
Đôi nét về tác giả.
Tôi là Trần An đến từ SmartLab FPT University, hiện thời khi viết bài viết này đang là sinh viên năm cuối và có 2 năm kinh nghiệm làm việc với AI cho robotics. Với kinh nghiệm làm và trải nghiệm qua sự đắng cay ngọt bùi của RL trong những lần làm xe tự hành hay điều khiển robots, thì tôi mong chuỗi series này có thể hỗ trợ các bạn trong việc học và làm việc với RL trong tương lai.
Các kiến thức cần có trước khi đọc bài viết.
Tôi không khuyến khích các bạn đọc bài viết này nếu các bạn chưa từng học các kiến thức sau đây (nếu chỉ đơn giản là muốn biết thì hãy enjoy):
- Kiến thức cơ bản về Machine Learning.
- Kiến thức cơ bản về Deep Learning.
- Toán (Rất nặng và nhiều toán).
- Xác xuất thống kê.
- Tiếng Anh (mức độ thông hiểu).
Nếu các bạn chưa có các kiến thức trên thì không sao cả, hãy ngồi xuống, uống miếng nước rồi xem qua lại những gì tôi liệt kê. Nếu không chặng đường sắp tới của chúng ta sẽ rất khó khăn đấy.
Sự đặc biệt của Reinforcement Learning.
Để dễ hình dung về RL (Reinforcement Learning) thì tôi sẽ lấy ví dụ đơn giản như sau.
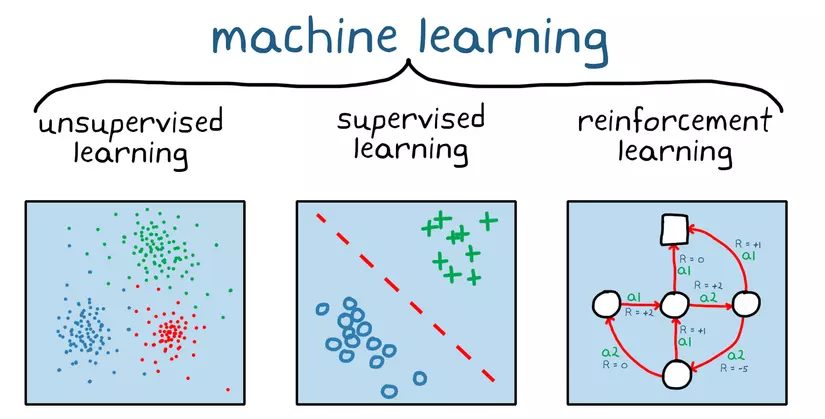
Bạn là một người bố và có một người con tên là AI, AI là một đứa con nhanh nhẹn và kháu khỉnh nên bạn quyết định là sẽ dạy học cho AI. Đầu tiên các bạn dạy toán cho AI, các bạn đưa một sấp tài liệu và đáp án cho AI và bảo rằng, trong mỗi một bài toán ở đây đều có kết quả chính xác của đáp án, con chỉ cần học đúng như tài liệu làm để ra được kết quả thôi. Phương pháp này được gọi là SL (supervised learning).
Lần này khác một chút, bạn dạy AI cách phân biệt sự khác nhau giữa đâu là con chó và con mèo, nhưng lần này bạn chỉ đưa cho một tập ảnh gồm ảnh chó và ảnh mèo, không hề có đáp án, AI phải phân cụm các bức ảnh chó sang một phần và ảnh mèo sang một phần. Phương pháp này được gọi là USL (unsupervied learning).
Cuối cùng bạn dạy AI kĩ năng sinh tồn trong rừng, nhưng khác với 2 lần trước bạn ngay lập tức quăng AI vào trong rừng với không một công cụ hỗ trợ, AI phải tìm mọi cách sống sót. Phương pháp này được gọi là RL.
Đây chính là phần đặc biệt nhất của RL mà tôi muốn nói đến, khi mà ta phải dạy cho AI cách làm thể nào để có thể hoạt động được trong môi trường thật. Theo như cuốn Reinforcement Learning: An Introduction của Sutton và Barto (nếu mọi người có nền toán và tiếng anh tốt tôi khuyến khích nên đọc quyển này để có góc nhìn toán hơn), đã nói rằng: "RL là một phương pháp học tập dựa trên sự tương tác giữa các chủ thể với nhau, về cách thức học tập của chủ thể học tập chính đưa ra quyết định dựa trên trạng thái hiện tại ảnh hưởng tới tương lai".
Reinforce.
Trước khi nói sâu hơn về RL, ta nên hiểu với nhau rằng chữ reinforce trong RL mang nghĩa là tăng cường, bổ sung, và bổ khuyết. Chính vì vậy mà ta cũng phải hiểu đây là một phương pháp dạy cho các model đã có thể hoạt động với mong muốn là nó có thể trở nên tốt hơn, mục đích của RL đến thời điểm hiện tại vẫn chưa phải là thay thế các phương pháp học như SL hay USL mà chỉ là một phương pháp được sinh ra nhằm bổ trợ mà thôi.
