Giới thiệu
Trong bài viết này chúng ta sẽ xây dựng một luồng tiếp nhận và xử lý dữ liệu live với Apache kafka và Apache Flink. Trước khi đi sâu hơn về cách thức hoạt động thì mình sẽ nói qua một chút về những khái niệm chính những công nghệ chúng ta sẽ dùng trong bài viết này.
Luồng dữ liệu (data streaming) là gì ?
Data streaming là dữ liệu được tạo ra từ nhiều nguồn dữ liệu khác nhau. Cho dễ hình dung thì nó rất giống với dòng chảy trên sông, dòng nước được chảy liên tục và cũng được hình thành từ nhiều nguồn khác nhau như mưa, suối và hồ...
Có 2 dạng luồng dữ liệu:
- Bounded Streams - Luồng yêu cầu có điểm đầu và điểm cuối. Dữ liệu trong luồng sẽ được tập hợp tại điểm cuối rồi mới được xử lý một lượt. Quá trình xử lý này được gọi là Batch Processing.
- Unbounded Streams - Luồng chỉ cần điểm bắt đầu nhưng không có điểm kết thúc, thay vì tập hợp dữ liệu rồi mới xử lý thì dữ liệu trong luồng sẽ được tiếp nhận và xử lý một cách liên tục. Quá trình này là Real-time Proccessing
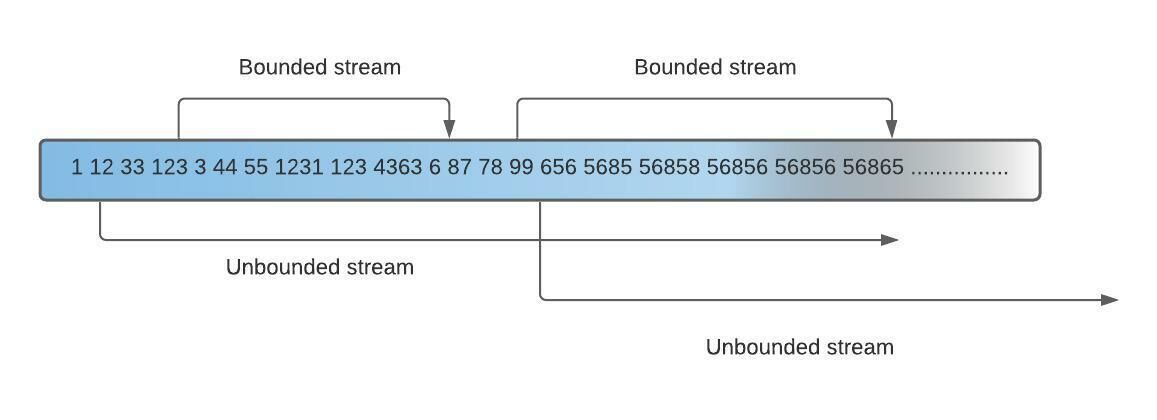
Trong nội dung bài viết, chúng ta tập trung vào Unbounded Streams. Do đó luồng dữ liệu sẽ bao gồm 2 microservice - một Kafka producer sẽ tạo ra dòng dữ liệu liên tục, cái còn lại là một cosumer tiếp nhận dòng dữ liệu đó và đẩy nó lên Flink thực hiện tính toán, biến đổi dòng dữ liệu đó thành 1 dòng dữ liệu khác.
