
Vì sao sử dụng index có thể cải thiện tốc độ truy vấn?
Làm cách nào để xác định khi nào cần set index cho một column?
Bài viết này sẽ giúp anh em hiểu và tự tin set index chuẩn như quân đội.
I. Bài toán thực tế
Lấy ví dụ tình huống sau.
Anh quản lý và đôi chân sưng tấy
Anh A mới được bổ nhiệm làm quản lý 100 giường bệnh của một bệnh viện. Mỗi bệnh nhân nằm ở một phòng riêng biệt, phân biệt các bệnh nhân bằng mã bệnh nhân. Nhiệm vụ của A là quản lý danh sách bệnh nhân ở các phòng và hỗ trợ bác sĩ thăm khám.
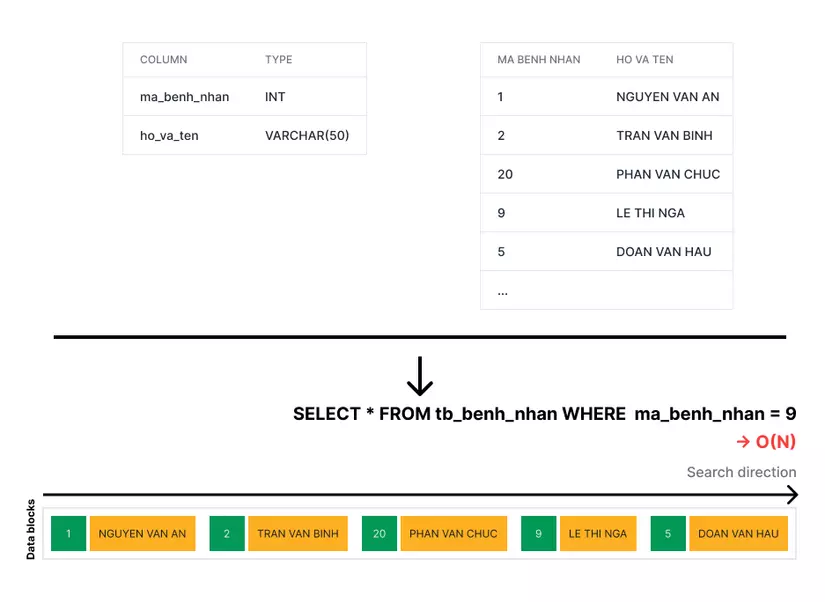
Tìm kiếm bệnh nhân - Cuộc sống không có index
Trong ngày, các bác sĩ sẽ đến khám riêng cho từng bênh nhân hoặc một nhóm bệnh nhân.
Bác sĩ cho A một danh sách các mã bệnh nhân và yêu cầu A cho họ biết các bệnh nhân này ở phòng nào.
A đi hết 100 phòng, hỏi từng bệnh nhân, đối chiếu với mã bệnh nhân của bác sĩ để lấy được danh sách hoàn chỉnh.
Hơi vất vả nhưng A vẫn hài long với công việc hiện tại. Bắp chân A to lên, rắn chắc, A thầm cảm ơn những ngày làm việc vất vả chạy qua chạy lại 100 phòng đến hơn chục lượt.
