Giới thiệu
Trước khi Google công bố bài báo về Transformers (Attention Is All You Need), hầu hết các tác vụ xử lý ngôn ngữ tự nhiên, đặc biệt là dịch máy (Machine Translation) sử dụng kiến trúc Recurrent Neural Networks (RNNs). Điểm yếu của phương pháp này là rất khó bắt được sự phụ thuộc xa giữa các từ trong câu và tốc độ huấn luyện chậm do phải xử lý input tuần tự. Transformers sinh ra để giải quyết 2 vấn đề này; và các biến thể của nó như BERT, GPT-2 tạo ra state-of-the-art mới cho các tác vụ liên quan đến NLP. Các bạn có thể tham khao thêm bài viết BERT- bước đột phá mới trong công nghệ xử lý ngôn ngữ tự nhiên của Google của tác giả Phạm Hữu Quang để hiểu thêm về BERT nhé. 
Mô hình Sequence-to-Sequence sử dụng RNNs

Mô hình Sequence-to-Sequence nhận input là một sequence và trả lại output cũng là một sequence. Ví dụ bài toán Q&A, input là câu hỏi "how are you ?" và output là câu trả lời "I am good". Phương pháp truyền thống sử dụng RNNs cho cả encoder (phần mã hóa input) và decoder (phần giải mã input và đưa ra output tương ứng). Điểm yếu thứ nhất của RNNs là thời gian train rất chậm, đến mức người ta phải sử dụng phiên bản Truncated Backpropagation để train nó. Mặc dù vậy, tốc độ train vẫn rất chậm do phải sử dụng CPU, không tận dụng được tính toán song song trên GPU.

Điểm yếu thứ hai là nó xử lý không tốt với những câu dài do hiện tượng Gradient Vanishing/Exploding. Khi số lượng units càng lớn, gradient giảm dần ở các units cuối do công thức Đạo hàm chuỗi, dẫn đến mất thông tin/sự phụ thuộc xa giữa các units.

Ra đời năm 1991, Long-short Term Memory (LSTM) cell là một biến thể của RNNs nhằm giải quyết vấn đề Gradient Vanishing trên RNNs. LSTM cell có thêm một nhánh C cho phép toàn bộ thông tin đi qua cell, giúp duy trì thông tin cho những câu dài.
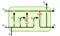
Có vẻ chúng ta đã giải quyết phần nào vẫn đề Gradient Vanishing, nhưng LSTM lại phức tạp hơn RNNs rất nhiều, và hiển nhiên nó cũng train chậm hơn RNN đáng kể
Vậy có cách nào tận dụng khả năng tính toán song song của GPU để tăng tốc độ train cho các mô hình ngôn ngữ, đồng thời khắc phục điểm yếu xử lý câu dài không? Transformers chính là câu trả lời 
Transformers
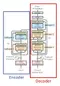
Kiến trúc Transformers cũng sử dụng 2 phần Encoder và Decoder khá giống RNNs. Điểm khác biệt là input được đẩy vào cùng một lúc. Đúng vậy đó, cùng một lúc; và sẽ không còn khái niệm timestep trong Transformers nữa. Vậy cơ chế nào đã thay thế cho sự "recurrent" của RNNs? Đó chính là Self-Attention, và đó cũng là lý do tên paper là "Attention Is All You Need" (fun fact: Tên này đặt theo bộ phim "Love is all you need"  ). Giờ chúng ta cùng đi vào từng thành phần một nhé
). Giờ chúng ta cùng đi vào từng thành phần một nhé
Encoder
1. Input Embedding
Máy tính không hiểu câu chữ mà chỉ đọc được số, vector, ma trận; vì vậy ta phải biểu diễn câu chữ dưới dạng vector, gọi là input embedding. Điều này đảm bảo các từ gần nghĩa có vector gần giống nhau. Hiện đã có khá nhiều pretrained word embeddings như GloVe, Fasttext, gensim Word2Vec,... cho bạn lựa chọn.

2. Positional Encoding
Word embeddings phần nào cho giúp ta biểu diễn ngữ nghĩa của một từ, tuy nhiên cùng một từ ở vị trí khác nhau của câu lại mang ý nghĩa khác nhau. Đó là lý do Transformers có thêm một phần Positional Encoding để inject thêm thông tin về vị trí của một từ
Trong đó là vị trí của từ trong câu, PE là giá trị phần tử thứ trong embeddings có độ dài . Sau đó ta cộng PE vector và Embedding vector:

3. Self-Attention
Self-Attention là cơ chế giúp Transformers "hiểu" được sự liên quan giữa các từ trong một câu. Ví dụ như từ "kicked" trong câu "I kicked the ball" (tôi đã đá quả bóng) liên quan như thế nào đến các từ khác? Rõ ràng nó liên quan mật thiết đến từ "I" (chủ ngữ), "kicked" là chính nó lên sẽ luôn "liên quan mạnh" và "ball" (vị ngữ). Ngoài ra từ "the" là giới từ nên sự liên kết với từ "kicked" gần như không có. Vậy Self-Attention trích xuất những sự "liên quan" này như thế nào?
Quay trở lại với kiến trúc tổng thể ở trên, các bạn có thể thấy đầu vào của các module Multi-head Attention (bản chất là Self-Attention) có 3 mũi tên, đó chính là 3 vectors Querys (Q), Keys (K) và Values (V). Từ 3 vectors này, ta sẽ tính vector attention Z cho một từ theo công thức sau:
Công thức này khá đơn giản, nó được thực hiện như sau. Đầu tiên, để có được 3 vectors Q, K, V, input embeddings được nhân với 3 ma trận trọng số tương ứng (được tune trong quá trình huấn luyện) WQ, WK, WV.

