Xin chào mọi người.
Khi chúng ta đếm các bản ghi trong bảng dữ liệu, chúng ta đã quen với việc sử dụng hàm count để đếm, nhưng có nhiều loại tham số có thể được truyền trong hàm count, chẳng hạn như count(1), count(), count(column), …
Vậy sử dụng cái nào là hiệu quả nhất? Có phải là count(*) sẽ kém hiệu quả nhất không?
Mọi người thường nhận định count(*) là kém hiệu quả nhất và cho rằng nó sẽ đọc tất cả các trường trong bảng, giống như câu query SELECT * FROM. Điều này có thực sự đúng không, chúng ta hãy tìm hiểu bên dưới nhé.
Câu lệnh count nào sẽ có hiệu suất tốt nhất?
Chúng ta sẽ bắt đầu với kết luận trước:
coun(*) = count(1) > count(primary key column) > count(column)
Để hiểu điều này, chúng ta cần đi sâu vào nguyên tắc hoạt cộng của hàm count() nhé. Trước khi đi tiếp, chúng ta cùng thống nhất ngữ cảnh của bài viết:
- Database: MySQL
- Store Engine: InnoDB
Count() là gì?
Count(arg) là một hàm tổng hợp, tham số của hàm là một trường, một hằng số hoặc một biểu thức. Hàm được sử dụng để đếm số lượng bản ghi đáp ứng điều kiện truy vấn và tham số trong hàm count(arg) có giá trị khác null.
Giả sử đối số hàm count là một trường như sau:
select count(name) from member;
Câu lệnh này là để đếm số lượng bản ghi trong bảng member với trường name không phải là null. Nói cách khác, nếu giá trị của trường name trong bản ghi là null, nó sẽ không được tính.
Giả sử rằng tham số của hàm count() là hằng số 1, như sau:
select count(1) from member;
Tất nhiên 1 thì luôn khácnull rồi, vì vậy câu lệnh trên thực sự đang đếm có bao nhiêu bản ghi trong bảng member.
Để hiểu rõ hơn, sau đây chúng ta cùng tìm hiểu các cơ chế hoạt động và chiến lược thực thi của hàm count nhé.
Count(primary key) hoạt động như thế nào?
Khi chúng ta đếm có bao nhiêu bản ghi thông qua hàm count(arg), lúc này MySQL duy trì một biến gọi là count và đọc các record trong một lần duyệt. Nếu giá trị arg trong hàm count khác null, nó sẽ cộng thêm 1 vào biến count cho đến khi tất cả các bản ghi được duyệt và sau đó thoát khỏi lượt duyệt đó. Cuối cùng, gửi giá trị của biến count cho client.
Như chúng ta biết rằng sẽ có hai loại index là clustered index và secondary index. Sự khác biệt giữa chúng là các nút lá của clustered index lưu trữ dữ liệu thực tế, trong khi các nút lá của secondary index chỉ lưu trữ giá trị khóa chính thay vì dữ liệu của bản ghi. Mặc định clustered index sẽ được tự động tạo khi chúng ta tạo primary key và InnoDB sẽ lưu các bản ghi ở các nút lá của cây B+ Tree.
Lấy câu lệnh sau đây làm ví dụ:
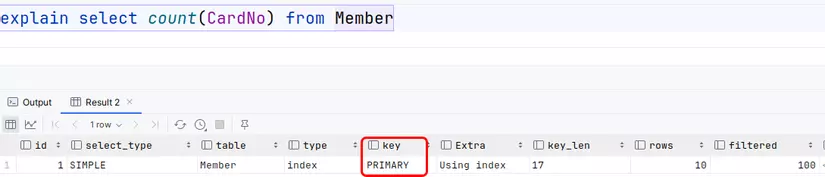
select count(CardNo) from member;
Nếu bảng chỉ có clustered index, InnoDB sẽ duyệt trên clustered index, đọc từng bản ghi. Mỗi bản ghi, InnoDB đọc giá trị primary key để so sánh với null. Nếu nó khác null, biến count sẽ được cộng thêm 1.