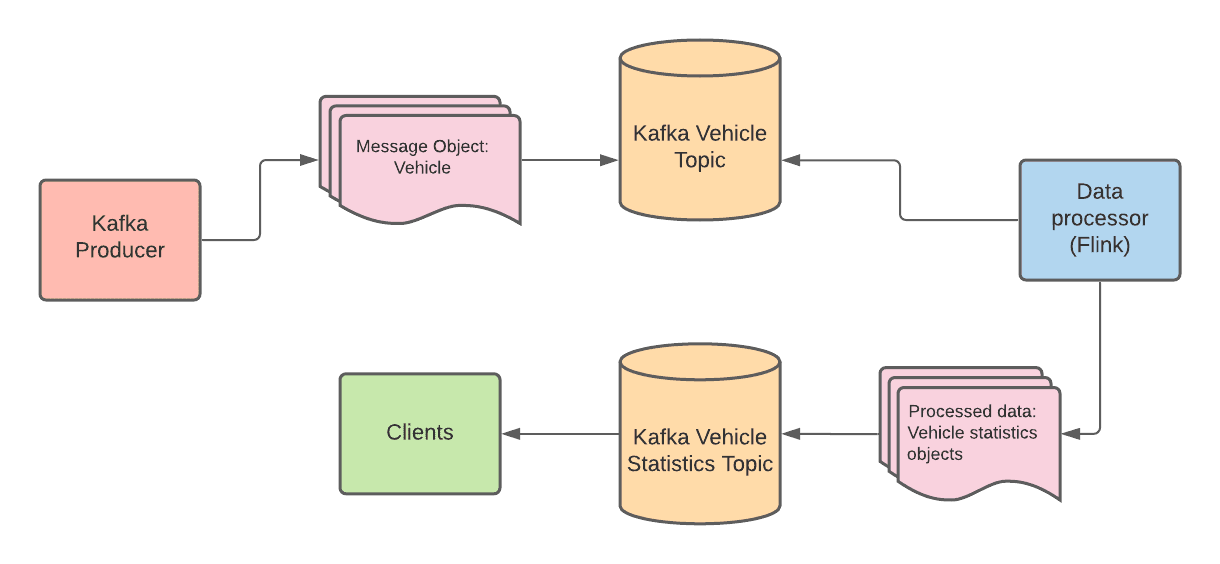
Trước khi bắt đầu code, cùng nhau tìm hiểu những công nghệ chính chúng ta sẽ sử dụng
Apache Kafka
Apache Kafka là một nền tảng phân tán luồng dữ liệu được phát triển bởi Apache Software Foundation. Nền tảng này được dùng để:
- Publish và subscribe đến luồng sự kiện
- Lưu trữ luồng sự kiện với tính an toán và độ tin cậy cao
- Xử lý luồng sự kiện ngay khi chúng xuất hiện
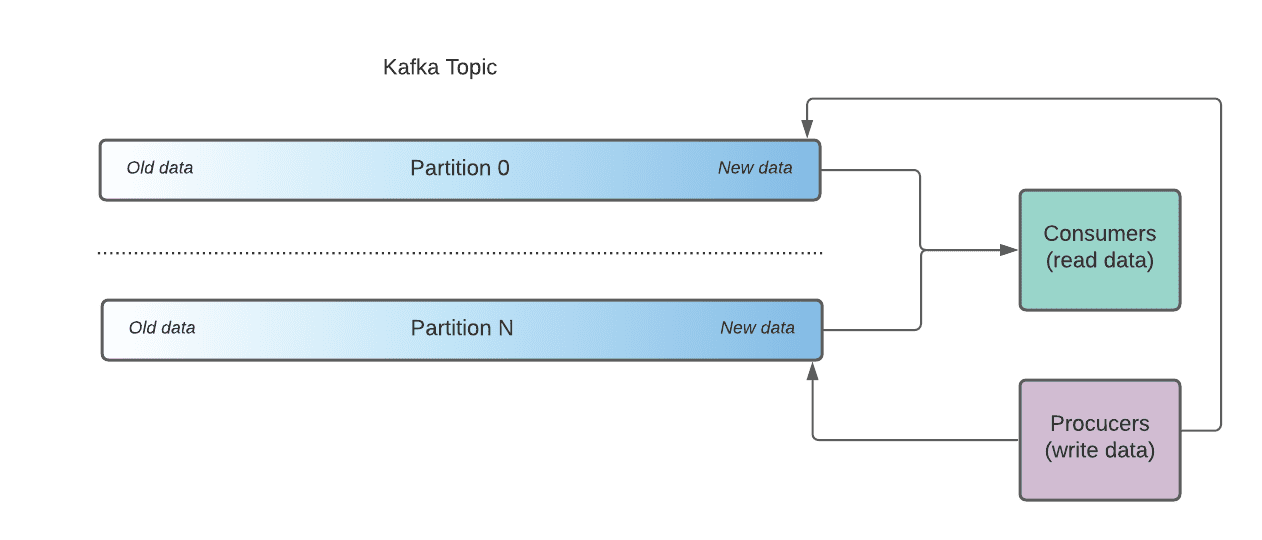
Nói tóm tắt thì Kafka sử dụng Topics để phân loại sự kiện(events)/ tin nhắn(messages). Các Topics được chia thành nhiều các Partitions được phân bố đều trong Kafka và có thể được truy cập cùng lúc bởi nhiều consumsers.