Lúc này, vector K đóng vai trò như một khóa đại diện cho từ, và Q sẽ truy vấn đến các vector K của các từ trong câu bằng cách nhân chập với những vector này. Mục đích của phép nhân chập để tính toán độ liên quan giữa các từ với nhau. Theo đó, 2 từ liên quan đến nhau sẽ có "Score" lớn và ngược lại.
Bước thứ 2 là bước "Scale", đơn giản chỉ là chia "Score" cho căn bậc hai của số chiều của Q/K/V (trong hình chia 8 vì Q/K/V là 64-D vectors). Việc này giúp cho giá trị "Score" không phụ thuộc vào độ dài của vector Q/K/V
Bước thứ 3 là softmax các kết quả vừa rồi để đạt được một phân bố xác suất trên các từ.
Bước thứ 4 ta nhân phân bố xác suất đó với vector V để loại bỏ những từ không cần thiết (xác suất nhỏ) và giữ lại những từ quan trọng (xác suất lớn).
Ở bước cuối cùng, các vectors V (đã được nhân với softmax output) cộng lại với nhau, tạo ra vector attention Z cho một từ. Lặp lại quá trình trên cho tất cả các từ ta được ma trận attention cho 1 câu.

4. Multi-head Attention
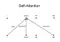
Vấn đề của Self-attention là attention của một từ sẽ luôn "chú ý" vào chính nó. Điều này rất hợp lý thôi vì rõ ràng "nó" phải liên quan đến "nó" nhiều nhất  . Ví dụ như sau:
. Ví dụ như sau:

Nhưng chúng ta không mong muốn điều này, cái ta muốn là sự tương tác giữa các từ KHÁC NHAU trong câu. Tác giả đã giới thiệu một phiên bản nâng cấp hơn của Self-attention là Multi-head attention. Ý tưởng rất đơn giản là thay vì sử dụng 1 Self-attention (1 head) thì ta sử dụng nhiều Attention khác nhau (multi-head) và biết đâu mỗi Attention sẽ chú ý đến một phần khác nhau trong câu 
Vì mỗi "head" sẽ cho ra một ma trận attention riêng nên ta phải concat các ma trận này và nhân với ma trận trọng số WO để ra một ma trận attention duy nhất (weighted sum). Và tất nhiên, ma trận trọng số này cũng được tune trong khi training.

5. Residuals
Các bạn có thể thấy trong mô hình tổng quan ở trên, mỗi sub-layer đều là một residual block. Cũng giống như residual blocks trong Computer Vision, skip connections trong Transformers cho phép thông tin đi qua sub-layer trực tiếp. Thông tin này (x) được cộng với attention (z) của nó và thực hiện Layer Normalization.
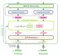
6. Feed Forward
Sau khi được Normalize, các vectors được đưa qua mạng fully connected trước khi đẩy qua Decoder. Vì các vectors này không phụ thuộc vào nhau nên ta có thể tận dụng được tính toán song song cho cả câu.

Decoder
1. Masked Multi-head Attention
Giả sử bạn muốn Transformers thực hiện bài toán English-France translation, thì công việc của Decoder là giải mã thông tin từ Encoder và sinh ra từng từ tiếng Pháp dựa trên NHỮNG TỪ TRƯỚC ĐÓ. Vậy nên, nếu ta sử dụng Multi-head attention trên cả câu như ở Encoder, Decoder sẽ "thấy" luôn từ tiếp theo mà nó cần dịch. Để ngăn điều đó, khi Decoder dịch đến từ thứ , phần sau của câu tiếng Pháp sẽ bị che lại (masked) và Decoder chỉ được phép "nhìn" thấy phần nó đã dịch trước đó.

2. Quá trình decode
Quá trình decode về cơ bản là giống với encode, chỉ khác là Decoder decode từng từ một và input của Decoder (câu tiếng Pháp) bị masked. Sau khi masked input đưa qua sub-layer #1 của Decoder, nó sẽ không nhân với 3 ma trận trọng số để tạo ra Q, K, V nữa mà chỉ nhân với 1 ma trận trọng số WQ. K và V được lấy từ Encoder cùng với Q từ Masked multi-head attention đưa vào sub-layer #2 và #3 tương tự như Encoder. Cuối cùng, các vector được đẩy vào lớp Linear (là 1 mạng Fully Connected) theo sau bới Softmax để cho ra xác suất của từ tiếp theo.
Hai hình dưới đây mô tả trực quan quá trình Transformers encode và decode
Encoding:

Decoding:

Kết luận
Trên đây mình đã giới thiệu với các bạn về mô hình Transformers - một mô hình mà mình thấy rất hay và đáng để tìm hiểu. Hiện giờ Transformers, các biến thể của nó, cùng với pretrained models đã được tích hợp trong rất nhiều packages hỗ trợ tensorflow, keras và pytorch. Tuy nhiên nếu bạn muốn implement từ đầu thì có thể tham khảo hướng dẫn rất chi tiết Transformer model for language understanding của tensorflow.
Tài liệu tham khảo:
[1] The Illustrated Transformer
[2] Transformer Neural Networks - EXPLAINED! (Attention is all you need)