Ví dụ trường hợp khác, Phone_No là khoá chính và có tồn tại 1 second index trên (Phone_No, Name) trên bảng Member.
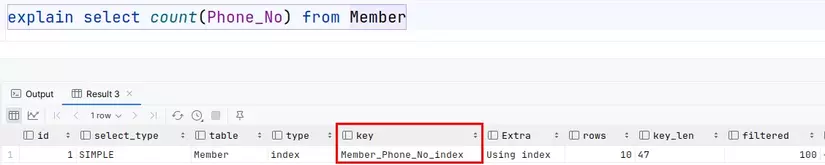
Nếu có một secondary index trong bảng, InnoDB sẽ không duyệt clustered index, mà duyệt secondary index. Lý do là secondary index có thể chiếm ít dung lượng lưu trữ hơn so với clustered index => cây secondary index nhỏ hơn cây clustered index => chi phí I/O khi scan second index thấp hơn so với việc scan clustered index. Vì vậy optimizer ưu tiên dùng secondary index hơn.
Count(1) hoạt động như thế nào?
Tham số của hàm count là 1 rõ ràng không phải là cột, cũng không phải null. Vậy count(1) sẽ hoạt động thế nào?
Ví dụ:
select count(1) from member;
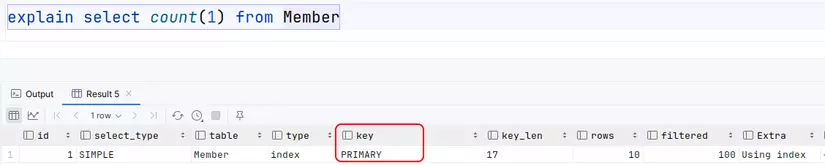
Trong trường hợp chỉ có clustered index và không có secondary index, InnoDB duyệt clustered index để đếm bản ghi, nhưng nó chỉ duyệt bản ghi, chứ không cần đọc lấy giá trị của bản ghi. Vì việc có bản ghi được xem là khác null.
Chúng ta có thể thấy, Count(1) sẽ nhanh hơn Count(primary key column), vì nó không cần đọc giá trị bản ghi để so sánh với null.
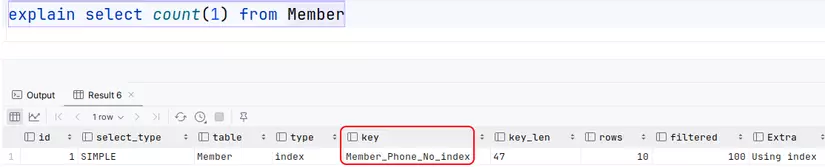
Tuy nhiên, nếu có một secondary index trong bảng, InnoDB sẽ duyệt secondary index trước.
Count(*) hoạt động như thế nào?
Khi bạn nhìn thấy ký tự *, bạn có nghĩ rằng nó đang đọc tất cả các giá trị trường trong bản ghi không?
Nó sẽ đúng trong trường hợp select *, còn count(*) thì không nhé.
Khi chúng ta gọi count(*), MySQL sẽ chuyển đổi tham số thành count(0).
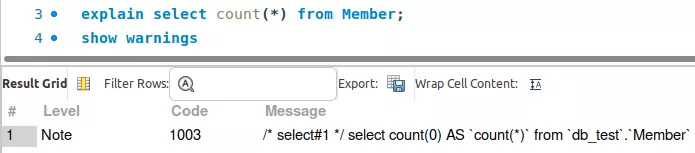
Do đó, quá trình thực thi count(*) giống hệt count(1) và không có sự khác biệt về hiệu suất.
Count(column) hoạt động như thế nào?
Count(column) có hiệu năng kém nhất so với count(1), count(*) và count(primary key column).
Ta có ví dụ sau:
select count(name) from member;
Đối với truy vấn này, MySQL quét toàn bộ bảng để đếm, vì vậy hiệu quả thực thi của nó tương đối kém.
Trong trường hợp column có secondary index thì câu lệnh sẽ sử dụng index để duyệt, từ đó tốc độ sẽ được cải thiện.
