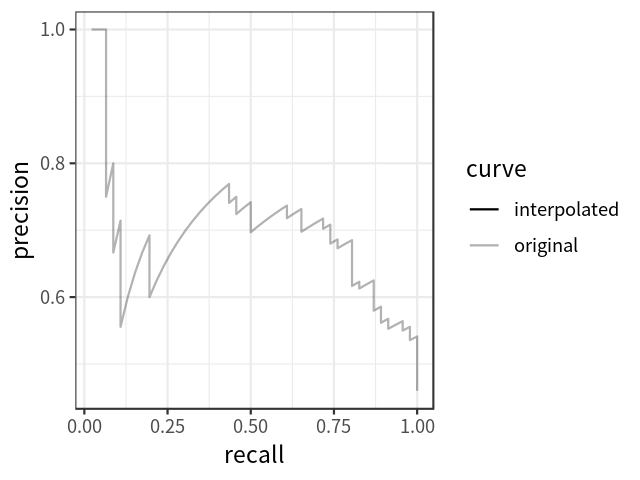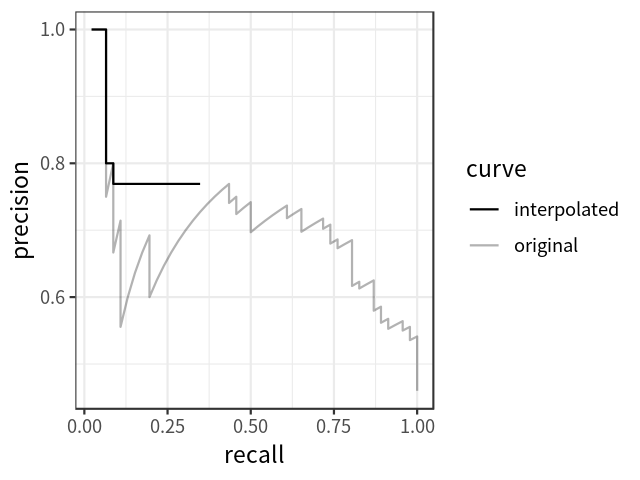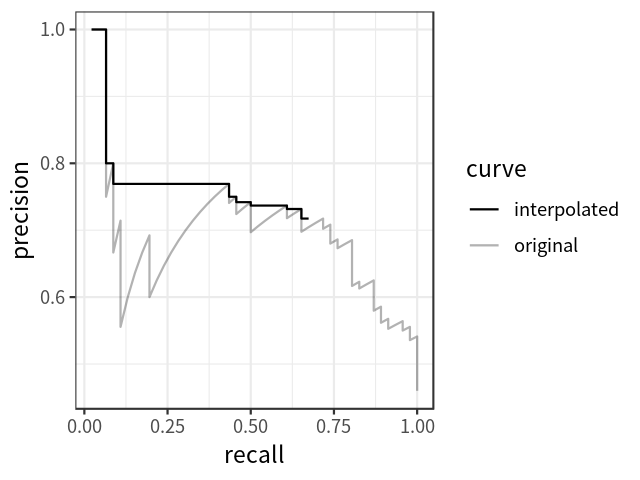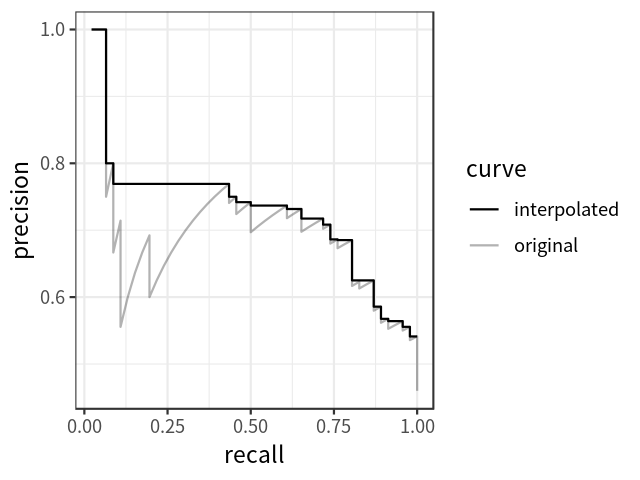
All-points-interpolated
- Cách tính All-points-interpolated cũng gần tương tự, khác là lần này ta tính toán phần diện tích bao phủ dưới PR-curve, với công thức:
với
- Theo đúng công thức
mAP (mean Average Precision)
- mAP đơn giản là trung bình AP score của n class, được định nghĩa với công thức
-
Như đã đề cập phía bên trên, việc xác định TP / FP ban đầu phải dựa vào ngưỡng giá trị IoU, như ví dụ bên trên là 0.3. Với các tập dữ liệu quen thuộc như PASCAL VOC thì IoU threshold = 0.5. Hay với tập dữ liệu MS COCO thì điểm mAP cuối cùng là giá trị trung bình mAP ứng với các ngưỡng IoU khác nhau, ví dụ là điểm mAP trung bình ứng với ngưỡng IoU (0.5, 0.55, 0.6, ...0.95), step = 0.05
-
Reference link: https://github.com/rafaelpadilla/Object-Detection-Metrics
Huấn luyện mô hình
-
Như phần kiến thức về RPN mình đã đề cập bên trên, trong paper gốc của Faster-RCNN, nhóm tác giả cũng có đề cập tới việc RPN có thể tách riêng và huấn luyện độc lập để lấy ra được các vùng Region Proposal (các vùng có khả năng chứa object / đối tượng).