Index - cuốn sổ cái
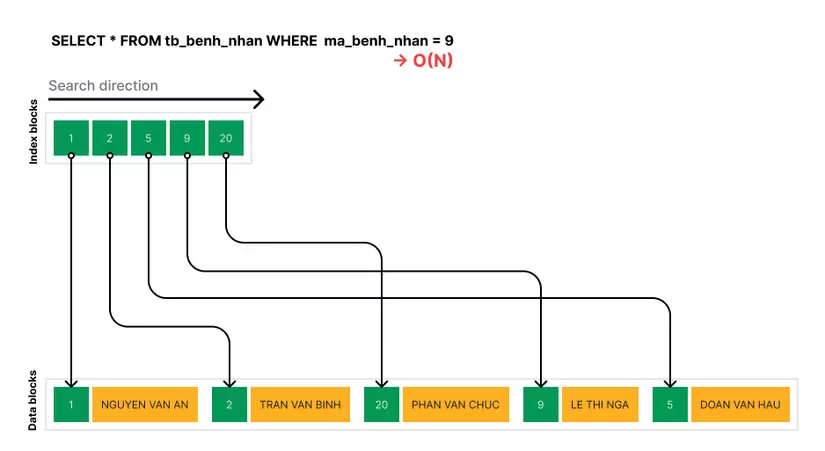
Nhưng một ngày A bệnh, A lết mãi mới được nửa vòng, A quyết định lần này là lần cuối, A đi hết 100 phòng, mỗi phòng A dừng lại và mapping thông tin bệnh nhân và số phòng vào một cuốn sổ cái.
Những lần tiếp theo, khi có yêu cầu, A chỉ cần giở cuốn sổ ra và trích ra danh sách phòng của từng bệnh nhân theo yêu cầu của bác sĩ.
Khi có bệnh nhân xuất viện hoặc nhập viện, A cập nhật lại trên cuốn sổ của mình, đảm bảo rằng thông tin trong cuốn sổ luôn chính xác.
Chỉ với một cuốn sổ nhỏ và một chút tỉ mỉ, công việc quản lý của A đã nhàn đi nhiều.
Rảnh rang được một thời gian, A được cất nhắc lên tuyến trên quản lý 10.000 giường bệnh. Rút kinh nghiệm, A chấp nhận đau một lần rồi thôi, A cũng lại đi thống kê toàn bộ vào cuốn sổ cái của mình, nhưng cuốn sổ của A chằng chịt toàn chữ, dày lên trông thấy. Mỗi lần bác sĩ đến khám, A dò 10.000 dòng trong cuốn sổ cái của mình. Chân A không còn đau nhưng mắt A bắt đầu nhoè dần sau 1 tuần làm việc.
Chia để trị
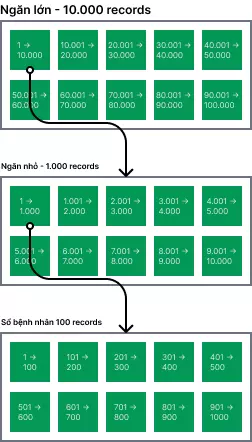
A thử chia cuốn sổ cái của mình thành 1.000 cuốn sổ nhỏ, mỗi cuốn 100 dòng, rồi chia theo dạng cây cân bằng vào giá sách có nhiều ngăn.
Các ngăn lớn ngoài cùng dán nhãn mã từ 1 -> 10.000, rồi tiếp tục từ 10.001 -> 20.000, tổng cộng có 10 ngăn.
Trong mỗi ngăn lớn lại chia thành 10 ngăn nhỏ, mã từ 1 -> 1.000, 1.001 -> 2.000, như vậy một ngăn chỉ còn có 10 cuốn sổ nhỏ mỗi cuốn 100 bệnh nhân.
Giả sử cần tìm bệnh nhân mã số = 1.890
- Ở ngăn lớn ngoài cùng, A so sánh 1 < 1.890 < 10.000, do đó A biết cần tìm trong ngăn này
- A tìm trong ngăn 1 -> 1.000, không thấy. Chuyển sang tìm trong ngăn có giá trị > 1.000, phát hiện ngăn con thoả mãn 1001 < 1890 < 2000.
- Ngăn trong cùng này có 10 cuốn mỗi cuốn 1.000 dòng, cuốn sổ cái thứ 9 lưu mã từ 1.801 -> 1.900 sẽ là cuốn sổ mà A cần tìm.