Tóm tắt ngắn gọn
coun(*) = count(1) > count(primary key column) > count(column)
Đối với Count(1), count(*) và count(primary key column), nếu có secondary index trong bảng, MySQL sẽ chọn secondary index để scan.
Do đó, nếu bạn muốn thực thi count(1), count(*) và count(primary key column), hãy thử tạo secondary index trên bảng dữ liệu, MySQL sẽ tự động sử dụng secondary index để scan, vì nó hiệu quả hơn so khi scan với primary index.
Một lần nữa, không nên sử dụng count(column) để đếm số lượng bản ghi, vì nó kém hiệu quả nhất và sẽ sử dụng phương pháp scan toàn bộ bảng để đếm. Nếu bạn phải đếm số lượng bản ghi trong bảng có cột không phải là null, bạn nên tạo secondary index cho cột này.
Tại sao count lại phải duyệt các bản ghi?
Storage Engine khác count(*) như nào?
Bạn có thể tự hỏi tại sao hàm count() cần phải duyệt qua các bản ghi?
Từ đầu bài, mình chỉ đề cập tới storage engine InnoDB, tuy nhiên các storage engine khác nhau có thể có cách thực thi hàm count khác nhau. Ví dụ như MyISAM, 1 storage engine khác của MySQL, phổ biến thứ 2 sau InnoDB.
Trong trường hợp sử dụng MyISAM, mỗi bảng sẽ có metadata chứa giá trị row_count. Như vậy khi cần đếm tất cả bản ghi trong bảng (count() không có điều kiện lọc), MyISAM chỉ cần đọc giá trị row_count với độ phức tạp O(1).
Khi count() có điều kiện lọc thì MyISAM và InnoDB hoạt động không khác gì nhau. Cả hai đều cần scan bảng để đếm số bản ghi phù hợp.
*Lưu ý, khi đọc lấy row_count, MyISAM lock bảng để đảm bảo tính nhất quán của giá trị này.
Count trong transaction hoạt động như nào?
Storage engine InnoDB hỗ trợ transaction, nhiều transaction có thể thực cùng lúc. Cơ chế MVCC (multi-version concurrency control) và Isolation có thể ảnh hưởng tới kết quả count().
Ví dụ: bảng member có 100 bản ghi. Và có 2 sesssion thực hiện song song và các query được thực hiện theo thứ tự sau:
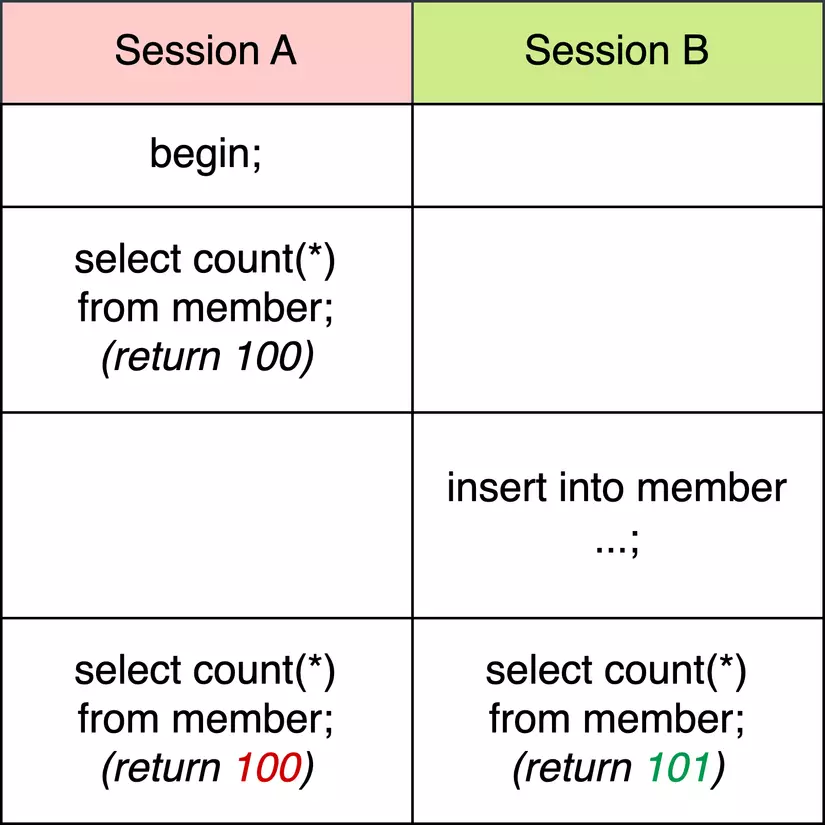
Ở cuối session A và B, ta kiểm tra tổng số bản ghi trong bảng member cùng một lúc nhưng bạn có thể thấy rằng kết quả hiển thị là khác nhau. Do mặc định isolation level của transaction A là repeatable nên count(*) thứ 2 sẽ lặp kết quả là 100.