-
Trong phần này, để đơn giản, mình sử dụng luôn module FasterRCNN đã có sẵn trong thư viện TorchVision để minh họa. Các bạn có thể tham khảo thêm tại trang chủ của Pytorch: https://pytorch.org/tutorials/intermediate/torchvision_tutorial.html
-
Về phần dữ liệu, mình tiến hành 1 số augment như sau:
- Color distortion
- HueSaturation & RandomBrightnessContract
- Blur & GaussNoise
- ToGray
- Horizontal & Vertical Flip
- Resize
-
Phần code augmentation sử dụng thư viện Albumentation
def get_train_transform(): return A.Compose( [ colorize, A.OneOf([ A.HueSaturationValue(hue_shift_limit=0.1, sat_shift_limit= 0.1, val_shift_limit=0.1, p=0.5), A.RandomBrightnessContrast(brightness_limit=0.1, contrast_limit=0.1, p=0.5), ],p=0.5), A.OneOf([ A.Blur(blur_limit=1, p=0.50), A.GaussNoise(var_limit=1.0 / 255.0, p=0.50) ], p=0.5), A.ToGray(p=0.2), A.HorizontalFlip(p=0.25), A.VerticalFlip(p=0.05), A.Resize(height=480, width=480, p=0.2), ToTensor(), ], p=1.0, bbox_params=A.BboxParams( format='pascal_voc', min_area=0, min_visibility=0, label_fields=['labels'] ) ) train_transform = get_train_transform()
Kết quả mô hình