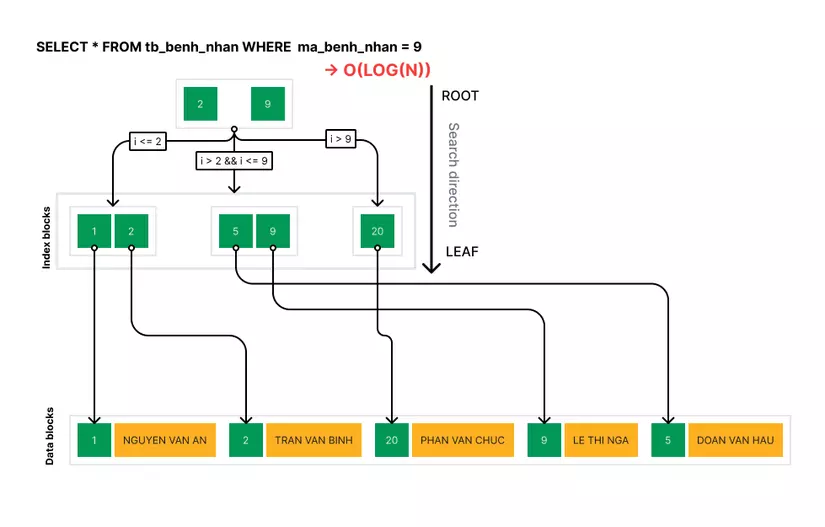
Chỉ cần 3 bước tìm kiếm, A tìm ra được phòng bệnh nhân mong muốn. Cuốn sổ cái trong ví dụ trên tương tự với khái niệm index trong các hệ cơ sở dữ liệu. Sử dụng một vùng nhớ nhỏ để lưu giá trị của column có tính đại diên, từ đó lấy được record tương ứng.
II. Index
Indexes are used to find rows with specific column values quickly. Without an index, MySQL must begin with the first row and then read through the entire table to find the relevant rows. The larger the table, the more this costs. If the table has an index for the columns in question, MySQL can quickly determine the position to seek to in the middle of the data file without having to look at all the data. This is much faster than reading every row sequentially.
Index là một cấu trúc dữ liệu giúp tăng tốc độ truy vấn và thao tác dữ liệu trong các bảng. Index được tạo trên một hoặc nhiều column và hoạt động như một cuốn sổ cái để tìm kiếm và truy xuất dữ liệu mà không cần quét toàn bộ bảng.
Dữ liệu càng lớn thì vai trò của index càng trở nên rõ ràng hơn.
1. Phân loại
Mysql hỗ trợ nhiều loại index đáp ứng các cách đánh chỉ mục khác nhau.
PRIMARY KEY
Primary key đảm bảo có thể xác định một record duy nhất.
- Non-nullable: không cho phép giá trị
NULL - Uniqueness: không chấp nhận giá trị trùng lặp
- Column được khai báo làm
PRIMARY KEYsẽ được tự động đánh index - Không thể khai báo 2
PRIMARY KEYtrong một table.
UNIQUE
Tương tự như PRIMARY KEY, UNIQUE đảm bảo các giá trị trong index là duy nhất.
Điều thú vị là UNIQUE index cho phép NULL và còn cho phép nhiều NULL values cùng tồn tại.
INDEX
Thoáng hơn cả 2 anh trên, loại index này cho phép null, cho phép giá trị trùng lặp. Không có ràng buộc gì đặt biệt.
FULLTEXT
Chỉ hỗ trợ các kiểu dữ liệu dạng chuỗi như CHAR, VARCHAR và TEXT, được sử dụng để thực hiện các truy vấn theo ngôn ngữ tự nhiên WHERE MATCH ... AGAINST.
Duy trì các index dạng này tốn nhiều tài nguyên hơn, đặc biệt với các bảng nhiều record và có index kích thước lớn. Trong một số trường hợp có thể áp dụng prefix index để giới hạn kích thước của index dạng chuỗi.
SPATIAL
Được thiết kế để hỗ trợ truy vấn cho dữ liệu không gian. Thực tế tôi cũng chưa được kinh qua món này nên chỉ để đây và không nói gì.