Apache Flink
Apache Flink là một framework dùng để xử lý luồng dữ liệu từ bounded streams và unbounded streams. Nó có thể chạy hầu hết trên mọi môi trường cluster phổ biến hiện nay (Kubernetes, YARN,...) và thực hiện tính toán luồng dữ liệu với tốc độ rất nhanh
Streaming windows
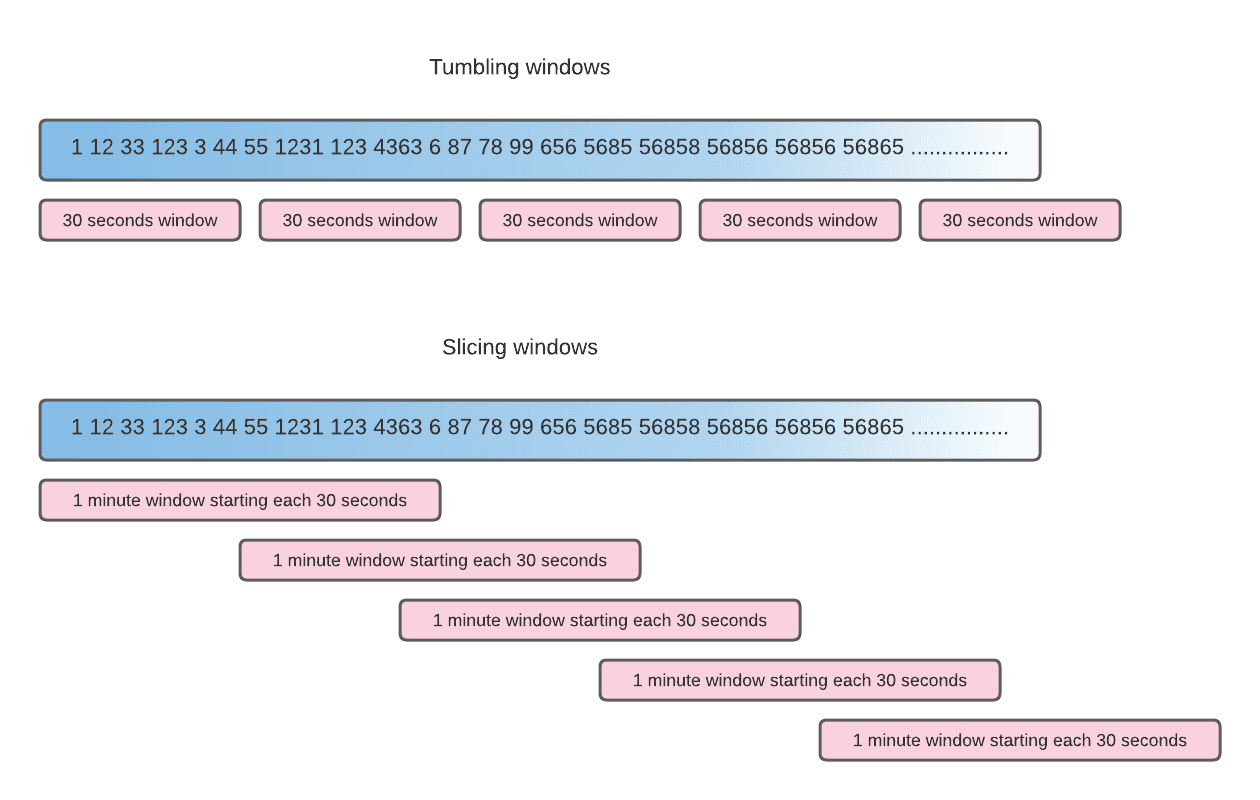
Windows là một khái niệm quan trọng trong Kafka, khi xử lý một luồng dữ liệu liên tục và vô tận thì kafka sẽ chia luồng dữ liệu đó thành những windows với một kích thước nhất định nào đó rồi sau đó sẽ thực hiện tính toán trên những windows đó. Có nhiều cách để thực hiện chia luồng dữ liệu thành các windows, hình minh họa cho thấy 2 cách thực hiện đó là - tumbling và slicing windows
Streaming data pipeline implementation
Luồng dữ liệu chúng ta sẽ build mô phỏng dữ liệu giao thông lấy từ camera quan sát. Một consumer service sẽ tiếp nhận dữ liệu đó in ra kết quả có bao nhiêu loại phương tiện giao thông trong một khoảng thời gian nhất định.