- Reference repo: https://github.com/rafaelpadilla/Object-Detection-Metrics
Đánh giá mAP
- Với IoU threshold = 0.8, AP = mAP = 78.63
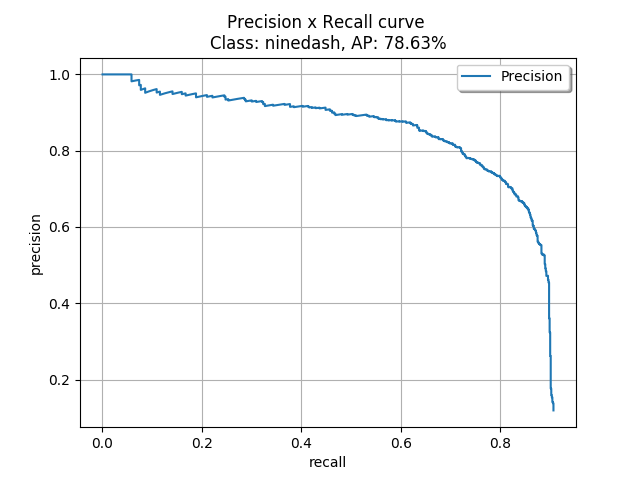
- Với , mean mAP = 72.196, với các ngưỡng IoU threshold từ 0.5 -> 0.95, step = 0.05:

1 số kết quả trên dữ liệu test
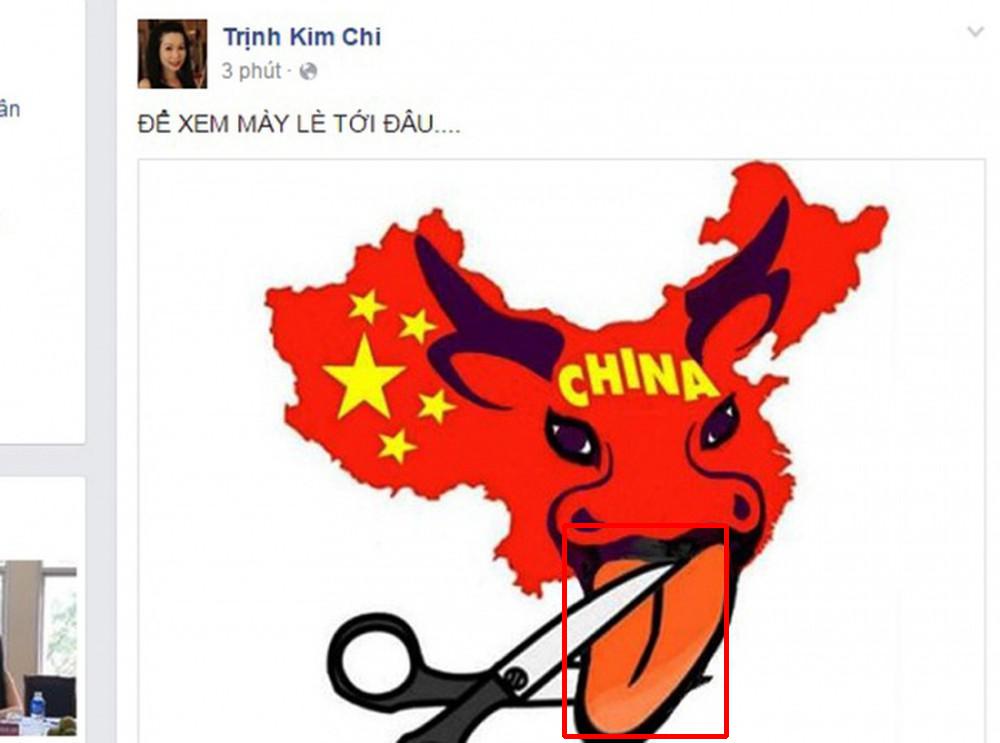
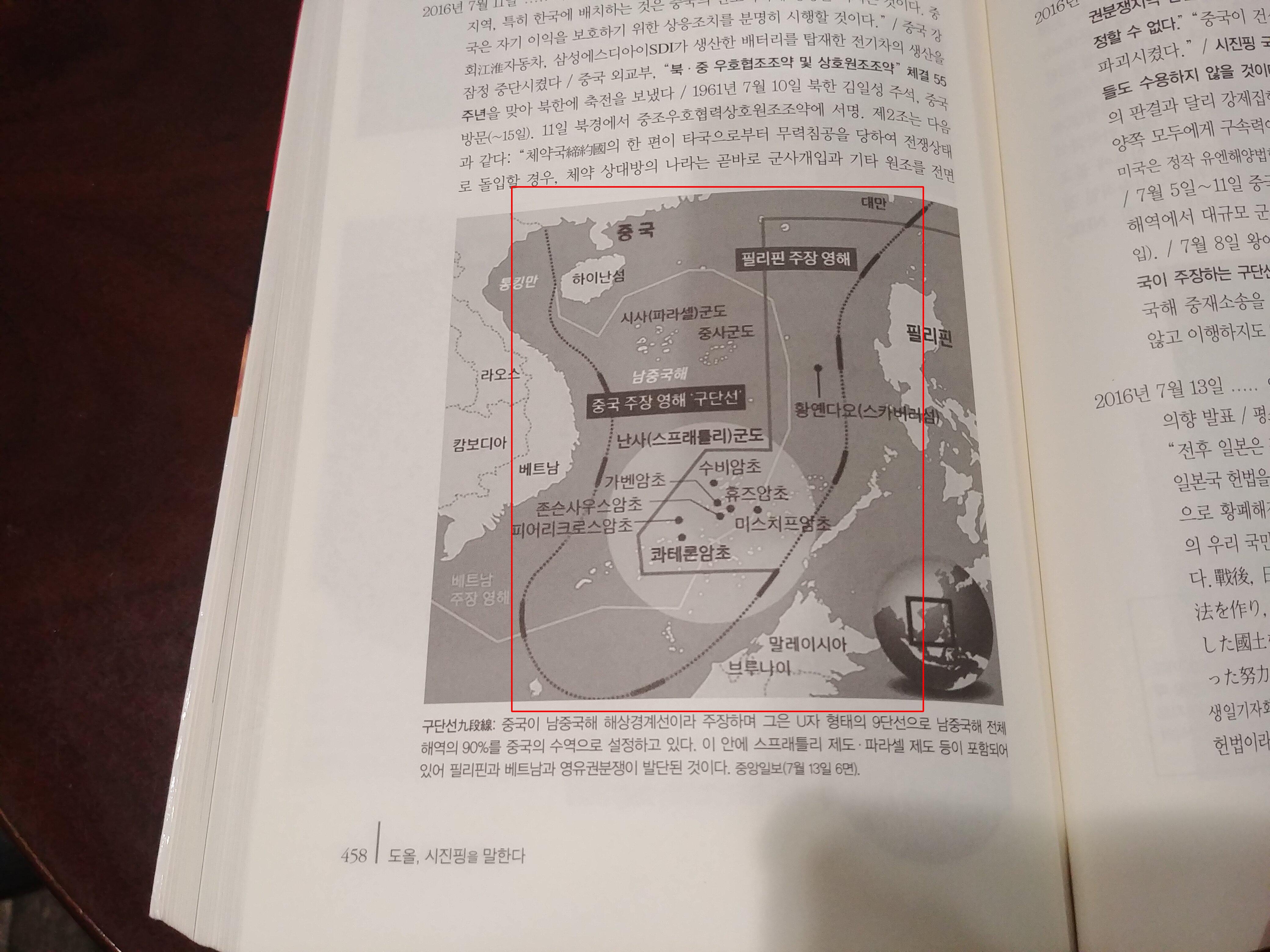
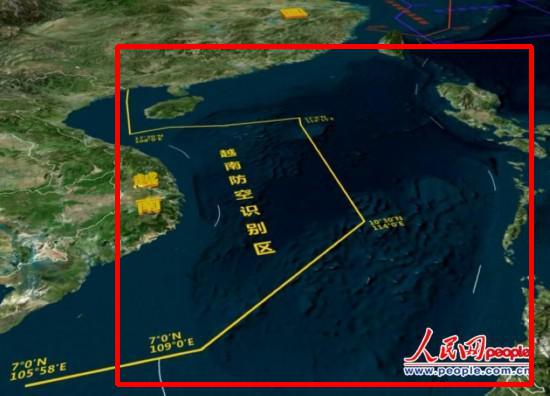
- Các bạn có thể xem thêm kết quả tại link driver sau: https://drive.google.com/drive/folders/1LiEigt9mNX314S8SuRd0qXWgYYGzPxtG?usp=sharing
Kết luận
-
) Cũng khá dài rồi, tổng kết lại thì trong bài blog này, mình đã đề cập tới 1 số vấn đề như:
- Đề cập kĩ hơn về mô hình Faster-RCNN (RPN, RoI Pooling, Loss Function, ...)
- Cách đánh giá 1 model Object Detection qua mAP metric
- Áp dụng vào 1 tập dữ liệu cụ thể là đường lưỡi bò
-
Mọi ý kiến đóng góp và phản hồi, các bạn vui lòng cmt bên dưới bài viết hoặc gửi mail về địa chỉ [email protected]. Cảm ơn các bạn đã đọc bài viết và hẹn gặp lại trong các bài blog sắp tới
-
Đừng quên upvote, share bài viết này nếu thấy nó hữu ích nhé

Other