Multi-column index (Composite index)
Khác với các loại trên, index loại này cho phép đánh chỉ mục trên nhiều column. Giả sử tôi có 1 multi-column index (col1, col2, col3), index này cũng tương đương với index(col1), index(col1, col2), index(col1, col2, col3).
Ngoài ra, multi-column index còn có thể lấy giúp cải thiện hiệu suất của các câu lệnh ORDER BY, GROUP BY, MAX, MIN.
Covering index
Là một loại multi-column index khi toàn bộ các column trong câu lệnh SELECT cũng được đánh index cùng với các column dùng để tìm kiếm.
2. B-tree (Balanced Tree)
B-tree còn được gọi là cây tự cân bằng.
Cấu trúc dữ liệu này giải quyết giới hạn của Binary search tree (Cây tìm kiếm nhị phân), một node của B-tree có thể lưu nhiều giá trị cùng lúc rút ngắn chiều dài của cây.
Hầu hết các loại index của Mysql (PRIMARY KEY, UNIQUE, INDEX, FULLTEXT) đều sử dung B-tree.
Các đặc tính của B-tree bao gồm:
- Các node lá (leaf) luôn cùng cấp với nhau.
- Quy định giá trị minimum degree (T), là số giá trị tối thiểu của một node khi quyết định có sinh node mới hay không.
- Tất cả các node ngoại trừ root phải có ít nhất
T-1giá trị. - Tất cả các node bao gồm root node chỉ có thể có nhiều nhất
2T - 1giá trị. - Số node con của một node cha bất kỳ bằng số giá trị của node + 1.
- Tất cả các giá tị của node được sắp xếp theo thứ tự tăng dần. Con của k1 và k2 luôn có giá trị nằm trong khoảng k1 < child node < k2.
- Độ phức tạo của các thao tác cơ bản như
INSERT,DELETE,SELECTđều bằng nhau và bằng O(log(n))
III. Index optimization check list
Nên set index ở đâu
Để để trả lời câu hỏi này, anh em cần thống kê ra một danh sách các query đánh giá theo 2 tiêu chí tuần suất sử dụng và độ phức tạp của query. Trong danh sách này, lọc ra các column được sử dụng cho câu lệnh điều kiện. Sau khi xem xét các điều kiện trên anh em sẽ có 1 danh sách các column làm ứng viên để đánh chỉ mục. Việc tiếp theo là cân nhắc trong danh sách này column nào thực sự cần đánh index. Một số tiêu chí sau có thể giúp anh em lựa chọn index sao cho phù hợp.
Số lượng record phải đủ lớn
Độ hiệu quả của index tỉ lệ thuận với kích thước của bảng. Bảng có càng nhiều record thì càng cần phải cân nhắc set index cho các column thường được sử dụng cho câu lệnh điều kiện.
Lựa chọn column có tỉ lệ trùng lặp thấp
Nếu đang cân nhắc giữa nhiều column, hãy chọn column có tỉ lệ giá trị trùng lặp thấp. Thử tưởng tượng chỉ với 1 câu lệnh WHERE trên index column,anh em có thể lọc xuống còn 10 records trên tổng số 1 triệu record.
Ngược lại, nếu anh em set index cho column kiểu boolean (TINYINT(1)) chỉ chấp nhận 2 giá trị TRUE/FALSE trên hàng triệu record, index sẽ không tạo ra nhiều khác biệt. Lí tưởng nhất là tạo các index type = UNIQUE, 1 index tương đương với 1 record.
Lưu ý với column có tần suất thay đổi cao
Anh em biết rằng đánh index cho column có thể hiểu là tạo một vùng nhớ khác phục vụ việc mapping giữa column và record, điều này đồng nghĩa là Mysql phải quản lý vùng nhớ này khi có bất kì thao tác ghi liên quan (INSERT/UPDATE/DELETE).