Reinforcement Learning cũng giống với các phương pháp học tập kết thúc bằng đuôi -ing khác, đây đều là chỉ các quá trình liên tục và có thể là vô hạn. Các vấn đề của RL được xây dựng và phát triển để có thể map các situations với actions với mục tiêu tối đa hoá các tín hiệu Rewards. Bằng một cách hiểu khác, RL là một phương pháp close-loop với các điều kiện:
- Không có hướng dẫn cụ thể.
- Gồm một chuỗi các hành động và rewards.
- Kết thúc với một điều kiện cụ thể.
Có một điều khác biệt khá lớn của RL đối với các phương pháp học phổ thông ngày nay, khi mà các thuật toán về SL hay USL đều phải dựa trên một tập dữ liệu cụ thể thì RL lại dựa trên interactions giữa các đối tượng với nhau. Điều này dẫn đến RL có thể tự phát triển với nhiều tình huống khác nhau mà không hoàn toàn bị phụ thuộc vào dữ liệu được cung cấp.
Một trong những thử thách lớn nhất của RL là sự trade-off giữa exploration và exploitation. Để có thể tối ưu được reward, agent cần phải đưa ra các lựa chọn trong việc sẽ tìm kiếm các hướng đi khác hay thử nghiệm các hướng đi cũ được cho là tốt. Nếu ta chỉ lựa chọn explore không thì agent sẽ không thể tìm được đâu mới là hướng đi tốt nhất còn chỉ chọn exploit sẽ giới hạn khả năng của agent. Đây được gọi là exploration-explotation dilemma, dilemma này đã được tìm hiểu và nghiên cứu cho đến tận thời điểm hiện tại và việc đưa ra một phương án cụ thể để cân bằng giữa exploration và exploitation vẫn đang là một vấn đề hóc búa.
Note: dilemma này không xuất hiện trong bài toán supervise hay unsupervise, ít nhất là trong trạng thái thuần chủng nhất.
Các thành phần trong Reinfocement Learning.
Trước khi nói đến Agent và Environment chúng ta sẽ nói về 4 thành phần chính trong hệ thông RL là:
- Policy (chính sách): policy được hiểu là hướng đi của agent trong một thời điểm cụ thể, nhìn sâu xa hơn thì policy chính là cách ta map giữa trạng thái hiện tại của môi trường với một hành động cụ thể. Trong tâm lý học đây được gọi là “Set of stimulus-respone rules of associations”. Trên thực tế, policy có thể là một phương trình cơ bản, có thể là một look-up table, với các trường hợp phức tạp hơn nó có thể là một chuỗi các quá trình tính toán phức tạp,… Trong RL, policy là một cách thức chủ quan để ta đánh giá behavior của agent.
- Reward (reward signal): Đây được đánh giá là mục tiêu của RL, với mỗi một step, môi trường sẽ trả về cho agent giá trị gọi là reward. Mục tiêu của agent sẽ là tối ưu hóa total reward trong một chuỗi các hành động (a long run). Với một góc nhìn tổng quan hơn, reward là một giá trị thể hiện sự tốt hoặc xấu của trạng thái môi trường hiện tại đối với agent. Đặt trong sinh học thì đây là trải nghiệm tốt hoặc xấu đối với một vấn đề. Trong thực tế, đây chỉ là trải nghiệm nhất thời và sẽ coi reward là thể hiện cho các trạng thái tức thì.
- Value Function: khác với reward, value function sẽ rất phù hợp với long run. Nói chính xác, value của một state là total amount of reward mà agent có thể đạt được tích lũy trong tương lai, bắt đầu từ state hiện tại. Khi mà reward được xác định là ngay lập tức thì value lại mang tính quyết định trong một tương lai xa hoặc gần. Điều này dẫn đến có thể có một state có reward low nhưng vẫn có value high. *Note: reward là giá trị cố định còn value sẽ phải estimate và re-estimate dựa trên các hành động mà agent đã đưa ra.
- Model of environment: Đây được coi là cách thức chúng ta sao chép lại các trạng thái của trường, thể hiện môi trường sẽ có behavior như thế nào. Với ví dụ khi ta có một cặp state và action, model sẽ đưa ra dự đoán về state tiếp theo nào reward nhận được. Model thường được sử dụng trong planning, do chúng ta cũng cần cân nhắc giữa việc thực hiện một hành động sẽ thay đổi trạng thái trong tương lai bằng cách cân nhắc giữa các state và reward dự đoán. Các phương pháp sử dụng model được gọi là model-base methods, ngược lại là model- free methods.
Đôi lời trước khi kết thúc.
Trước tiên tôi xin lỗi mọi người khi không dịch một vài cụm từ sang tiếng Việt mà để nguyên tiếng Anh, nguyên do là những câu này khi dịch sang tiếng Việt có thể làm mất nghĩa và không truyền tải được đầy đủ thông tin mà đáng nhẽ nó nên mang nên tôi mới đưa ra quyết định như vậy.
Bài viết này tạm thời tới đây thôi, nếu các bạn thực sự muốn tìm hiểu sâu về RL thì có thể ủng hộ bài viết này. thank you all.
refercences.
-
Ảnh trên google