Tại sao lại sử dụng GUID để làm primary key
Ưu điểm
- Độc lập với ngữ cảnh: GUID là một chuỗi số duy nhất, không phụ thuộc vào ngữ cảnh nào, do đó nó có thể được tạo ra mà không cần phải trông chờ vào cơ sở dữ liệu.
- Phân phối đồng đều: GUID được tạo ra để đảm bảo tính ngẫu nhiên và không trùng lặp trên toàn thế giới, do đó nó phân phối đều hơn so với các khóa tự tăng (auto-increment) trong môi trường phân tán.
- Bảo mật tương đối: GUID không dễ đoán được, điều này có thể mang lại một mức độ bảo mật tương đối khi so sánh với các khóa tự tăng.
- Tích hợp dễ dàng: GUID có thể được sử dụng với nhiều loại cơ sở dữ liệu và ngôn ngữ lập trình.
Nhược điểm
- Kích thước lớn: GUID có kích thước lớn hơn so với các khóa tự tăng, điều này có thể làm tăng kích thước của bảng và dẫn đến tăng tải cho cơ sở dữ liệu.
- Hiệu suất không tốt: Do kích thước lớn và tính không liên tục của GUID, việc sử dụng chúng làm khóa chính có thể ảnh hưởng đến hiệu suất của các truy vấn, đặc biệt là trong các bảng lớn.
- Khó đọc và nhớ: GUID là một chuỗi số ngẫu nhiên, không dễ đọc hoặc nhớ, điều này có thể làm cho việc thao tác với dữ liệu trở nên khó khăn hơn đối với con người.
- Cần tăng cường bảo mật: Mặc dù GUID khó đoán được, nhưng không có gì ngăn chặn việc sử dụng một GUID khác nhau từ phía người dùng, do đó cần phải cân nhắc vấn đề bảo mật cẩn thận hơn.
Ngoài ra, khi sử dụng GUID làm primary key, việc tạo index trên bảng sẽ gặp nhiều vấn đề bởi tính phân phối ngẫu nhiên của GUID.
Sequence GUID - một cứu tinh mới
Sequence GUID là một cách để tạo ra các GUID (Globally Unique Identifier) theo một trình tự cụ thể.
Thông thường, GUID được tạo ra thông qua các thuật toán đảm bảo tính ngẫu nhiên và độc lập của chúng. Tuy nhiên, trong một số trường hợp, đặc biệt là khi cần sắp xếp và lập trình logic theo thứ tự, việc tạo GUID theo một trình tự nhất định có thể hữu ích.
Sequence GUID thường được tạo ra bằng cách kết hợp các thành phần như timestamp, node ID, hoặc các yếu tố khác để đảm bảo tính duy nhất và tăng dần. Điều này giúp cho việc sắp xếp và quản lý dữ liệu dễ dàng hơn trong một số tình huống.
Trong SQL Server, chúng ta có thể tạo và sử dụng các Sequence GUID, vì nó được tạo theo một trình tự cụ thể nên giải quyết được các vấn đề về index, order by...vv
Entity Frameworks SequentialGuidValueGenerator cung cấp method để tạo sequential GUIDs cho SQL Server
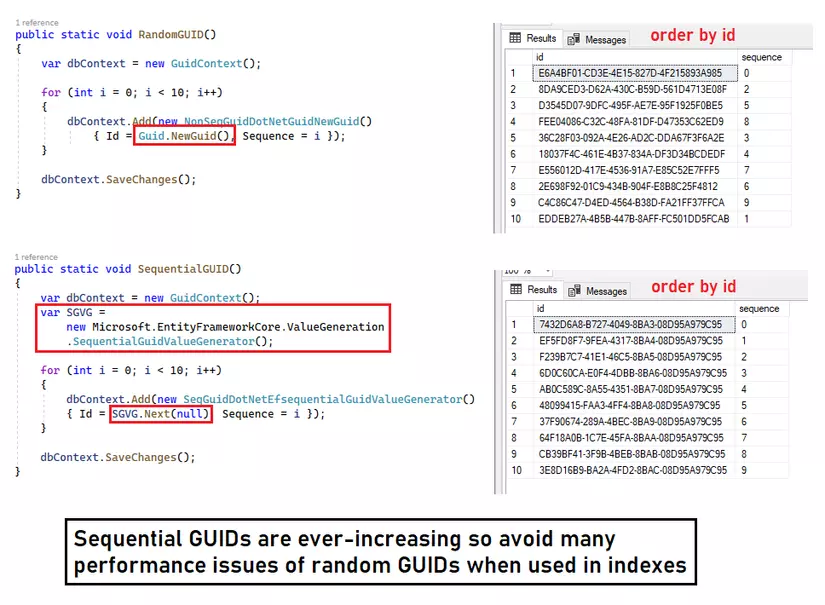
Với PostgreSQL thì sao ?