Nếu column có tần suất thay đổi càng cao thì gánh nặng quản lý index càng tăng. Ví dụ nên đánh index trên những bảng theo cơ chế append only như bảng history với số lượng record nhiều và ít có thao tác DELETE/UPDATE một khi được khởi tạo.
Sử dụng prefix index cho các column dạng chuỗi
Thực tế việc set index cho các column chuỗi kích thước lớn không được khuyến khích, nhưng nếu cần phải set index cho trường hợp này anh em có thể áp dụng prefix index.
Thay vì set index cho nguyên column (đặc biệt là dạng chuỗi không có kích thước cố định như VARCHAR/TEXT) , anh em có thể set index cho n ký tự đầu tiên của chuỗi để cải thiện performance.
CREATE INDEX idx_prefix ON MY_TABLE(col1(3)); -- prefix index được set trên 3 ký tự đầu tiên của column col1 SELECT * FROM my_table WHERE col1 LIKE 'val%'; -- có sử dụng prefix
SELECT * FROM my_table WHERE col1 LIKE '%val'; -- không sử dụng prefix vì search like 3 phần tử cuối
SELECT * FROM my_table WHERE col1 = 'xx'; -- có sử dụng index vì 'xx' chỉ có 2 ký tự <= 3 ký tự của index Sử dụng multi-column index
Như đã chia sẻ ở trên, 1 multi column index tương đương với nhiều index con nên hãy tận dụng để gộp các index đơn lẻ nếu nó cũng là một phần của các query search trên nhiều column.
Ngoài các column được sử dụng làm điều kiện cho các câu lệnh WHERE, JOIN; query còn được hưởng lợi từ việc set multi-column index trong câu lệnh ORDER BY, GROUP BY, MIN, MAX.
CREATE INDEX col123 ON my_table(col1, col2, col3); SELECT * FROM my_table WHERE col1 = 1; -- Sử dụng index của col123 tương đương index(col1)
SELECT * FROM my_table WHERE col1 = 1 AND col2 = 'a'; -- Vẫn có thể sử dụng index của col123 tương đương index(col1, col2)
SELECT * FROM my_table WHERE col1 = 1 AND col2 = 'a' col3 = 'b'; -- Sử dụng index của col123
SELECT col1, col2 FROM my_table WHERE col1 = 1 ORDER BY col2; -- Sử dụng index của col123
Sử dụng covering index
Trong một số trường hợp, các column trong SELECT query cũng có thể được cân nhắc nếu có thể ứng dụng covering index.
Lúc này query truy vấn lấy dữ liệu trực tiếp từ vùng nhớ của index mà không cần ánh xạ sang record của bảng gốc.
CREATE INDEX idx_col1_col2 ON MY_TABLE(col1,col2); -- composite index được set trên column col1 và col2
SELECT col2 FROM my_table WHERE col1 = val; -- chỉ SELECT các giá trị có trong composite index
IV. Kết luận
Trên đây là một số gạch đầu dòng giúp anh em lập trình viên có một check list để set index sao cho hợp lý. Sau khi apply index mới, anh em nên tích cực theo dõi để đánh giá hiệu quả và phát hiện ngăn chặn sớm các side effect nếu có. Kỹ thuật đánh chỉ mục chỉ là một trong những cách để giúp tầng database có được performance tốt, còn rất nhiều phương pháp để tối ưu và mở rộng database tôi sẽ cùng anh em tìm hiểu thêm ở các bài sau.
"Use the right tool for the right job"
Nếu anh em cảm thấy bài viết hữu ích đừng ngần ngại click upvote cho bài viết, hoặc phát hiện ý nào chưa hợp lý hoặc cần giải thích thêm hãy comment cho tôi biết để cùng trao đổi nhé.
Anh em có thể tham khảo các bài viết khác của tôi tại Blog cái nhân hoặc kết nối với tôi qua Linkedin