InnoDB cần duyệt các bản ghi và dữ liệu trong undo logs để đảm bảo tính isolation của transaction. Các bạn có thể đọc thêm về MVCC và tính isolation nhé.
Làm cách nào để tối ưu count(*)?
Nếu bạn thường xuyên sử dụng count(*) cho một table lớn thì đó không phải giải pháp tốt.
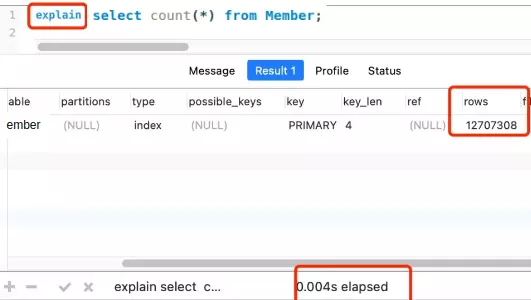
Ví dụ bảng member có tổng cộng 12+ triệu bản ghi, và mình cũng đã tạo một secondary index, nhưng phải mất khoảng 5 giây để thực thi một lần: select count(*) from member
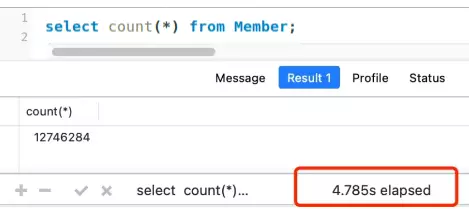
Vậy có cách nào tốt hơn để làm điều này khi đối mặt với một bảng lớn không?
Lấy giá trị xấp xỉ
Nếu bạn không cần phải rất chính xác về số lượng thống kê, ví dụ: khi công cụ tìm kiếm tìm kiếm từ khóa, số lượng kết quả tìm kiếm được đưa ra là một giá trị gần đúng.
Trong trường hợp này, chúng ta có thể sử dụng lệnh explain để ước tính bảng. Lệnh EXPLAIN (không đi kèm tham số ANALYZE) rất hiệu quả vì nó không thực sự truy vấn.
Tạo một bảng để lưu giá trị biến count
Nếu muốn lấy tổng số bản ghi chính xác trong một bảng, ta có thể lưu giá trị đếm này vào một bảng đếm riêng biệt. Khi thêm một bản ghi vào bảng dữ liệu, ta tăng trường count lên 1 và khi xóa một bản ghi thì giảm số lượng trường count xuống 1.
Tổng kết
Cuối cùng, chúng ta cần nhớ vài điểm quan trọng sau đây:
- Count(*) có hiệu năng tốt hơn so với Count(pk), count(column)
- Hàm count sử dụng ưu tiên sử dụng secondary index để thực hiện đếm.
- Nếu trường hợp không cần số liệu chính xác, hãy lấy giá trị xấp xỉ.
Hẹn gặp lại các bạn trong các bài viết tiếp theo.
Nếu mọi người thấy hay thì cho mình xin 1 upvote 🔼 và share nhé.
Cám ơn mọi người rất nhiều 🙏
🧑💻 70+ Ronin Engineers: https://ronin-engineer.github.io/c1/
📚️ System Design VN: https://fb.com/groups/systemdesign.vn