The producer microservice
Trước tiên bạn cần setup Kafka trên máy local. Sau khi setup thành công, chúng ta tạo một ứng dụng Java hoạt động như một Producer. Chúng ta sử dụng Spring Boot và do đó không cần cấu hình gì để có thể sử dụng Kafka, chỉ cần thêm các dependencies là đủ rồi.
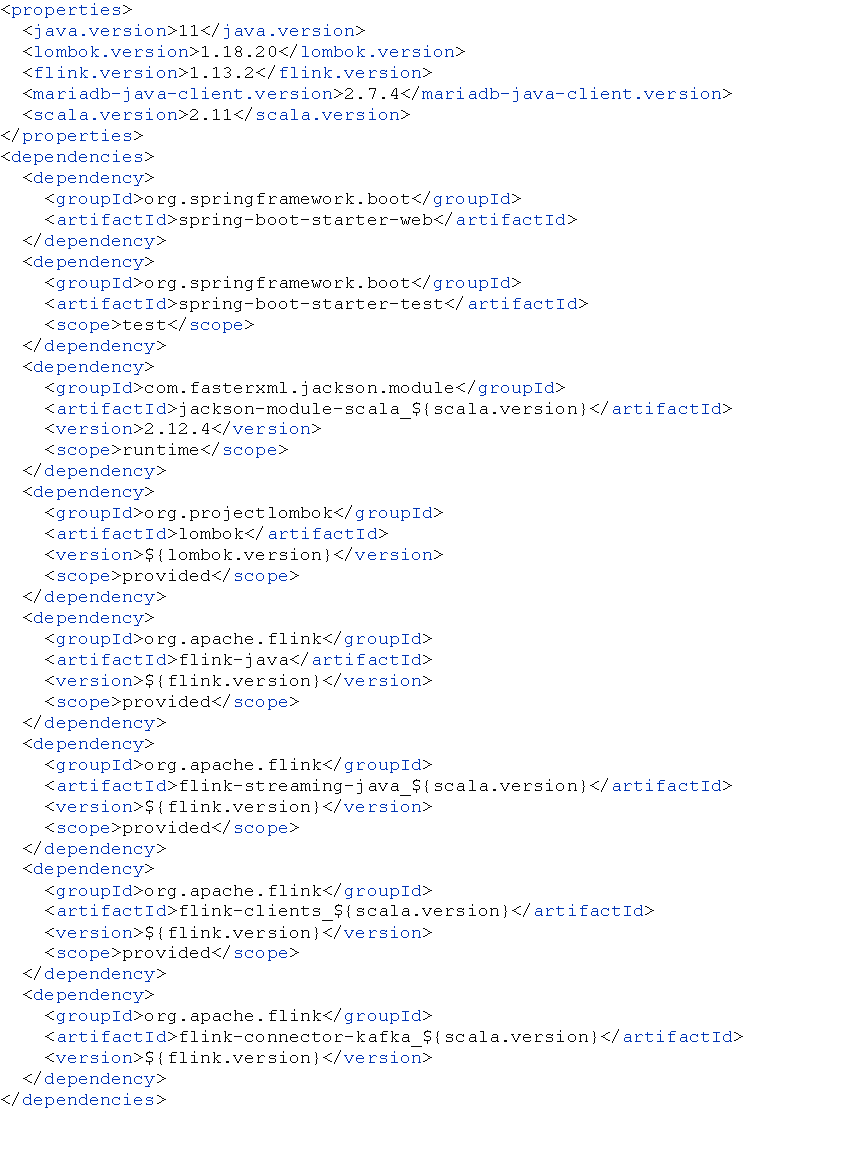
Figure 1: Maven dependencies

Figure 2: application.yml

Mẫu tin nhắn là một lớp POJO đơn giản
Figure 3: Vehicle

Figure 4: VehicleType

Producer sẽ tạo ra ngẫu nhiên các dòng dữ liệu liên tục, ở đây là các phương tiên giao thông khác nhau. Để tạo ra các tin nhắn trong Kafka chỉ cần inject bean KafkaTemplate

Khi chúng ta chạy ứng dụng Spring Boot, ứng dụng sẽ gửi các tin nhắn loại phương tiện giao thông đến topic "vehicle-topic" trong local cluster trên máy chúng ta.