Và với tất cả những tính năng trên, một ngày đẹp trời sếp bảo team apply vào cho dự án hiện tại. Anh em rất phấn khởi vì idea này cũng hay, và khi apply vào thì lại không chạy, GUID vẫn gen ngẫu nhiên, vì sao thế ? Sau một hồi tìm hiểu thì có vẻ cơ chế của PostgreSQL không phù hợp với solution này, bởi vì Identifier của SQL Server làm việc rất tốt để sinh ra mã sequence GUID, nhưng PostgreSQL thì không. Và với yêu cầu của sếp, sau khi tìm hiểu thì có thể giải quyết được bằng việc sử dụng https://uuid7.com/ với các tiêu chí mà nó mang lại, đã khá ổn.
Benefits of UUIDv7:
- Time-Sortability: As mentioned, UUIDv7 values are time-sortable, which means you can sort them in increasing order based on when they were generated. This makes time-based queries more efficient and intuitive.
- Precise Timestamping: With a granularity of up to 50 nanoseconds as of previous drafts (but a default of 1 millisecond as of writing, see draft RFC4122), UUIDv7 offers excellent precision. This, when combined with the randomness, essentially guarantees that collisions (even among globally distributed systems!) are impossible.
- Global Uniqueness: Like other UUIDs, UUIDv7 ensures global uniqueness. This means you can generate IDs independently across different systems or nodes, and they won't collide.
Why UUIDv7 is Better for Databases:
- Natural Sorting: Traditional databases often require additional timestamp columns to sort records based on creation time. With UUIDv7, you can achieve this sorting using the UUID itself, eliminating the need for extra columns.
- Optimized Indexing: Since UUIDv7 is time-sortable, database indexing mechanisms can better optimize the storage and retrieval processes, leading to faster query times especially for time-based queries.
- Concurrency and Distribution: In distributed systems, generating unique, sequential IDs can be a challenge. UUIDv7 can be generated concurrently across multiple nodes without the risk of collisions, making it suitable for distributed architectures.
- Reduced Overhead: Unlike UUIDv1, which can expose the MAC address of the machine where the UUID was generated (raising privacy concerns), UUIDv7 doesn't have this drawback, reducing the overhead of obscuring or anonymizing this data.
- Flexibility: Databases that support binary storage can store UUIDv7 efficiently, and they can be easily encoded into other formats like strings if required.
Và, dự án của Team đang chạy là NET 8 + PostgreSQL, với PostgreSQL thì có cung cấp 1 extensions chính thống là : UUID-OSSP nhưng chỉ tạo được tới v5, vậy có vẻ chúng ta phải xử lý mã nguồn 1 chút để apply V7 vào.
Dưới đây là cách thức refactor của mình cho dự án
Sử dụng UUID-Extensions package trên Nuget để sinh ra mã UUID v7 Khai báo trong hàm khởi tạo của BaseEntity, để đảm bảo khi dev sử dụng cú pháp Object-Initialized thì không can thiệp vào Id
public virtual Guid Id { get; private set; } public BaseEntity() { var guid = Uuid7.Guid(); this.Id = guid; }
public void SetId()
{ this.Id = Uuid7.Guid();
}
Khai báo tầm vực cho biến Id là private set, chỉ chấp nhận thay đổi Id trong hàm khởi tạo hoặc setter, không chấp nhận truyền id từ bên ngoài
Để ngăn chặn việc PostgreSQL tự tạo GUID cho rows, dẫn đến mất ưu điểm của V7, ta sẽ override lại SaveChangesAsync() và thực hiện validate Id
public override int SaveChanges(bool acceptAllChangesOnSuccess)
{ AddSequenceGuid(); return base.SaveChanges(acceptAllChangesOnSuccess);
} private void AddSequenceGuid()
{ var entities = ChangeTracker.Entries().Where(x => x.State == EntityState.Added && x.Entity is BaseEntity); foreach (var entityEntry in entities) { var entity = (BaseEntity)entityEntry.Entity; if (UuidHelper.ValidateUuidV7(entity.Id) is false) { entity.SetId(); } }
}
public static class UuidHelper
{ private static readonly System.Text.RegularExpressions.Regex Uuid7Re = new System.Text.RegularExpressions.Regex(@"^[0-9a-f]{8}-[0-9a-f]{4}-7[0-9a-f]{3}-[89ab][0-9a-f]{3}-[0-9a-f]{12}$", RegexOptions.IgnoreCase); public static DateTime ParseUuid7Date(string uuid) { if (uuid == null || !Uuid7Re.IsMatch(uuid)) { throw new ArgumentException($"Expected UUIDv7. Received: {uuid ?? "null"}"); } string timestampHex = uuid.Substring(0, 13).Replace("-", ""); long timestamp = Convert.ToInt64(timestampHex, 16); return DateTimeOffset.FromUnixTimeMilliseconds(timestamp).UtcDateTime; } public static bool ValidateUuidV7(string uuid) { try { var result = ParseUuid7Date(uuid); return true; } catch { return false; } } public static bool ValidateUuidV7(Guid uuid) { try { var result = ParseUuid7Date(uuid.ToString()); return true; } catch { return false; } }
}
Chúng ta cần kiểm tra trường Id đã chuẩn UUID V7 chưa, nếu chưa thì cần set lại cho nó, trong trường hợp nó đang là Guid.Empty
Như vậy, chúng ta đã có thể sử dụng được UUID V7 như một Sequence GUID trong PostgreSQL và kế thừa được các ưu điểm như trên.