- Mình gần đây cũng mới thấy bên Zalo public API 1 số service bên họ, mọi người có thể dùng thử xem, trong đó có API cho nhận diện đường lưỡi bò: https://zalo.ai/docs/api/nine-dash-line-detector

Reference
-
Faster-RCNN paper https://arxiv.org/abs/1506.01497
-
tryolab faster-rcnn https://tryolabs.com/blog/2018/01/18/faster-r-cnn-down-the-rabbit-hole-of-modern-object-detection/
-
RoI Pooling https://towardsdatascience.com/e4f5dd65bb44
-
Object Detection metric https://github.com/rafaelpadilla/Object-Detection-Metrics
-
https://pytorch.org/tutorials/intermediate/torchvision_tutorial.html
-
NMS https://towardsdatascience.com/non-maximum-suppression-nms-93ce178e177c
-
Faster-RCNN from scratch - Keras https://towardsdatascience.com/125f62b9141a
-
Faster-RCNN explained - Pytorch https://deepmlml.com/rpn-explained.html
-
Smooth-L1 loss https://stats.stackexchange.com/questions/351874/how-to-interpret-smooth-l1-loss
-
1-stage vs 2 stage object detection https://github.com/yehengchen/Object-Detection-and-Tracking/blob/master/Two-stage vs One-stage Detectors.md
-
https://towardsdatascience.com/fasterrcnn-explained-part-1-with-code-599c16568cff