The Data Processor Service
Figure 6: Maven Dependencies
Ngoài model chúng ta sẽ tạo để ánh xạ với model từ Producer, chúng ta sẽ tạo thêm 1 model dùng để lưu trữ kết quả của quá trình tính toán.

Figure 7: VehicleDeserializationSchema

Figure 8: VehicleStatisticsSerializationSchema

Đoạn code triển khai Flink trong lớp ProcessingService
@Service
@Log4j2
@RequiredArgsConstructor
public class ProcessingService { @Value("${kafka.bootstrap-servers}") private String kafkaAddress; @Value("${kafka.group-id}") private String kafkaGroupId; public static final String TOPIC = "vehicle-topic"; public static final String VEHICLE_STATISTICS_TOPIC = "vehicle-statistics-topic"; private final VehicleDeserializationSchema vehicleDeserializationSchema; private final VehicleStatisticsSerializationSchema vehicleStatisticsSerializationSchema; @PostConstruct public void startFlinkStreamProcessing() { try { processVehicleStatistic(); } catch (Exception e) { log.error("Cannot process", e); } } public void processVehicleStatistic() throws Exception { StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment(); FlinkKafkaConsumer<Vehicle> consumer = createVehicleConsumerForTopic(TOPIC, kafkaAddress, kafkaGroupId); consumer.setStartFromLatest(); consumer.assignTimestampsAndWatermarks(WatermarkStrategy.forMonotonousTimestamps()); FlinkKafkaProducer<VehicleStatistics> producer = createVehicleStatisticsProducer(VEHICLE_STATISTICS_TOPIC, kafkaAddress); DataStream<Vehicle> inputMessagesStream = environment.addSource(consumer); inputMessagesStream .keyBy((vehicle -> vehicle.getVehicleType().ordinal())) .window(TumblingEventTimeWindows.of(Time.seconds(20))) .aggregate(new VehicleStatisticsAggregator()) .addSink(producer); environment.execute(); } private FlinkKafkaConsumer<Vehicle> createVehicleConsumerForTopic(String topic, String kafkaAddress, String kafkaGroup ) { Properties properties = new Properties(); properties.setProperty("bootstrap.servers", kafkaAddress); properties.setProperty("group.id", kafkaGroup); return new FlinkKafkaConsumer<>(topic, vehicleDeserializationSchema, properties); } private FlinkKafkaProducer<VehicleStatistics> createVehicleStatisticsProducer(String topic, String kafkaAddress){ return new FlinkKafkaProducer<>(kafkaAddress, topic, vehicleStatisticsSerializationSchema); }
}<div class="open_grepper_editor" title="Edit & Save To Grepper"></div>
Các hàm createVehicleConsumerForTopic và createVehicleStatisticsProducer tạo ra Flink consumer và producer. Các producer có thể được gọi là sink và consumer được gọi là source. Tất cả các ứng dụng Flink phải được trên StreamExecutionEnvironment
Figure 9: Flink Data Stream Processing
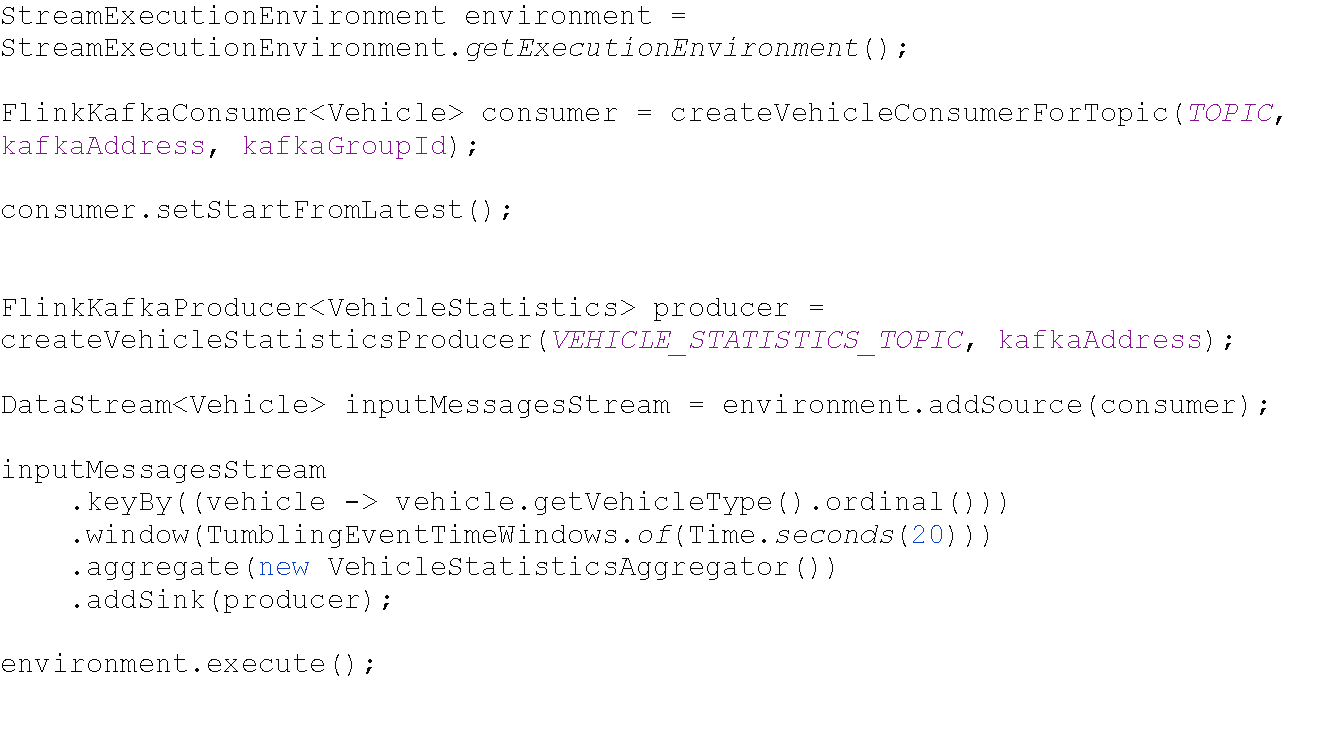
Luồng dữ liệu đầu vào được lấy từ vehicle-topic, xử lý thông qua một AggregateFunction, cuối cùng chúng ta addSink, nhập dữ liệu đó vào một topic khác. Cách lấy source và ghi vào sink được cung cấp bới Flink thông qua một thứ gọi là connectors. Dưới đây là một số connectors phổ biến của Flink với các hệ thống khác nhau:
- Apache Kafka (source/sink)
- Apache Cassandra (sink)
- Amazon Kinesis Streams (source/sink)
- Elasticsearch (sink)
- FileSystem (Hadoop included) – Streaming only (sink)
- FileSystem (Hadoop included) – Streaming and Batch (sink)
- RabbitMQ (source/sink)
- Apache NiFi (source/sink)
- Twitter Streaming API (source)
- Google PubSub (source/sink)
- JDBC (sink)
Kết bài
Chúng ta đã tạo một đường luồng dữ liệu đơn giản để sản xuất, tiêu thụ và xử lý dữ liệu phát trực tuyến vô tận bằng Apache Kafka và Apache Flink. Chúng ta đã trình bày những vấn đề sau: Hiểu biết chung về dữ liệu truyền trực tuyến.
- Giới thiệu về Apache Kafka và cách sử dụng nó liên quan đến xử lý dữ liệu trực tuyến.
- Giới thiệu về Apache Flink và các tính toán dữ liệu phát trực tuyến trạng thái của nó.
- Hiểu cách Flink có thể được tích hợp với Kafka và sử dụng nó như bộ nguồn và bộ ghi.